 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Large-Scale Face Datasets for Deep Periocular Recognition via Ocular Cropping
Oct 30, 2025We focus on ocular biometrics, specifically the periocular region (the area around the eye), which offers high discrimination and minimal acquisition constraints. We evaluate three Convolutional Neural Network architectures of varying depth and complexity to assess their effectiveness for periocular recognition. The networks are trained on 1,907,572 ocular crops extracted from the large-scale VGGFace2 database. This significantly contrasts with existing works, which typically rely on small-scale periocular datasets for training having only a few thousand images. Experiments are conducted with ocular images from VGGFace2-Pose, a subset of VGGFace2 containing in-the-wild face images, and the UFPR-Periocular database, which consists of selfies captured via mobile devices with user guidance on the screen. Due to the uncontrolled conditions of VGGFace2, the Equal Error Rates (EERs) obtained with ocular crops range from 9-15%, noticeably higher than the 3-6% EERs achieved using full-face images. In contrast, UFPR-Periocular yields significantly better performance (EERs of 1-2%), thanks to higher image quality and more consistent acquisition protocols. To the best of our knowledge, these are the lowest reported EERs on the UFPR dataset to date.
Exploring Complementarity and Explainability in CNNs for Periocular Verification Across Acquisition Distances
Oct 30, 2025We study the complementarity of different CNNs for periocular verification at different distances on the UBIPr database. We train three architectures of increasing complexity (SqueezeNet, MobileNetv2, and ResNet50) on a large set of eye crops from VGGFace2. We analyse performance with cosine and chi2 metrics, compare different network initialisations, and apply score-level fusion via logistic regression. In addition, we use LIME heatmaps and Jensen-Shannon divergence to compare attention patterns of the CNNs. While ResNet50 consistently performs best individually, the fusion provides substantial gains, especially when combining all three networks. Heatmaps show that networks usually focus on distinct regions of a given image, which explains their complementarity. Our method significantly outperforms previous works on UBIPr, achieving a new state-of-the-art.
Combined CNN and ViT features off-the-shelf: Another astounding baseline for recognition
Jul 28, 2024



We apply pre-trained architectures, originally developed for the ImageNet Large Scale Visual Recognition Challenge, for periocular recognition. These architectures have demonstrated significant success in various computer vision tasks beyond the ones for which they were designed. This work builds on our previous study using off-the-shelf Convolutional Neural Network (CNN) and extends it to include the more recently proposed Vision Transformers (ViT). Despite being trained for generic object classification, middle-layer features from CNNs and ViTs are a suitable way to recognize individuals based on periocular images. We also demonstrate that CNNs and ViTs are highly complementary since their combination results in boosted accuracy. In addition, we show that a small portion of these pre-trained models can achieve good accuracy, resulting in thinner models with fewer parameters, suitable for resource-limited environments such as mobiles. This efficiency improves if traditional handcrafted features are added as well.
Deep Network Pruning: A Comparative Study on CNNs in Face Recognition
May 28, 2024The widespread use of mobile devices for all kind of transactions makes necessary reliable and real-time identity authentication, leading to the adoption of face recognition (FR) via the cameras embedded in such devices. Progress of deep Convolutional Neural Networks (CNNs) has provided substantial advances in FR. Nonetheless, the size of state-of-the-art architectures is unsuitable for mobile deployment, since they often encompass hundreds of megabytes and millions of parameters. We address this by studying methods for deep network compression applied to FR. In particular, we apply network pruning based on Taylor scores, where less important filters are removed iteratively. The method is tested on three networks based on the small SqueezeNet (1.24M parameters) and the popular MobileNetv2 (3.5M) and ResNet50 (23.5M) architectures. These have been selected to showcase the method on CNNs with different complexities and sizes. We observe that a substantial percentage of filters can be removed with minimal performance loss. Also, filters with the highest amount of output channels tend to be removed first, suggesting that high-dimensional spaces within popular CNNs are over-dimensionated.
Understanding and Improving CNNs with Complex Structure Tensor: A Biometrics Study
Apr 24, 2024



Our study provides evidence that CNNs struggle to effectively extract orientation features. We show that the use of Complex Structure Tensor, which contains compact orientation features with certainties, as input to CNNs consistently improves identification accuracy compared to using grayscale inputs alone. Experiments also demonstrated that our inputs, which were provided by mini complex conv-nets, combined with reduced CNN sizes, outperformed full-fledged, prevailing CNN architectures. This suggests that the upfront use of orientation features in CNNs, a strategy seen in mammalian vision, not only mitigates their limitations but also enhances their explainability and relevance to thin-clients. Experiments were done on publicly available data sets comprising periocular images for biometric identification and verification (Close and Open World) using 6 State of the Art CNN architectures. We reduced SOA Equal Error Rate (EER) on the PolyU dataset by 5-26% depending on data and scenario.
Keypoint Description by Symmetry Assessment -- Applications in Biometrics
Nov 03, 2023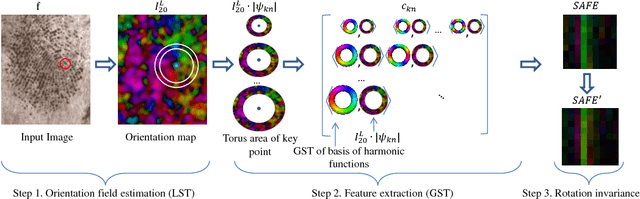


We present a model-based feature extractor to describe neighborhoods around keypoints by finite expansion, estimating the spatially varying orientation by harmonic functions. The iso-curves of such functions are highly symmetric w.r.t. the origin (a keypoint) and the estimated parameters have well defined geometric interpretations. The origin is also a unique singularity of all harmonic functions, helping to determine the location of a keypoint precisely, whereas the functions describe the object shape of the neighborhood. This is novel and complementary to traditional texture features which describe texture-shape properties i.e. they are purposively invariant to translation (within a texture). We report on experiments of verification and identification of keypoints in forensic fingerprints by using publicly available data (NIST SD27) and discuss the results in comparison to other studies. These support our conclusions that the novel features can equip single cores or single minutia with a significant verification power at 19% EER, and an identification power of 24-78% for ranks of 1-20. Additionally, we report verification results of periocular biometrics using near-infrared images, reaching an EER performance of 13%, which is comparable to the state of the art. More importantly, fusion of two systems, our and texture features (Gabor), result in a measurable performance improvement. We report reduction of the EER to 9%, supporting the view that the novel features capture relevant visual information, which traditional texture features do not.
Log-Likelihood Score Level Fusion for Improved Cross-Sensor Smartphone Periocular Recognition
Nov 02, 2023The proliferation of cameras and personal devices results in a wide variability of imaging conditions, producing large intra-class variations and a significant performance drop when images from heterogeneous environments are compared. However, many applications require to deal with data from different sources regularly, thus needing to overcome these interoperability problems. Here, we employ fusion of several comparators to improve periocular performance when images from different smartphones are compared. We use a probabilistic fusion framework based on linear logistic regression, in which fused scores tend to be log-likelihood ratios, obtaining a reduction in cross-sensor EER of up to 40% due to the fusion. Our framework also provides an elegant and simple solution to handle signals from different devices, since same-sensor and cross-sensor score distributions are aligned and mapped to a common probabilistic domain. This allows the use of Bayes thresholds for optimal decision-making, eliminating the need of sensor-specific thresholds, which is essential in operational conditions because the threshold setting critically determines the accuracy of the authentication process in many applications.
EFaR 2023: Efficient Face Recognition Competition
Aug 08, 2023



This paper presents the summary of the Efficient Face Recognition Competition (EFaR) held at the 2023 International Joint Conference on Biometrics (IJCB 2023). The competition received 17 submissions from 6 different teams. To drive further development of efficient face recognition models, the submitted solutions are ranked based on a weighted score of the achieved verification accuracies on a diverse set of benchmarks, as well as the deployability given by the number of floating-point operations and model size. The evaluation of submissions is extended to bias, cross-quality, and large-scale recognition benchmarks. Overall, the paper gives an overview of the achieved performance values of the submitted solutions as well as a diverse set of baselines. The submitted solutions use small, efficient network architectures to reduce the computational cost, some solutions apply model quantization. An outlook on possible techniques that are underrepresented in current solutions is given as well.
Periocular biometrics: databases, algorithms and directions
Jul 26, 2023



Periocular biometrics has been established as an independent modality due to concerns on the performance of iris or face systems in uncontrolled conditions. Periocular refers to the facial region in the eye vicinity, including eyelids, lashes and eyebrows. It is available over a wide range of acquisition distances, representing a trade-off between the whole face (which can be occluded at close distances) and the iris texture (which do not have enough resolution at long distances). Since the periocular region appears in face or iris images, it can be used also in conjunction with these modalities. Features extracted from the periocular region have been also used successfully for gender classification and ethnicity classification, and to study the impact of gender transformation or plastic surgery in the recognition performance. This paper presents a review of the state of the art in periocular biometric research, providing an insight of the most relevant issues and giving a thorough coverage of the existing literature. Future research trends are also briefly discussed.
An Explainable Model-Agnostic Algorithm for CNN-based Biometrics Verification
Jul 25, 2023



This paper describes an adaptation of the Local Interpretable Model-Agnostic Explanations (LIME) AI method to operate under a biometric verification setting. LIME was initially proposed for networks with the same output classes used for training, and it employs the softmax probability to determine which regions of the image contribute the most to classification. However, in a verification setting, the classes to be recognized have not been seen during training. In addition, instead of using the softmax output, face descriptors are usually obtained from a layer before the classification layer. The model is adapted to achieve explainability via cosine similarity between feature vectors of perturbated versions of the input image. The method is showcased for face biometrics with two CNN models based on MobileNetv2 and ResNet50.