 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulating Dynamic Tumor Contrast Enhancement in Breast MRI using Conditional Generative Adversarial Networks
Sep 27, 2024This paper presents a method for virtual contrast enhancement in breast MRI, offering a promising non-invasive alternative to traditional contrast agent-based DCE-MRI acquisition. Using a conditional generative adversarial network, we predict DCE-MRI images, including jointly-generated sequences of multiple corresponding DCE-MRI timepoints, from non-contrast-enhanced MRIs, enabling tumor localization and characterization without the associated health risks. Furthermore, we qualitatively and quantitatively evaluate the synthetic DCE-MRI images, proposing a multi-metric Scaled Aggregate Measure (SAMe), assessing their utility in a tumor segmentation downstream task, and conclude with an analysis of the temporal patterns in multi-sequence DCE-MRI generation. Our approach demonstrates promising results in generating realistic and useful DCE-MRI sequences, highlighting the potential of virtual contrast enhancement for improving breast cancer diagnosis and treatment, particularly for patients where contrast agent administration is contraindicated.
MAMA-MIA: A Large-Scale Multi-Center Breast Cancer DCE-MRI Benchmark Dataset with Expert Segmentations
Jun 19, 2024Current research in breast cancer Magnetic Resonance Imaging (MRI), especially with Artificial Intelligence (AI), faces challenges due to the lack of expert segmentations. To address this, we introduce the MAMA-MIA dataset, comprising 1506 multi-center dynamic contrast-enhanced MRI cases with expert segmentations of primary tumors and non-mass enhancement areas. These cases were sourced from four publicly available collections in The Cancer Imaging Archive (TCIA). Initially, we trained a deep learning model to automatically segment the cases, generating preliminary segmentations that significantly reduced expert segmentation time. Sixteen experts, averaging 9 years of experience in breast cancer, then corrected these segmentations, resulting in the final expert segmentations. Additionally, two radiologists conducted a visual inspection of the automatic segmentations to support future quality control studies. Alongside the expert segmentations, we provide 49 harmonized demographic and clinical variables and the pretrained weights of the well-known nnUNet architecture trained using the DCE-MRI full-images and expert segmentations. This dataset aims to accelerate the development and benchmarking of deep learning models and foster innovation in breast cancer diagnostics and treatment planning.
Towards Learning Contrast Kinetics with Multi-Condition Latent Diffusion Models
Mar 20, 2024



Contrast agents in dynamic contrast enhanced magnetic resonance imaging allow to localize tumors and observe their contrast kinetics, which is essential for cancer characterization and respective treatment decision-making. However, contrast agent administration is not only associated with adverse health risks, but also restricted for patients during pregnancy, and for those with kidney malfunction, or other adverse reactions. With contrast uptake as key biomarker for lesion malignancy, cancer recurrence risk, and treatment response, it becomes pivotal to reduce the dependency on intravenous contrast agent administration. To this end, we propose a multi-conditional latent diffusion model capable of acquisition time-conditioned image synthesis of DCE-MRI temporal sequences. To evaluate medical image synthesis, we additionally propose and validate the Fr\'echet radiomics distance as an image quality measure based on biomarker variability between synthetic and real imaging data. Our results demonstrate our method's ability to generate realistic multi-sequence fat-saturated breast DCE-MRI and uncover the emerging potential of deep learning based contrast kinetics simulation. We publicly share our accessible codebase at https://github.com/RichardObi/ccnet.
Pre- to Post-Contrast Breast MRI Synthesis for Enhanced Tumour Segmentation
Nov 17, 2023Despite its benefits for tumour detection and treatment, the administration of contrast agents in dynamic contrast-enhanced MRI (DCE-MRI) is associated with a range of issues, including their invasiveness, bioaccumulation, and a risk of nephrogenic systemic fibrosis. This study explores the feasibility of producing synthetic contrast enhancements by translating pre-contrast T1-weighted fat-saturated breast MRI to their corresponding first DCE-MRI sequence leveraging the capabilities of a generative adversarial network (GAN). Additionally, we introduce a Scaled Aggregate Measure (SAMe) designed for quantitatively evaluating the quality of synthetic data in a principled manner and serving as a basis for selecting the optimal generative model. We assess the generated DCE-MRI data using quantitative image quality metrics and apply them to the downstream task of 3D breast tumour segmentation. Our results highlight the potential of post-contrast DCE-MRI synthesis in enhancing the robustness of breast tumour segmentation models via data augmentation. Our code is available at https://github.com/RichardObi/pre_post_synthesis.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
medigan: A Python Library of Pretrained Generative Models for Enriched Data Access in Medical Imaging
Sep 28, 2022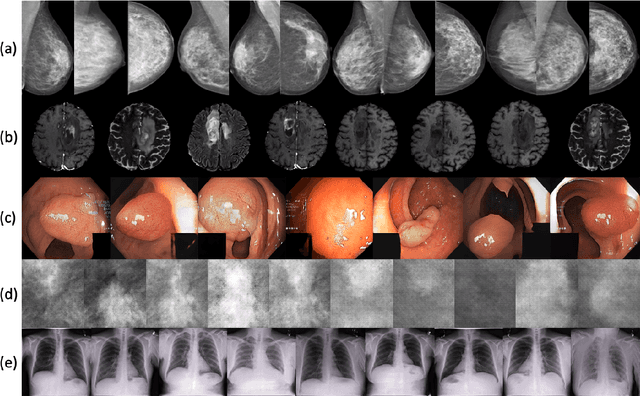
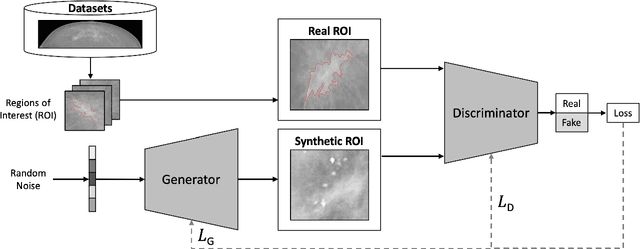
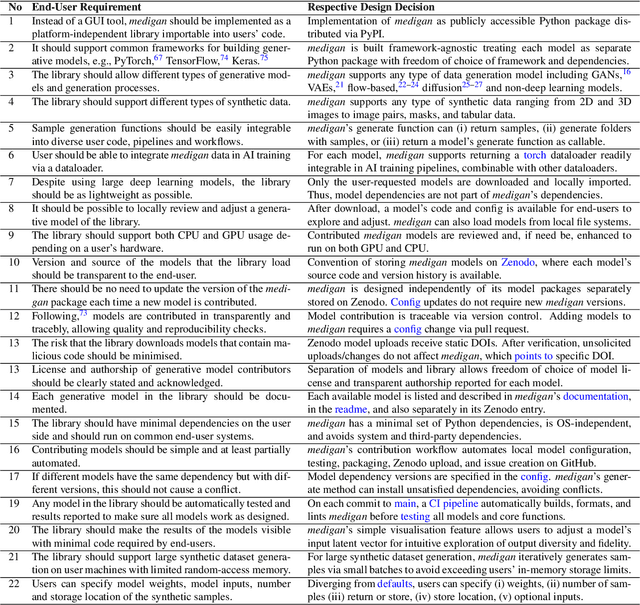
Synthetic data generated by generative models can enhance the performance and capabilities of data-hungry deep learning models in medical imaging. However, there is (1) limited availability of (synthetic) datasets and (2) generative models are complex to train, which hinders their adoption in research and clinical applications. To reduce this entry barrier, we propose medigan, a one-stop shop for pretrained generative models implemented as an open-source framework-agnostic Python library. medigan allows researchers and developers to create, increase, and domain-adapt their training data in just a few lines of code. Guided by design decisions based on gathered end-user requirements, we implement medigan based on modular components for generative model (i) execution, (ii) visualisation, (iii) search & ranking, and (iv) contribution. The library's scalability and design is demonstrated by its growing number of integrated and readily-usable pretrained generative models consisting of 21 models utilising 9 different Generative Adversarial Network architectures trained on 11 datasets from 4 domains, namely, mammography, endoscopy, x-ray, and MRI. Furthermore, 3 applications of medigan are analysed in this work, which include (a) enabling community-wide sharing of restricted data, (b) investigating generative model evaluation metrics, and (c) improving clinical downstream tasks. In (b), extending on common medical image synthesis assessment and reporting standards, we show Fr\'echet Inception Distance variability based on image normalisation and radiology-specific feature extraction.
CrossMoDA 2021 challenge: Benchmark of Cross-Modality Domain Adaptation techniques for Vestibular Schwnannoma and Cochlea Segmentation
Jan 08, 2022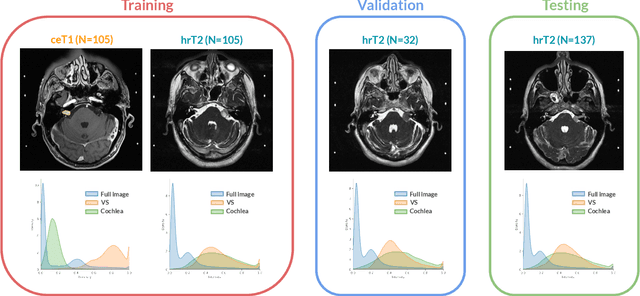
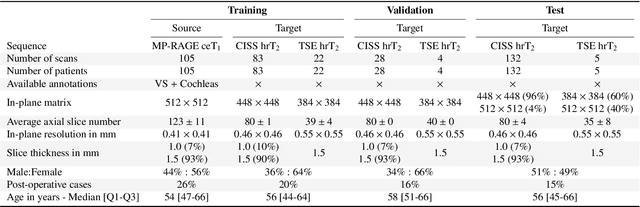
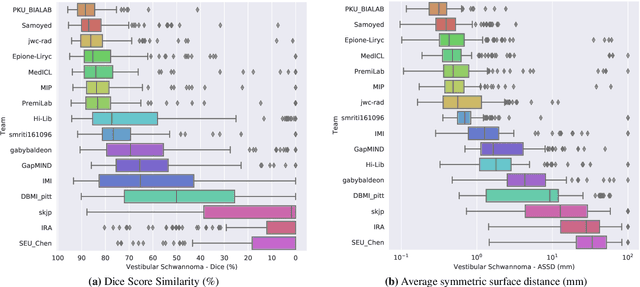
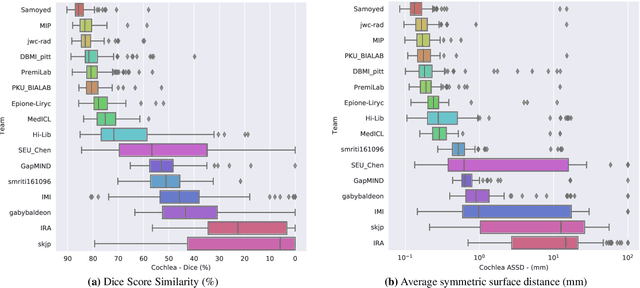
Domain Adaptation (DA) has recently raised strong interests in the medical imaging community. While a large variety of DA techniques has been proposed for image segmentation, most of these techniques have been validated either on private datasets or on small publicly available datasets. Moreover, these datasets mostly addressed single-class problems. To tackle these limitations, the Cross-Modality Domain Adaptation (crossMoDA) challenge was organised in conjunction with the 24th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2021). CrossMoDA is the first large and multi-class benchmark for unsupervised cross-modality DA. The challenge's goal is to segment two key brain structures involved in the follow-up and treatment planning of vestibular schwannoma (VS): the VS and the cochleas. Currently, the diagnosis and surveillance in patients with VS are performed using contrast-enhanced T1 (ceT1) MRI. However, there is growing interest in using non-contrast sequences such as high-resolution T2 (hrT2) MRI. Therefore, we created an unsupervised cross-modality segmentation benchmark. The training set provides annotated ceT1 (N=105) and unpaired non-annotated hrT2 (N=105). The aim was to automatically perform unilateral VS and bilateral cochlea segmentation on hrT2 as provided in the testing set (N=137). A total of 16 teams submitted their algorithm for the evaluation phase. The level of performance reached by the top-performing teams is strikingly high (best median Dice - VS:88.4%; Cochleas:85.7%) and close to full supervision (median Dice - VS:92.5%; Cochleas:87.7%). All top-performing methods made use of an image-to-image translation approach to transform the source-domain images into pseudo-target-domain images. A segmentation network was then trained using these generated images and the manual annotations provided for the source image.