 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Memory Design in SAM-Based Visual Object Tracking
Dec 27, 2025\noindent Memory has become the central mechanism enabling robust visual object tracking in modern segmentation-based frameworks. Recent methods built upon Segment Anything Model 2 (SAM2) have demonstrated strong performance by refining how past observations are stored and reused. However, existing approaches address memory limitations in a method-specific manner, leaving the broader design principles of memory in SAM-based tracking poorly understood. Moreover, it remains unclear how these memory mechanisms transfer to stronger, next-generation foundation models such as Segment Anything Model 3 (SAM3). In this work, we present a systematic memory-centric study of SAM-based visual object tracking. We first analyze representative SAM2-based trackers and show that most methods primarily differ in how short-term memory frames are selected, while sharing a common object-centric representation. Building on this insight, we faithfully reimplement these memory mechanisms within the SAM3 framework and conduct large-scale evaluations across ten diverse benchmarks, enabling a controlled analysis of memory design independent of backbone strength. Guided by our empirical findings, we propose a unified hybrid memory framework that explicitly decomposes memory into short-term appearance memory and long-term distractor-resolving memory. This decomposition enables the integration of existing memory policies in a modular and principled manner. Extensive experiments demonstrate that the proposed framework consistently improves robustness under long-term occlusion, complex motion, and distractor-heavy scenarios on both SAM2 and SAM3 backbones. Code is available at: https://github.com/HamadYA/SAM3_Tracking_Zoo. \textbf{This is a preprint. Some results are being finalized and may be updated in a future revision.}
Cytoplasmic Strings Analysis in Human Embryo Time-Lapse Videos using Deep Learning Framework
Dec 10, 2025Infertility is a major global health issue, and while in-vitro fertilization has improved treatment outcomes, embryo selection remains a critical bottleneck. Time-lapse imaging enables continuous, non-invasive monitoring of embryo development, yet most automated assessment methods rely solely on conventional morphokinetic features and overlook emerging biomarkers. Cytoplasmic Strings, thin filamentous structures connecting the inner cell mass and trophectoderm in expanded blastocysts, have been associated with faster blastocyst formation, higher blastocyst grades, and improved viability. However, CS assessment currently depends on manual visual inspection, which is labor-intensive, subjective, and severely affected by detection and subtle visual appearance. In this work, we present, to the best of our knowledge, the first computational framework for CS analysis in human IVF embryos. We first design a human-in-the-loop annotation pipeline to curate a biologically validated CS dataset from TLI videos, comprising 13,568 frames with highly sparse CS-positive instances. Building on this dataset, we propose a two-stage deep learning framework that (i) classifies CS presence at the frame level and (ii) localizes CS regions in positive cases. To address severe imbalance and feature uncertainty, we introduce the Novel Uncertainty-aware Contractive Embedding (NUCE) loss, which couples confidence-aware reweighting with an embedding contraction term to form compact, well-separated class clusters. NUCE consistently improves F1-score across five transformer backbones, while RF-DETR-based localization achieves state-of-the-art (SOTA) detection performance for thin, low-contrast CS structures. The source code will be made publicly available at: https://github.com/HamadYA/CS_Detection.
Towards Accurate State Estimation: Kalman Filter Incorporating Motion Dynamics for 3D Multi-Object Tracking
May 12, 2025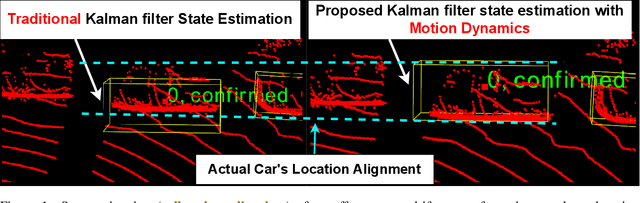
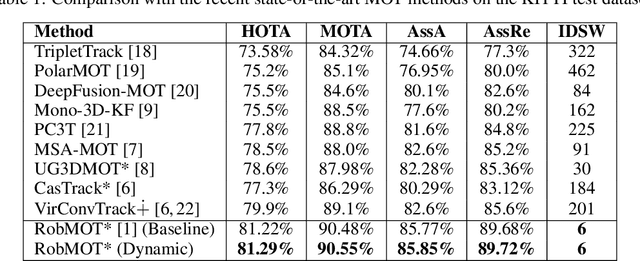
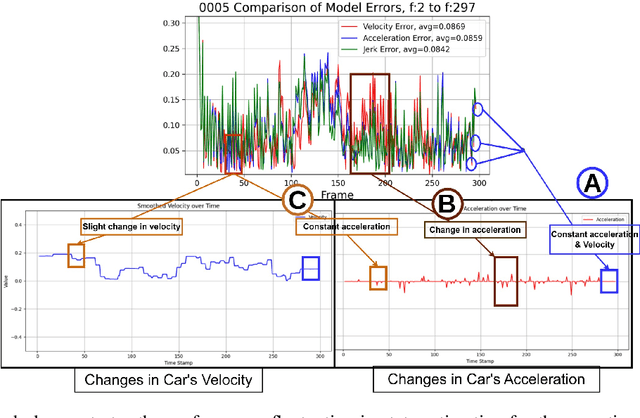
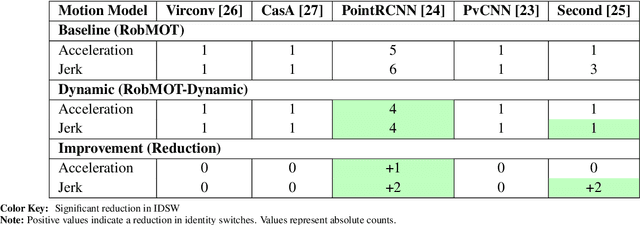
This work addresses the critical lack of precision in state estimation in the Kalman filter for 3D multi-object tracking (MOT) and the ongoing challenge of selecting the appropriate motion model. Existing literature commonly relies on constant motion models for estimating the states of objects, neglecting the complex motion dynamics unique to each object. Consequently, trajectory division and imprecise object localization arise, especially under occlusion conditions. The core of these challenges lies in the limitations of the current Kalman filter formulation, which fails to account for the variability of motion dynamics as objects navigate their environments. This work introduces a novel formulation of the Kalman filter that incorporates motion dynamics, allowing the motion model to adaptively adjust according to changes in the object's movement. The proposed Kalman filter substantially improves state estimation, localization, and trajectory prediction compared to the traditional Kalman filter. This is reflected in tracking performance that surpasses recent benchmarks on the KITTI and Waymo Open Datasets, with margins of 0.56\% and 0.81\% in higher order tracking accuracy (HOTA) and multi-object tracking accuracy (MOTA), respectively. Furthermore, the proposed Kalman filter consistently outperforms the baseline across various detectors. Additionally, it shows an enhanced capability in managing long occlusions compared to the baseline Kalman filter, achieving margins of 1.22\% in higher order tracking accuracy (HOTA) and 1.55\% in multi-object tracking accuracy (MOTA) on the KITTI dataset. The formulation's efficiency is evident, with an additional processing time of only approximately 0.078 ms per frame, ensuring its applicability in real-time applications.
Multi-Resolution Pathology-Language Pre-training Model with Text-Guided Visual Representation
Apr 26, 2025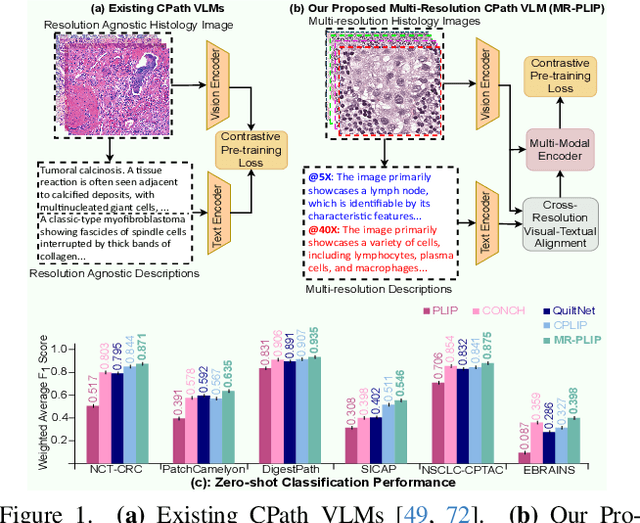
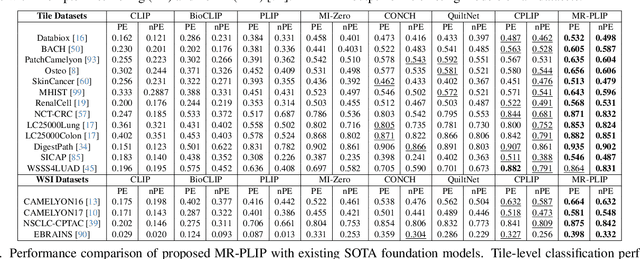
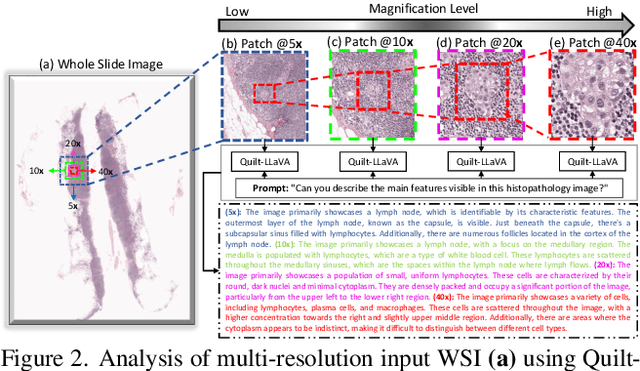
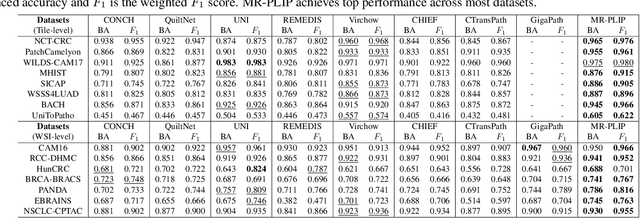
In Computational Pathology (CPath), the introduction of Vision-Language Models (VLMs) has opened new avenues for research, focusing primarily on aligning image-text pairs at a single magnification level. However, this approach might not be sufficient for tasks like cancer subtype classification, tissue phenotyping, and survival analysis due to the limited level of detail that a single-resolution image can provide. Addressing this, we propose a novel multi-resolution paradigm leveraging Whole Slide Images (WSIs) to extract histology patches at multiple resolutions and generate corresponding textual descriptions through advanced CPath VLM. We introduce visual-textual alignment at multiple resolutions as well as cross-resolution alignment to establish more effective text-guided visual representations. Cross-resolution alignment using a multimodal encoder enhances the model's ability to capture context from multiple resolutions in histology images. Our model aims to capture a broader range of information, supported by novel loss functions, enriches feature representation, improves discriminative ability, and enhances generalization across different resolutions. Pre-trained on a comprehensive TCGA dataset with 34 million image-language pairs at various resolutions, our fine-tuned model outperforms state-of-the-art (SOTA) counterparts across multiple datasets and tasks, demonstrating its effectiveness in CPath. The code is available on GitHub at: https://github.com/BasitAlawode/MR-PLIP
DyCON: Dynamic Uncertainty-aware Consistency and Contrastive Learning for Semi-supervised Medical Image Segmentation
Apr 06, 2025Semi-supervised learning in medical image segmentation leverages unlabeled data to reduce annotation burdens through consistency learning. However, current methods struggle with class imbalance and high uncertainty from pathology variations, leading to inaccurate segmentation in 3D medical images. To address these challenges, we present DyCON, a Dynamic Uncertainty-aware Consistency and Contrastive Learning framework that enhances the generalization of consistency methods with two complementary losses: Uncertainty-aware Consistency Loss (UnCL) and Focal Entropy-aware Contrastive Loss (FeCL). UnCL enforces global consistency by dynamically weighting the contribution of each voxel to the consistency loss based on its uncertainty, preserving high-uncertainty regions instead of filtering them out. Initially, UnCL prioritizes learning from uncertain voxels with lower penalties, encouraging the model to explore challenging regions. As training progress, the penalty shift towards confident voxels to refine predictions and ensure global consistency. Meanwhile, FeCL enhances local feature discrimination in imbalanced regions by introducing dual focal mechanisms and adaptive confidence adjustments into the contrastive principle. These mechanisms jointly prioritizes hard positives and negatives while focusing on uncertain sample pairs, effectively capturing subtle lesion variations under class imbalance. Extensive evaluations on four diverse medical image segmentation datasets (ISLES'22, BraTS'19, LA, Pancreas) show DyCON's superior performance against SOTA methods.
STING-BEE: Towards Vision-Language Model for Real-World X-ray Baggage Security Inspection
Apr 03, 2025Advancements in Computer-Aided Screening (CAS) systems are essential for improving the detection of security threats in X-ray baggage scans. However, current datasets are limited in representing real-world, sophisticated threats and concealment tactics, and existing approaches are constrained by a closed-set paradigm with predefined labels. To address these challenges, we introduce STCray, the first multimodal X-ray baggage security dataset, comprising 46,642 image-caption paired scans across 21 threat categories, generated using an X-ray scanner for airport security. STCray is meticulously developed with our specialized protocol that ensures domain-aware, coherent captions, that lead to the multi-modal instruction following data in X-ray baggage security. This allows us to train a domain-aware visual AI assistant named STING-BEE that supports a range of vision-language tasks, including scene comprehension, referring threat localization, visual grounding, and visual question answering (VQA), establishing novel baselines for multi-modal learning in X-ray baggage security. Further, STING-BEE shows state-of-the-art generalization in cross-domain settings. Code, data, and models are available at https://divs1159.github.io/STING-BEE/.
EMT: A Visual Multi-Task Benchmark Dataset for Autonomous Driving in the Arab Gulf Region
Feb 26, 2025

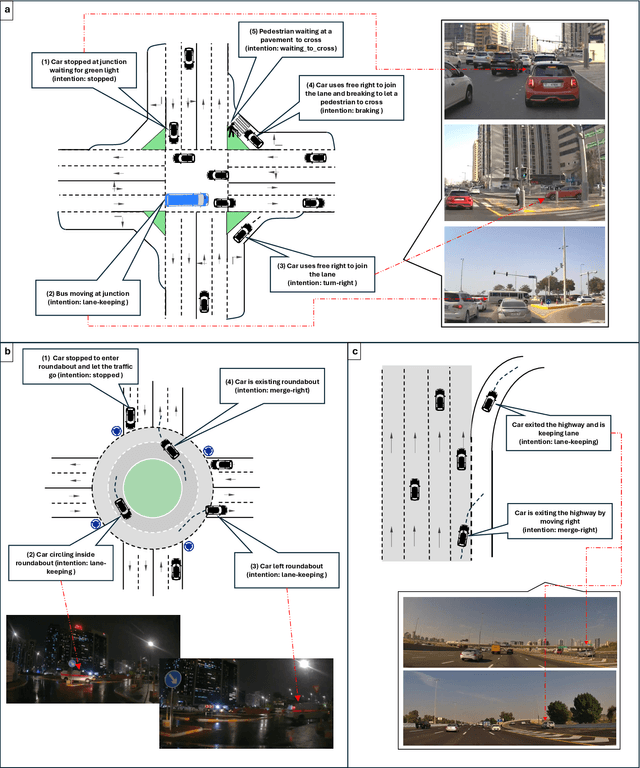

This paper introduces the Emirates Multi-Task (EMT) dataset - the first publicly available dataset for autonomous driving collected in the Arab Gulf region. The EMT dataset captures the unique road topology, high traffic congestion, and distinctive characteristics of the Gulf region, including variations in pedestrian clothing and weather conditions. It contains over 30,000 frames from a dash-camera perspective, along with 570,000 annotated bounding boxes, covering approximately 150 kilometers of driving routes. The EMT dataset supports three primary tasks: tracking, trajectory forecasting and intention prediction. Each benchmark dataset is complemented with corresponding evaluations: (1) multi-agent tracking experiments, focusing on multi-class scenarios and occlusion handling; (2) trajectory forecasting evaluation using deep sequential and interaction-aware models; and (3) intention benchmark experiments conducted for predicting agents intentions from observed trajectories. The dataset is publicly available at https://avlab.io/emt-dataset, and pre-processing scripts along with evaluation models can be accessed at https://github.com/AV-Lab/emt-dataset.
AquaticCLIP: A Vision-Language Foundation Model for Underwater Scene Analysis
Feb 03, 2025



The preservation of aquatic biodiversity is critical in mitigating the effects of climate change. Aquatic scene understanding plays a pivotal role in aiding marine scientists in their decision-making processes. In this paper, we introduce AquaticCLIP, a novel contrastive language-image pre-training model tailored for aquatic scene understanding. AquaticCLIP presents a new unsupervised learning framework that aligns images and texts in aquatic environments, enabling tasks such as segmentation, classification, detection, and object counting. By leveraging our large-scale underwater image-text paired dataset without the need for ground-truth annotations, our model enriches existing vision-language models in the aquatic domain. For this purpose, we construct a 2 million underwater image-text paired dataset using heterogeneous resources, including YouTube, Netflix, NatGeo, etc. To fine-tune AquaticCLIP, we propose a prompt-guided vision encoder that progressively aggregates patch features via learnable prompts, while a vision-guided mechanism enhances the language encoder by incorporating visual context. The model is optimized through a contrastive pretraining loss to align visual and textual modalities. AquaticCLIP achieves notable performance improvements in zero-shot settings across multiple underwater computer vision tasks, outperforming existing methods in both robustness and interpretability. Our model sets a new benchmark for vision-language applications in underwater environments. The code and dataset for AquaticCLIP are publicly available on GitHub at xxx.
Multi-Modal Attention Networks for Enhanced Segmentation and Depth Estimation of Subsurface Defects in Pulse Thermography
Jan 17, 2025



AI-driven pulse thermography (PT) has become a crucial tool in non-destructive testing (NDT), enabling automatic detection of hidden anomalies in various industrial components. Current state-of-the-art techniques feed segmentation and depth estimation networks compressed PT sequences using either Principal Component Analysis (PCA) or Thermographic Signal Reconstruction (TSR). However, treating these two modalities independently constrains the performance of PT inspection models as these representations possess complementary semantic features. To address this limitation, this work proposes PT-Fusion, a multi-modal attention-based fusion network that fuses both PCA and TSR modalities for defect segmentation and depth estimation of subsurface defects in PT setups. PT-Fusion introduces novel feature fusion modules, Encoder Attention Fusion Gate (EAFG) and Attention Enhanced Decoding Block (AEDB), to fuse PCA and TSR features for enhanced segmentation and depth estimation of subsurface defects. In addition, a novel data augmentation technique is proposed based on random data sampling from thermographic sequences to alleviate the scarcity of PT datasets. The proposed method is benchmarked against state-of-the-art PT inspection models, including U-Net, attention U-Net, and 3D-CNN on the Universit\'e Laval IRT-PVC dataset. The results demonstrate that PT-Fusion outperforms the aforementioned models in defect segmentation and depth estimation accuracies with a margin of 10%.
Reconstructing Deep Neural Networks: Unleashing the Optimization Potential of Natural Gradient Descent
Dec 10, 2024



Natural gradient descent (NGD) is a powerful optimization technique for machine learning, but the computational complexity of the inverse Fisher information matrix limits its application in training deep neural networks. To overcome this challenge, we propose a novel optimization method for training deep neural networks called structured natural gradient descent (SNGD). Theoretically, we demonstrate that optimizing the original network using NGD is equivalent to using fast gradient descent (GD) to optimize the reconstructed network with a structural transformation of the parameter matrix. Thereby, we decompose the calculation of the global Fisher information matrix into the efficient computation of local Fisher matrices via constructing local Fisher layers in the reconstructed network to speed up the training. Experimental results on various deep networks and datasets demonstrate that SNGD achieves faster convergence speed than NGD while retaining comparable solutions. Furthermore, our method outperforms traditional GDs in terms of efficiency and effectiveness. Thus, our proposed method has the potential to significantly improve the scalability and efficiency of NGD in deep learning applications. Our source code is available at https://github.com/Chaochao-Lin/SNGD.