 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing Deep Neural Networks: Unleashing the Optimization Potential of Natural Gradient Descent
Dec 10, 2024



Natural gradient descent (NGD) is a powerful optimization technique for machine learning, but the computational complexity of the inverse Fisher information matrix limits its application in training deep neural networks. To overcome this challenge, we propose a novel optimization method for training deep neural networks called structured natural gradient descent (SNGD). Theoretically, we demonstrate that optimizing the original network using NGD is equivalent to using fast gradient descent (GD) to optimize the reconstructed network with a structural transformation of the parameter matrix. Thereby, we decompose the calculation of the global Fisher information matrix into the efficient computation of local Fisher matrices via constructing local Fisher layers in the reconstructed network to speed up the training. Experimental results on various deep networks and datasets demonstrate that SNGD achieves faster convergence speed than NGD while retaining comparable solutions. Furthermore, our method outperforms traditional GDs in terms of efficiency and effectiveness. Thus, our proposed method has the potential to significantly improve the scalability and efficiency of NGD in deep learning applications. Our source code is available at https://github.com/Chaochao-Lin/SNGD.
Unified Mask Embedding and Correspondence Learning for Self-Supervised Video Segmentation
Mar 17, 2023The objective of this paper is self-supervised learning of video object segmentation. We develop a unified framework which simultaneously models cross-frame dense correspondence for locally discriminative feature learning and embeds object-level context for target-mask decoding. As a result, it is able to directly learn to perform mask-guided sequential segmentation from unlabeled videos, in contrast to previous efforts usually relying on an oblique solution - cheaply "copying" labels according to pixel-wise correlations. Concretely, our algorithm alternates between i) clustering video pixels for creating pseudo segmentation labels ex nihilo; and ii) utilizing the pseudo labels to learn mask encoding and decoding for VOS. Unsupervised correspondence learning is further incorporated into this self-taught, mask embedding scheme, so as to ensure the generic nature of the learnt representation and avoid cluster degeneracy. Our algorithm sets state-of-the-arts on two standard benchmarks (i.e., DAVIS17 and YouTube-VOS), narrowing the gap between self- and fully-supervised VOS, in terms of both performance and network architecture design.
Deep Hierarchical Semantic Segmentation
Mar 29, 2022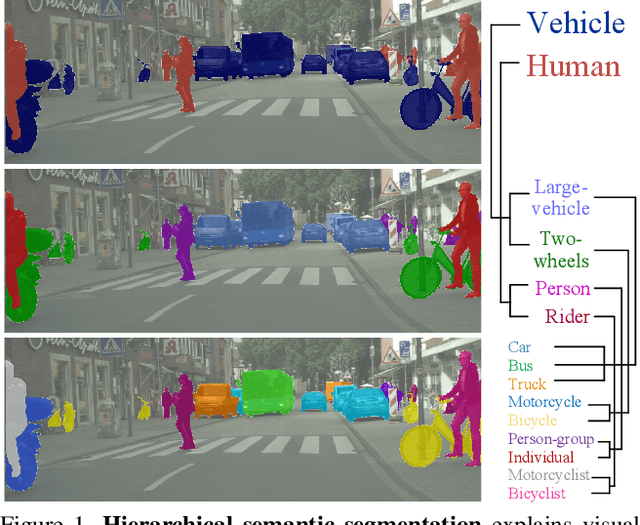
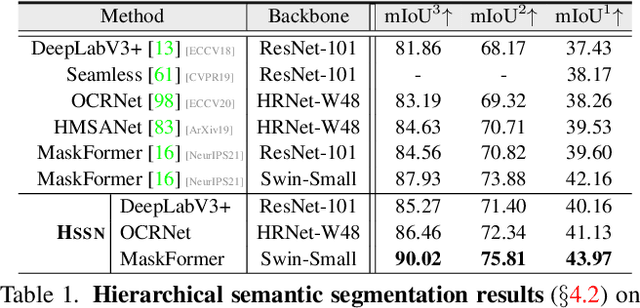
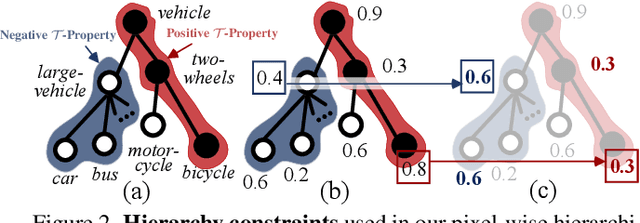

Humans are able to recognize structured relations in observation, allowing us to decompose complex scenes into simpler parts and abstract the visual world in multiple levels. However, such hierarchical reasoning ability of human perception remains largely unexplored in current literature of semantic segmentation. Existing work is often aware of flatten labels and predicts target classes exclusively for each pixel. In this paper, we instead address hierarchical semantic segmentation (HSS), which aims at structured, pixel-wise description of visual observation in terms of a class hierarchy. We devise HSSN, a general HSS framework that tackles two critical issues in this task: i) how to efficiently adapt existing hierarchy-agnostic segmentation networks to the HSS setting, and ii) how to leverage the hierarchy information to regularize HSS network learning. To address i), HSSN directly casts HSS as a pixel-wise multi-label classification task, only bringing minimal architecture change to current segmentation models. To solve ii), HSSN first explores inherent properties of the hierarchy as a training objective, which enforces segmentation predictions to obey the hierarchy structure. Further, with hierarchy-induced margin constraints, HSSN reshapes the pixel embedding space, so as to generate well-structured pixel representations and improve segmentation eventually. We conduct experiments on four semantic segmentation datasets (i.e., Mapillary Vistas 2.0, Cityscapes, LIP, and PASCAL-Person-Part), with different class hierarchies, segmentation network architectures and backbones, showing the generalization and superiority of HSSN.
Locality-Aware Inter-and Intra-Video Reconstruction for Self-Supervised Correspondence Learning
Mar 29, 2022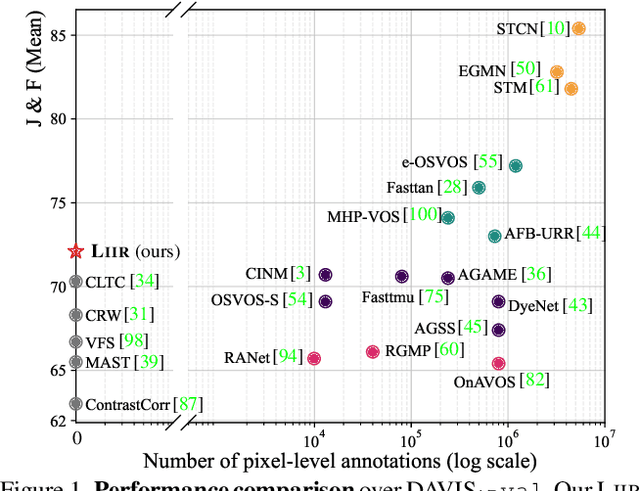
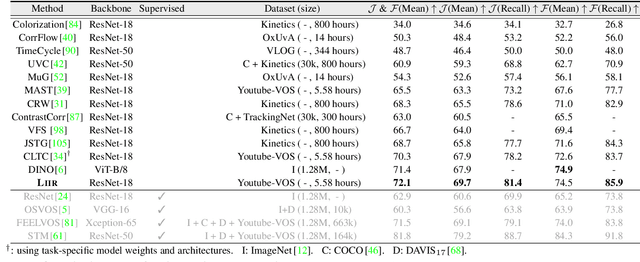
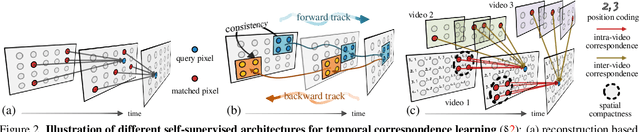
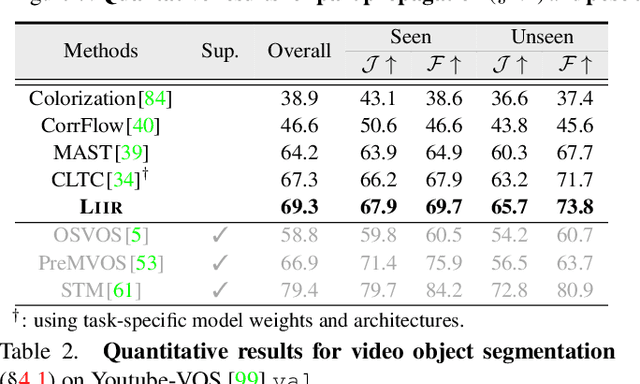
Our target is to learn visual correspondence from unlabeled videos. We develop LIIR, a locality-aware inter-and intra-video reconstruction framework that fills in three missing pieces, i.e., instance discrimination, location awareness, and spatial compactness, of self-supervised correspondence learning puzzle. First, instead of most existing efforts focusing on intra-video self-supervision only, we exploit cross video affinities as extra negative samples within a unified, inter-and intra-video reconstruction scheme. This enables instance discriminative representation learning by contrasting desired intra-video pixel association against negative inter-video correspondence. Second, we merge position information into correspondence matching, and design a position shifting strategy to remove the side-effect of position encoding during inter-video affinity computation, making our LIIR location-sensitive. Third, to make full use of the spatial continuity nature of video data, we impose a compactness-based constraint on correspondence matching, yielding more sparse and reliable solutions. The learned representation surpasses self-supervised state-of-the-arts on label propagation tasks including objects, semantic parts, and keypoints.
Regional Semantic Contrast and Aggregation for Weakly Supervised Semantic Segmentation
Mar 22, 2022
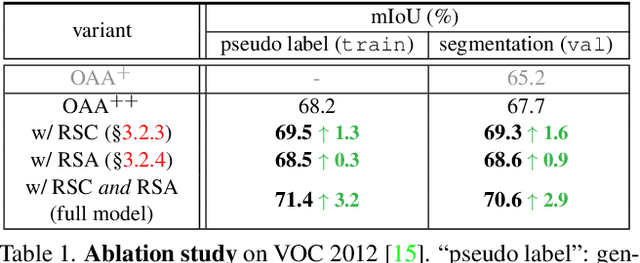
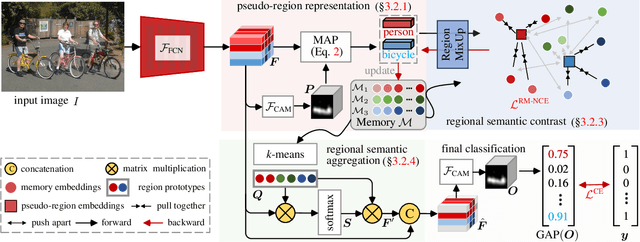

Learning semantic segmentation from weakly-labeled (e.g., image tags only) data is challenging since it is hard to infer dense object regions from sparse semantic tags. Despite being broadly studied, most current efforts directly learn from limited semantic annotations carried by individual image or image pairs, and struggle to obtain integral localization maps. Our work alleviates this from a novel perspective, by exploring rich semantic contexts synergistically among abundant weakly-labeled training data for network learning and inference. In particular, we propose regional semantic contrast and aggregation (RCA) . RCA is equipped with a regional memory bank to store massive, diverse object patterns appearing in training data, which acts as strong support for exploration of dataset-level semantic structure. Particularly, we propose i) semantic contrast to drive network learning by contrasting massive categorical object regions, leading to a more holistic object pattern understanding, and ii) semantic aggregation to gather diverse relational contexts in the memory to enrich semantic representations. In this manner, RCA earns a strong capability of fine-grained semantic understanding, and eventually establishes new state-of-the-art results on two popular benchmarks, i.e., PASCAL VOC 2012 and COCO 2014.
Handwritten Mathematical Expression Recognition via Attention Aggregation based Bi-directional Mutual Learning
Dec 07, 2021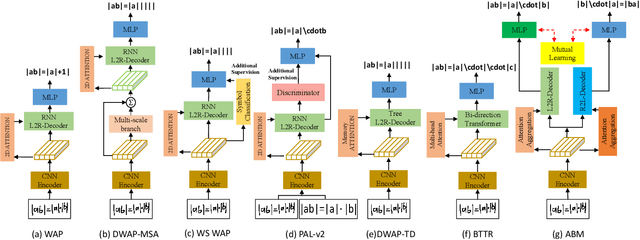
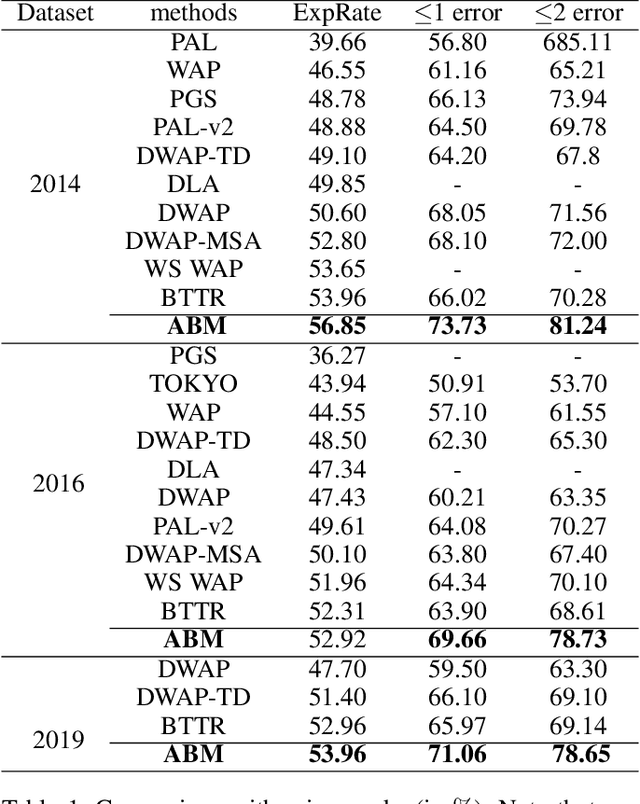
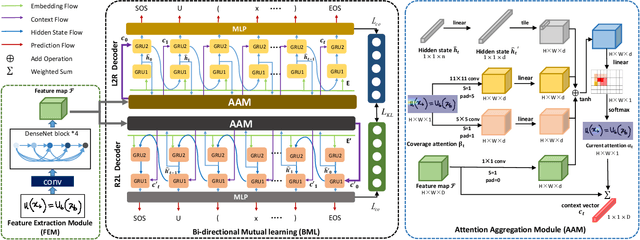
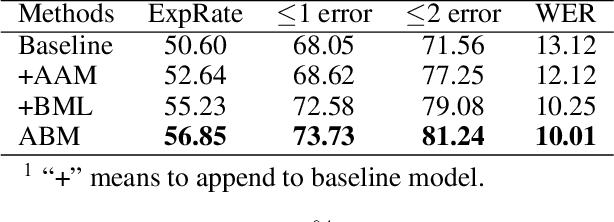
Handwritten mathematical expression recognition aims to automatically generate LaTeX sequences from given images. Currently, attention-based encoder-decoder models are widely used in this task. They typically generate target sequences in a left-to-right (L2R) manner, leaving the right-to-left (R2L) contexts unexploited. In this paper, we propose an Attention aggregation based Bi-directional Mutual learning Network (ABM) which consists of one shared encoder and two parallel inverse decoders (L2R and R2L). The two decoders are enhanced via mutual distillation, which involves one-to-one knowledge transfer at each training step, making full use of the complementary information from two inverse directions. Moreover, in order to deal with mathematical symbols in diverse scales, an Attention Aggregation Module (AAM) is proposed to effectively integrate multi-scale coverage attentions. Notably, in the inference phase, given that the model already learns knowledge from two inverse directions, we only use the L2R branch for inference, keeping the original parameter size and inference speed. Extensive experiments demonstrate that our proposed approach achieves the recognition accuracy of 56.85 % on CROHME 2014, 52.92 % on CROHME 2016, and 53.96 % on CROHME 2019 without data augmentation and model ensembling, substantially outperforming the state-of-the-art methods. The source code is available in the supplementary materials.
* 9 pages,5 figures, to be published in AAAI 2022
Quality-Aware Memory Network for Interactive Volumetric Image Segmentation
Jul 05, 2021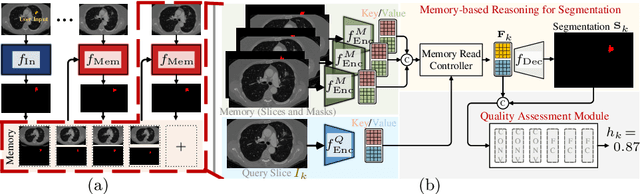
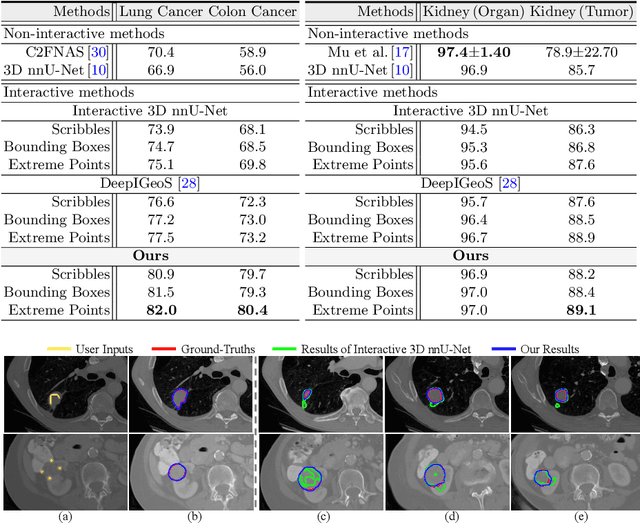
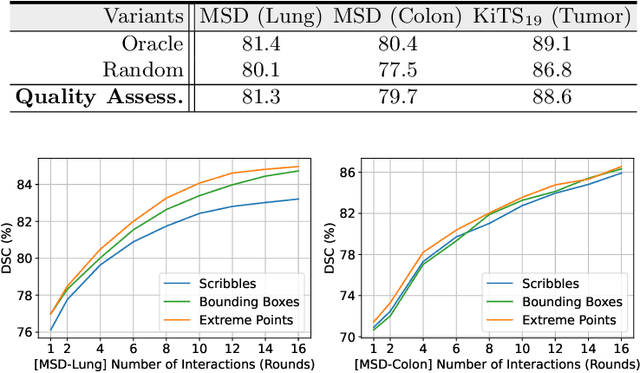
Despite recent progress of automatic medical image segmentation techniques, fully automatic results usually fail to meet the clinical use and typically require further refinement. In this work, we propose a quality-aware memory network for interactive segmentation of 3D medical images. Provided by user guidance on an arbitrary slice, an interaction network is firstly employed to obtain an initial 2D segmentation. The quality-aware memory network subsequently propagates the initial segmentation estimation bidirectionally over the entire volume. Subsequent refinement based on additional user guidance on other slices can be incorporated in the same manner. To further facilitate interactive segmentation, a quality assessment module is introduced to suggest the next slice to segment based on the current segmentation quality of each slice. The proposed network has two appealing characteristics: 1) The memory-augmented network offers the ability to quickly encode past segmentation information, which will be retrieved for the segmentation of other slices; 2) The quality assessment module enables the model to directly estimate the qualities of segmentation predictions, which allows an active learning paradigm where users preferentially label the lowest-quality slice for multi-round refinement. The proposed network leads to a robust interactive segmentation engine, which can generalize well to various types of user annotations (e.g., scribbles, boxes). Experimental results on various medical datasets demonstrate the superiority of our approach in comparison with existing techniques.
Target-Aware Object Discovery and Association for Unsupervised Video Multi-Object Segmentation
Apr 10, 2021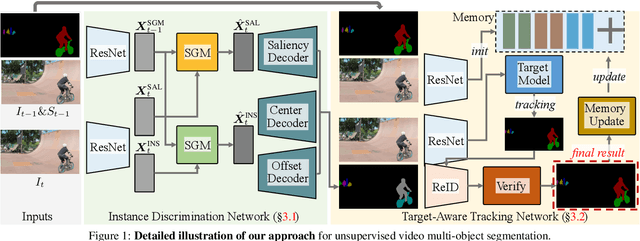
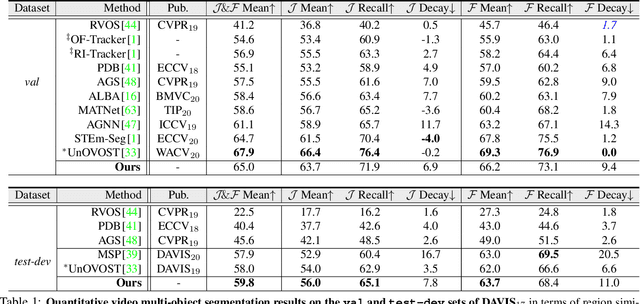
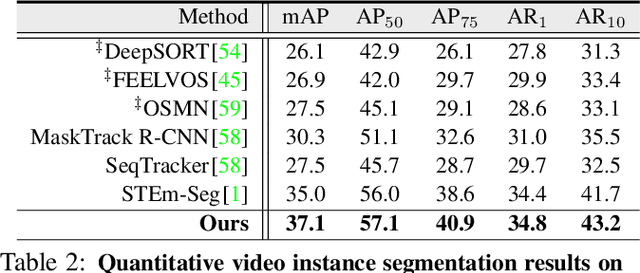

This paper addresses the task of unsupervised video multi-object segmentation. Current approaches follow a two-stage paradigm: 1) detect object proposals using pre-trained Mask R-CNN, and 2) conduct generic feature matching for temporal association using re-identification techniques. However, the generic features, widely used in both stages, are not reliable for characterizing unseen objects, leading to poor generalization. To address this, we introduce a novel approach for more accurate and efficient spatio-temporal segmentation. In particular, to address \textbf{instance discrimination}, we propose to combine foreground region estimation and instance grouping together in one network, and additionally introduce temporal guidance for segmenting each frame, enabling more accurate object discovery. For \textbf{temporal association}, we complement current video object segmentation architectures with a discriminative appearance model, capable of capturing more fine-grained target-specific information. Given object proposals from the instance discrimination network, three essential strategies are adopted to achieve accurate segmentation: 1) target-specific tracking using a memory-augmented appearance model; 2) target-agnostic verification to trace possible tracklets for the proposal; 3) adaptive memory updating using the verified segments. We evaluate the proposed approach on DAVIS$_{17}$ and YouTube-VIS, and the results demonstrate that it outperforms state-of-the-art methods both in segmentation accuracy and inference speed.
Group-Wise Semantic Mining for Weakly Supervised Semantic Segmentation
Dec 09, 2020
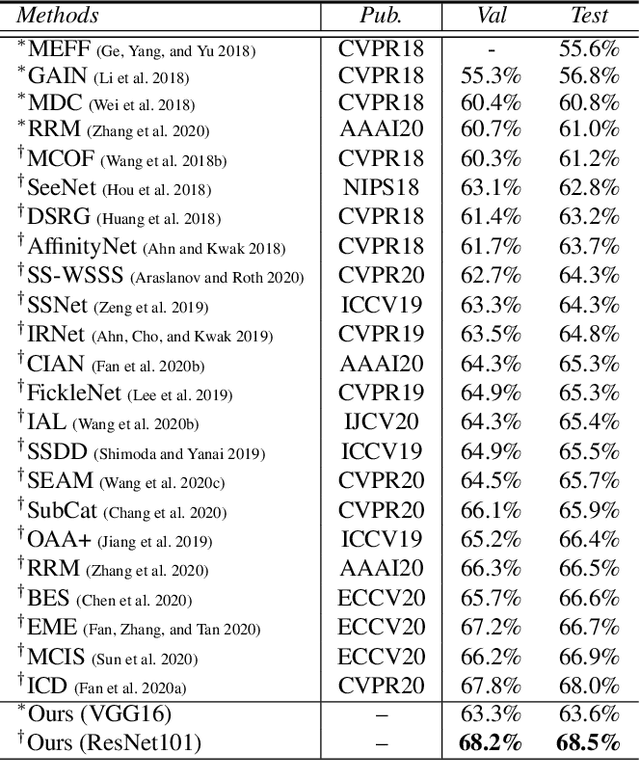
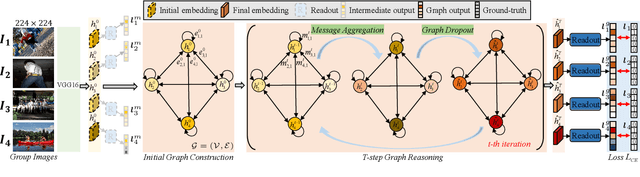

Acquiring sufficient ground-truth supervision to train deep visual models has been a bottleneck over the years due to the data-hungry nature of deep learning. This is exacerbated in some structured prediction tasks, such as semantic segmentation, which requires pixel-level annotations. This work addresses weakly supervised semantic segmentation (WSSS), with the goal of bridging the gap between image-level annotations and pixel-level segmentation. We formulate WSSS as a novel group-wise learning task that explicitly models semantic dependencies in a group of images to estimate more reliable pseudo ground-truths, which can be used for training more accurate segmentation models. In particular, we devise a graph neural network (GNN) for group-wise semantic mining, wherein input images are represented as graph nodes, and the underlying relations between a pair of images are characterized by an efficient co-attention mechanism. Moreover, in order to prevent the model from paying excessive attention to common semantics only, we further propose a graph dropout layer, encouraging the model to learn more accurate and complete object responses. The whole network is end-to-end trainable by iterative message passing, which propagates interaction cues over the images to progressively improve the performance. We conduct experiments on the popular PASCAL VOC 2012 and COCO benchmarks, and our model yields state-of-the-art performance. Our code is available at: https://github.com/Lixy1997/Group-WSSS.
DTDN: Dual-task De-raining Network
Aug 21, 2020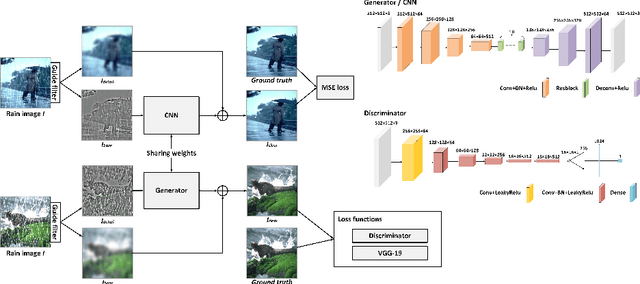


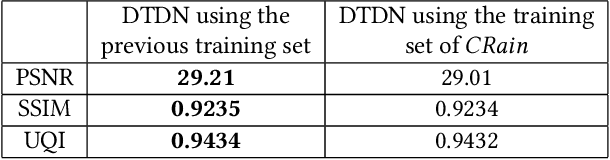
Removing rain streaks from rainy images is necessary for many tasks in computer vision, such as object detection and recognition. It needs to address two mutually exclusive objectives: removing rain streaks and reserving realistic details. Balancing them is critical for de-raining methods. We propose an end-to-end network, called dual-task de-raining network (DTDN), consisting of two sub-networks: generative adversarial network (GAN) and convolutional neural network (CNN), to remove rain streaks via coordinating the two mutually exclusive objectives self-adaptively. DTDN-GAN is mainly used to remove structural rain streaks, and DTDN-CNN is designed to recover details in original images. We also design a training algorithm to train these two sub-networks of DTDN alternatively, which share same weights but use different training sets. We further enrich two existing datasets to approximate the distribution of real rain streaks. Experimental results show that our method outperforms several recent state-of-the-art methods, based on both benchmark testing datasets and real rainy images.