 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOcclusion-Aware Deep Convolutional Neural Network via Homogeneous Tanh-transforms for Face Parsing
Aug 29, 2023Face parsing infers a pixel-wise label map for each semantic facial component. Previous methods generally work well for uncovered faces, however overlook the facial occlusion and ignore some contextual area outside a single face, especially when facial occlusion has become a common situation during the COVID-19 epidemic. Inspired by the illumination theory of image, we propose a novel homogeneous tanh-transforms for image preprocessing, which made up of four tanh-transforms, that fuse the central vision and the peripheral vision together. Our proposed method addresses the dilemma of face parsing under occlusion and compresses more information of surrounding context. Based on homogeneous tanh-transforms, we propose an occlusion-aware convolutional neural network for occluded face parsing. It combines the information both in Tanh-polar space and Tanh-Cartesian space, capable of enhancing receptive fields. Furthermore, we introduce an occlusion-aware loss to focus on the boundaries of occluded regions. The network is simple and flexible, and can be trained end-to-end. To facilitate future research of occluded face parsing, we also contribute a new cleaned face parsing dataset, which is manually purified from several academic or industrial datasets, including CelebAMask-HQ, Short-video Face Parsing as well as Helen dataset and will make it public. Experiments demonstrate that our method surpasses state-of-art methods of face parsing under occlusion.
GEAR: Augmenting Language Models with Generalizable and Efficient Tool Resolution
Jul 17, 2023


Augmenting large language models (LLM) to use external tools enhances their performance across a variety of tasks. However, prior works over-rely on task-specific demonstration of tool use that limits their generalizability and computational cost due to making many calls to large-scale LLMs. We introduce GEAR, a computationally efficient query-tool grounding algorithm that is generalizable to various tasks that require tool use while not relying on task-specific demonstrations. GEAR achieves better efficiency by delegating tool grounding and execution to small language models (SLM) and LLM, respectively; while leveraging semantic and pattern-based evaluation at both question and answer levels for generalizable tool grounding. We evaluate GEAR on 14 datasets across 6 downstream tasks, demonstrating its strong generalizability to novel tasks, tools and different SLMs. Despite offering more efficiency, GEAR achieves higher precision in tool grounding compared to prior strategies using LLM prompting, thus improving downstream accuracy at a reduced computational cost. For example, we demonstrate that GEAR-augmented GPT-J and GPT-3 outperform counterpart tool-augmented baselines because of better tool use.
A Robust Regression Approach for Background/Foreground Segmentation
Sep 01, 2015

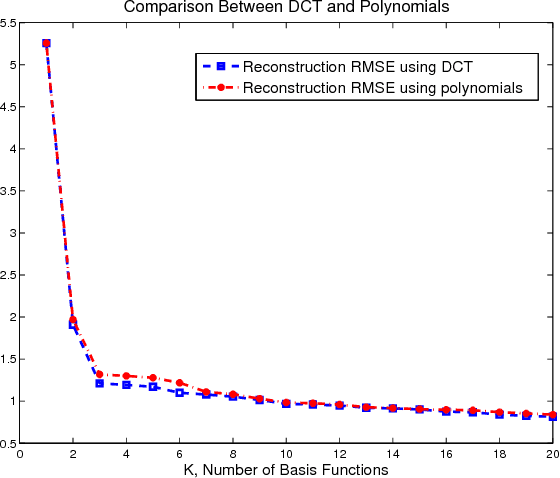
Background/foreground segmentation has a lot of applications in image and video processing. In this paper, a segmentation algorithm is proposed which is mainly designed for text and line extraction in screen content. The proposed method makes use of the fact that the background in each block is usually smoothly varying and can be modeled well by a linear combination of a few smoothly varying basis functions, while the foreground text and graphics create sharp discontinuity. The algorithm separates the background and foreground pixels by trying to fit pixel values in the block into a smooth function using a robust regression method. The inlier pixels that can fit well will be considered as background, while remaining outlier pixels will be considered foreground. This algorithm has been extensively tested on several images from HEVC standard test sequences for screen content coding, and is shown to have superior performance over other methods, such as the k-means clustering based segmentation algorithm in DjVu. This background/foreground segmentation can be used in different applications such as: text extraction, separate coding of background and foreground for compression of screen content and mixed content documents, principle line extraction from palmprint and crease detection in fingerprint images.