 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing Deep Neural Networks: Unleashing the Optimization Potential of Natural Gradient Descent
Dec 10, 2024



Natural gradient descent (NGD) is a powerful optimization technique for machine learning, but the computational complexity of the inverse Fisher information matrix limits its application in training deep neural networks. To overcome this challenge, we propose a novel optimization method for training deep neural networks called structured natural gradient descent (SNGD). Theoretically, we demonstrate that optimizing the original network using NGD is equivalent to using fast gradient descent (GD) to optimize the reconstructed network with a structural transformation of the parameter matrix. Thereby, we decompose the calculation of the global Fisher information matrix into the efficient computation of local Fisher matrices via constructing local Fisher layers in the reconstructed network to speed up the training. Experimental results on various deep networks and datasets demonstrate that SNGD achieves faster convergence speed than NGD while retaining comparable solutions. Furthermore, our method outperforms traditional GDs in terms of efficiency and effectiveness. Thus, our proposed method has the potential to significantly improve the scalability and efficiency of NGD in deep learning applications. Our source code is available at https://github.com/Chaochao-Lin/SNGD.
Cross-domain Robust Deepfake Bias Expansion Network for Face Forgery Detection
Oct 08, 2023
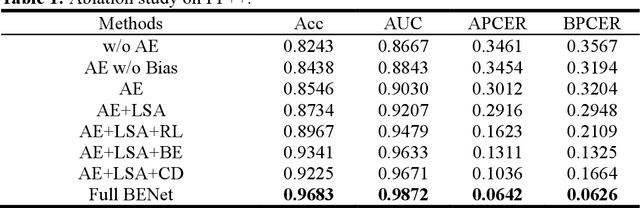
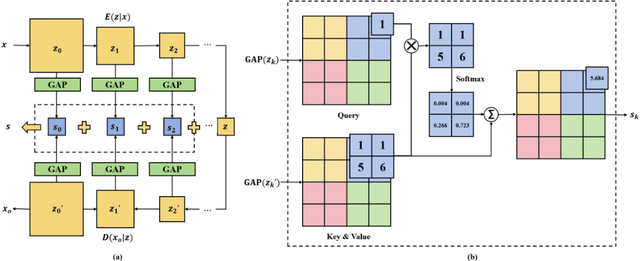
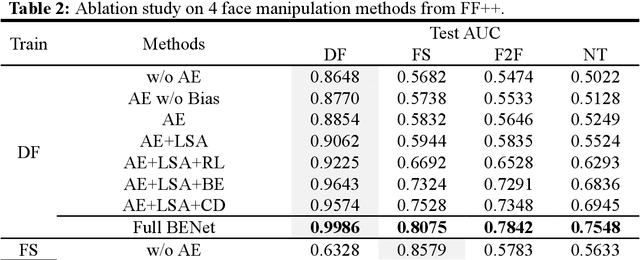
The rapid advancement of deepfake technologies raises significant concerns about the security of face recognition systems. While existing methods leverage the clues left by deepfake techniques for face forgery detection, malicious users may intentionally manipulate forged faces to obscure the traces of deepfake clues and thereby deceive detection tools. Meanwhile, attaining cross-domain robustness for data-based methods poses a challenge due to potential gaps in the training data, which may not encompass samples from all relevant domains. Therefore, in this paper, we introduce a solution - a Cross-Domain Robust Bias Expansion Network (BENet) - designed to enhance face forgery detection. BENet employs an auto-encoder to reconstruct input faces, maintaining the invariance of real faces while selectively enhancing the difference between reconstructed fake faces and their original counterparts. This enhanced bias forms a robust foundation upon which dependable forgery detection can be built. To optimize the reconstruction results in BENet, we employ a bias expansion loss infused with contrastive concepts to attain the aforementioned objective. In addition, to further heighten the amplification of forged clues, BENet incorporates a Latent-Space Attention (LSA) module. This LSA module effectively captures variances in latent features between the auto-encoder's encoder and decoder, placing emphasis on inconsistent forgery-related information. Furthermore, BENet incorporates a cross-domain detector with a threshold to determine whether the sample belongs to a known distribution. The correction of classification results through the cross-domain detector enables BENet to defend against unknown deepfake attacks from cross-domain. Extensive experiments demonstrate the superiority of BENet compared with state-of-the-art methods in intra-database and cross-database evaluations.
Dynamic Multi-Domain Knowledge Networks for Chest X-ray Report Generation
Oct 08, 2023The automated generation of radiology diagnostic reports helps radiologists make timely and accurate diagnostic decisions while also enhancing clinical diagnostic efficiency. However, the significant imbalance in the distribution of data between normal and abnormal samples (including visual and textual biases) poses significant challenges for a data-driven task like automatically generating diagnostic radiology reports. Therefore, we propose a Dynamic Multi-Domain Knowledge(DMDK) network for radiology diagnostic report generation. The DMDK network consists of four modules: Chest Feature Extractor(CFE), Dynamic Knowledge Extractor(DKE), Specific Knowledge Extractor(SKE), and Multi-knowledge Integrator(MKI) module. Specifically, the CFE module is primarily responsible for extracting the unprocessed visual medical features of the images. The DKE module is responsible for extracting dynamic disease topic labels from the retrieved radiology diagnostic reports. We then fuse the dynamic disease topic labels with the original visual features of the images to highlight the abnormal regions in the original visual features to alleviate the visual data bias problem. The SKE module expands upon the conventional static knowledge graph to mitigate textual data biases and amplify the interpretability capabilities of the model via domain-specific dynamic knowledge graphs. The MKI distills all the knowledge and generates the final diagnostic radiology report. We performed extensive experiments on two widely used datasets, IU X-Ray and MIMIC-CXR. The experimental results demonstrate the effectiveness of our method, with all evaluation metrics outperforming previous state-of-the-art models.
Enhancing Mobile Face Anti-Spoofing: A Robust Framework for Diverse Attack Types under Screen Flash
Aug 29, 2023Face anti-spoofing (FAS) is crucial for securing face recognition systems. However, existing FAS methods with handcrafted binary or pixel-wise labels have limitations due to diverse presentation attacks (PAs). In this paper, we propose an attack type robust face anti-spoofing framework under light flash, called ATR-FAS. Due to imaging differences caused by various attack types, traditional FAS methods based on single binary classification network may result in excessive intra-class distance of spoof faces, leading to a challenge of decision boundary learning. Therefore, we employed multiple networks to reconstruct multi-frame depth maps as auxiliary supervision, and each network experts in one type of attack. A dual gate module (DGM) consisting of a type gate and a frame-attention gate is introduced, which perform attack type recognition and multi-frame attention generation, respectively. The outputs of DGM are utilized as weight to mix the result of multiple expert networks. The multi-experts mixture enables ATR-FAS to generate spoof-differentiated depth maps, and stably detects spoof faces without being affected by different types of PAs. Moreover, we design a differential normalization procedure to convert original flash frames into differential frames. This simple but effective processing enhances the details in flash frames, aiding in the generation of depth maps. To verify the effectiveness of our framework, we collected a large-scale dataset containing 12,660 live and spoof videos with diverse PAs under dynamic flash from the smartphone screen. Extensive experiments illustrate that the proposed ATR-FAS significantly outperforms existing state-of-the-art methods. The code and dataset will be available at https://github.com/Chaochao-Lin/ATR-FAS.
Occlusion-Aware Deep Convolutional Neural Network via Homogeneous Tanh-transforms for Face Parsing
Aug 29, 2023Face parsing infers a pixel-wise label map for each semantic facial component. Previous methods generally work well for uncovered faces, however overlook the facial occlusion and ignore some contextual area outside a single face, especially when facial occlusion has become a common situation during the COVID-19 epidemic. Inspired by the illumination theory of image, we propose a novel homogeneous tanh-transforms for image preprocessing, which made up of four tanh-transforms, that fuse the central vision and the peripheral vision together. Our proposed method addresses the dilemma of face parsing under occlusion and compresses more information of surrounding context. Based on homogeneous tanh-transforms, we propose an occlusion-aware convolutional neural network for occluded face parsing. It combines the information both in Tanh-polar space and Tanh-Cartesian space, capable of enhancing receptive fields. Furthermore, we introduce an occlusion-aware loss to focus on the boundaries of occluded regions. The network is simple and flexible, and can be trained end-to-end. To facilitate future research of occluded face parsing, we also contribute a new cleaned face parsing dataset, which is manually purified from several academic or industrial datasets, including CelebAMask-HQ, Short-video Face Parsing as well as Helen dataset and will make it public. Experiments demonstrate that our method surpasses state-of-art methods of face parsing under occlusion.
Shape-Margin Knowledge Augmented Network for Thyroid Nodule Segmentation and Diagnosis
Aug 29, 2023

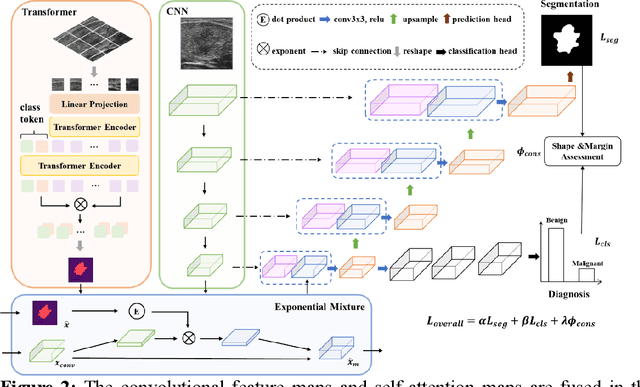
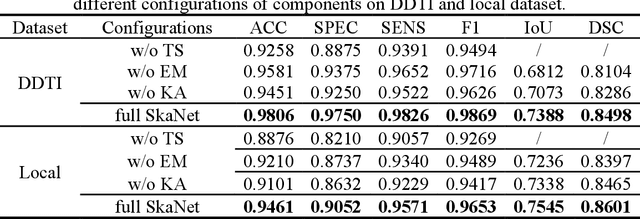
Thyroid nodule segmentation is a crucial step in the diagnostic procedure of physicians and computer-aided diagnosis systems. Mostly, current studies treat segmentation and diagnosis as independent tasks without considering the correlation between these tasks. The sequence steps of these independent tasks in computer-aided diagnosis systems may lead to the accumulation of errors. Therefore, it is worth combining them as a whole through exploring the relationship between thyroid nodule segmentation and diagnosis. According to the thyroid imaging reporting and data system (TI-RADS), the assessment of shape and margin characteristics is the prerequisite for the discrimination of benign and malignant thyroid nodules. These characteristics can be observed in the thyroid nodule segmentation masks. Inspired by the diagnostic procedure of TI-RADS, this paper proposes a shape-margin knowledge augmented network (SkaNet) for simultaneously thyroid nodule segmentation and diagnosis. Due to the similarity in visual features between segmentation and diagnosis, SkaNet shares visual features in the feature extraction stage and then utilizes a dual-branch architecture to perform thyroid nodule segmentation and diagnosis tasks simultaneously. To enhance effective discriminative features, an exponential mixture module is devised, which incorporates convolutional feature maps and self-attention maps by exponential weighting. Then, SkaNet is jointly optimized by a knowledge augmented multi-task loss function with a constraint penalty term. It embeds shape and margin characteristics through numerical computation and models the relationship between the thyroid nodule diagnosis results and segmentation masks.