 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTarget-Aware Object Discovery and Association for Unsupervised Video Multi-Object Segmentation
Paper and Code
Apr 10, 2021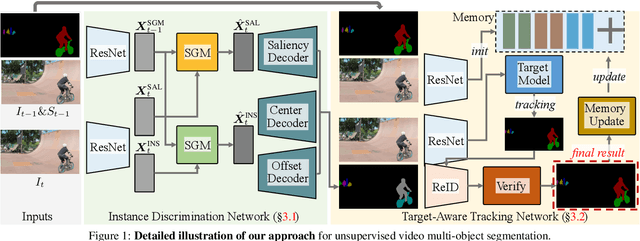
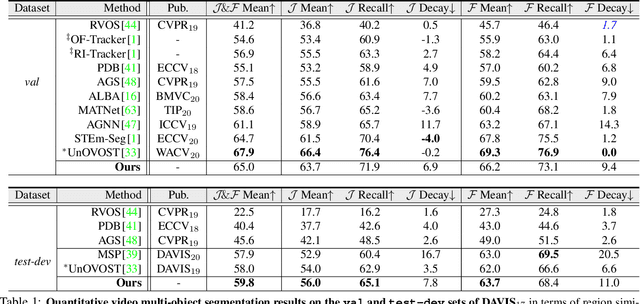
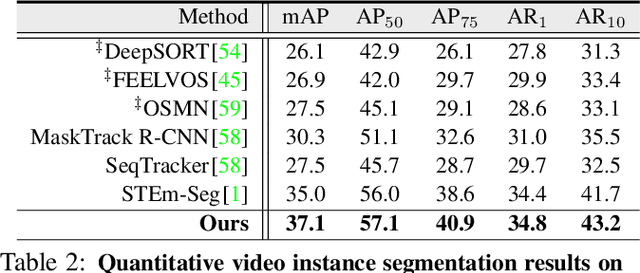

This paper addresses the task of unsupervised video multi-object segmentation. Current approaches follow a two-stage paradigm: 1) detect object proposals using pre-trained Mask R-CNN, and 2) conduct generic feature matching for temporal association using re-identification techniques. However, the generic features, widely used in both stages, are not reliable for characterizing unseen objects, leading to poor generalization. To address this, we introduce a novel approach for more accurate and efficient spatio-temporal segmentation. In particular, to address \textbf{instance discrimination}, we propose to combine foreground region estimation and instance grouping together in one network, and additionally introduce temporal guidance for segmenting each frame, enabling more accurate object discovery. For \textbf{temporal association}, we complement current video object segmentation architectures with a discriminative appearance model, capable of capturing more fine-grained target-specific information. Given object proposals from the instance discrimination network, three essential strategies are adopted to achieve accurate segmentation: 1) target-specific tracking using a memory-augmented appearance model; 2) target-agnostic verification to trace possible tracklets for the proposal; 3) adaptive memory updating using the verified segments. We evaluate the proposed approach on DAVIS$_{17}$ and YouTube-VIS, and the results demonstrate that it outperforms state-of-the-art methods both in segmentation accuracy and inference speed.