 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradingAttack: Attacking Large Language Models Towards Short Answer Grading Ability
Feb 01, 2026Large language models (LLMs) have demonstrated remarkable potential for automatic short answer grading (ASAG), significantly boosting student assessment efficiency and scalability in educational scenarios. However, their vulnerability to adversarial manipulation raises critical concerns about automatic grading fairness and reliability. In this paper, we introduce GradingAttack, a fine-grained adversarial attack framework that systematically evaluates the vulnerability of LLM based ASAG models. Specifically, we align general-purpose attack methods with the specific objectives of ASAG by designing token-level and prompt-level strategies that manipulate grading outcomes while maintaining high camouflage. Furthermore, to quantify attack camouflage, we propose a novel evaluation metric that balances attack success and camouflage. Experiments on multiple datasets demonstrate that both attack strategies effectively mislead grading models, with prompt-level attacks achieving higher success rates and token-level attacks exhibiting superior camouflage capability. Our findings underscore the need for robust defenses to ensure fairness and reliability in ASAG. Our code and datasets are available at https://anonymous.4open.science/r/GradingAttack.
Target-Aware Object Discovery and Association for Unsupervised Video Multi-Object Segmentation
Apr 10, 2021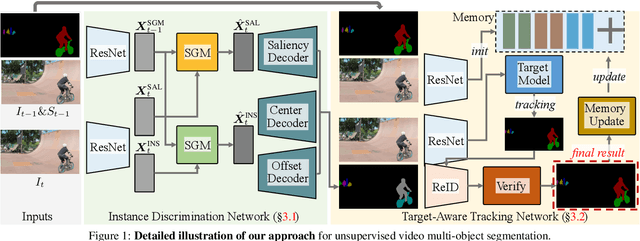
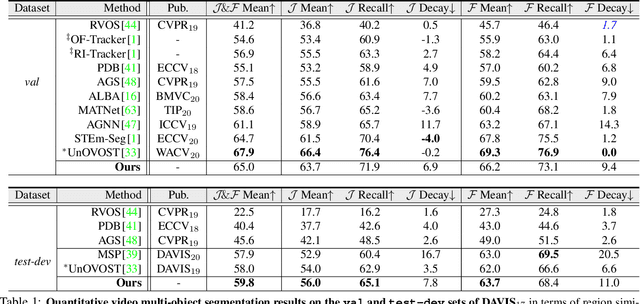
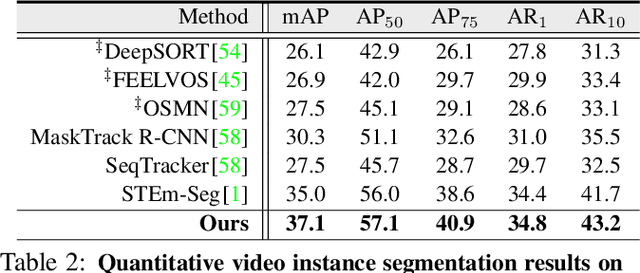

This paper addresses the task of unsupervised video multi-object segmentation. Current approaches follow a two-stage paradigm: 1) detect object proposals using pre-trained Mask R-CNN, and 2) conduct generic feature matching for temporal association using re-identification techniques. However, the generic features, widely used in both stages, are not reliable for characterizing unseen objects, leading to poor generalization. To address this, we introduce a novel approach for more accurate and efficient spatio-temporal segmentation. In particular, to address \textbf{instance discrimination}, we propose to combine foreground region estimation and instance grouping together in one network, and additionally introduce temporal guidance for segmenting each frame, enabling more accurate object discovery. For \textbf{temporal association}, we complement current video object segmentation architectures with a discriminative appearance model, capable of capturing more fine-grained target-specific information. Given object proposals from the instance discrimination network, three essential strategies are adopted to achieve accurate segmentation: 1) target-specific tracking using a memory-augmented appearance model; 2) target-agnostic verification to trace possible tracklets for the proposal; 3) adaptive memory updating using the verified segments. We evaluate the proposed approach on DAVIS$_{17}$ and YouTube-VIS, and the results demonstrate that it outperforms state-of-the-art methods both in segmentation accuracy and inference speed.
Group-Wise Semantic Mining for Weakly Supervised Semantic Segmentation
Dec 09, 2020
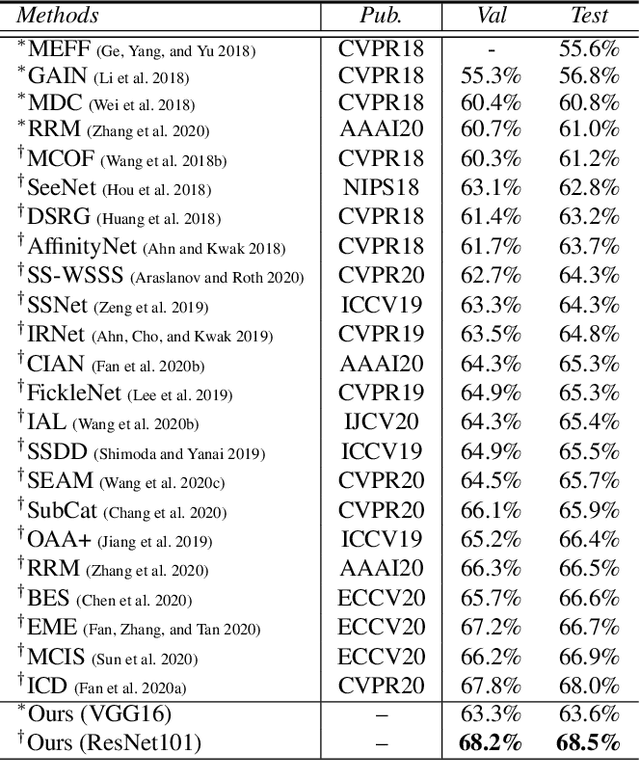
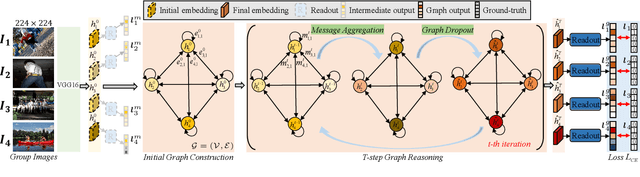

Acquiring sufficient ground-truth supervision to train deep visual models has been a bottleneck over the years due to the data-hungry nature of deep learning. This is exacerbated in some structured prediction tasks, such as semantic segmentation, which requires pixel-level annotations. This work addresses weakly supervised semantic segmentation (WSSS), with the goal of bridging the gap between image-level annotations and pixel-level segmentation. We formulate WSSS as a novel group-wise learning task that explicitly models semantic dependencies in a group of images to estimate more reliable pseudo ground-truths, which can be used for training more accurate segmentation models. In particular, we devise a graph neural network (GNN) for group-wise semantic mining, wherein input images are represented as graph nodes, and the underlying relations between a pair of images are characterized by an efficient co-attention mechanism. Moreover, in order to prevent the model from paying excessive attention to common semantics only, we further propose a graph dropout layer, encouraging the model to learn more accurate and complete object responses. The whole network is end-to-end trainable by iterative message passing, which propagates interaction cues over the images to progressively improve the performance. We conduct experiments on the popular PASCAL VOC 2012 and COCO benchmarks, and our model yields state-of-the-art performance. Our code is available at: https://github.com/Lixy1997/Group-WSSS.