 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIFAdapter: Instance Feature Control for Grounded Text-to-Image Generation
Sep 12, 2024



While Text-to-Image (T2I) diffusion models excel at generating visually appealing images of individual instances, they struggle to accurately position and control the features generation of multiple instances. The Layout-to-Image (L2I) task was introduced to address the positioning challenges by incorporating bounding boxes as spatial control signals, but it still falls short in generating precise instance features. In response, we propose the Instance Feature Generation (IFG) task, which aims to ensure both positional accuracy and feature fidelity in generated instances. To address the IFG task, we introduce the Instance Feature Adapter (IFAdapter). The IFAdapter enhances feature depiction by incorporating additional appearance tokens and utilizing an Instance Semantic Map to align instance-level features with spatial locations. The IFAdapter guides the diffusion process as a plug-and-play module, making it adaptable to various community models. For evaluation, we contribute an IFG benchmark and develop a verification pipeline to objectively compare models' abilities to generate instances with accurate positioning and features. Experimental results demonstrate that IFAdapter outperforms other models in both quantitative and qualitative evaluations.
Handwritten Mathematical Expression Recognition via Attention Aggregation based Bi-directional Mutual Learning
Dec 07, 2021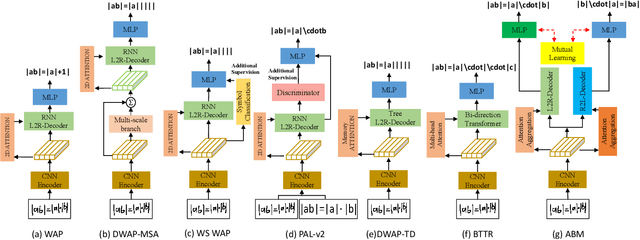
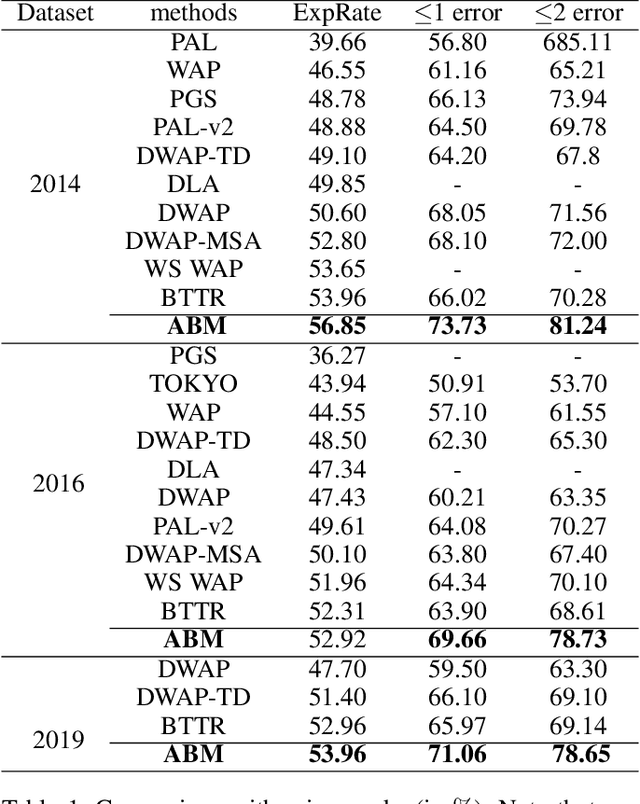
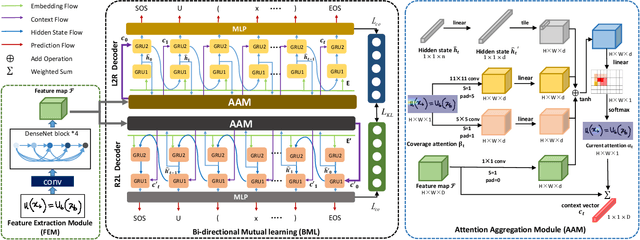
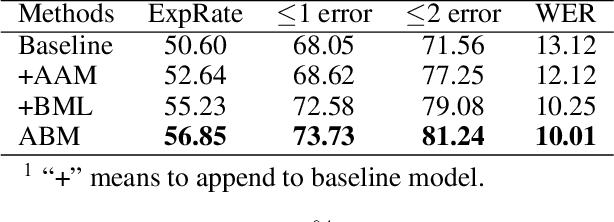
Handwritten mathematical expression recognition aims to automatically generate LaTeX sequences from given images. Currently, attention-based encoder-decoder models are widely used in this task. They typically generate target sequences in a left-to-right (L2R) manner, leaving the right-to-left (R2L) contexts unexploited. In this paper, we propose an Attention aggregation based Bi-directional Mutual learning Network (ABM) which consists of one shared encoder and two parallel inverse decoders (L2R and R2L). The two decoders are enhanced via mutual distillation, which involves one-to-one knowledge transfer at each training step, making full use of the complementary information from two inverse directions. Moreover, in order to deal with mathematical symbols in diverse scales, an Attention Aggregation Module (AAM) is proposed to effectively integrate multi-scale coverage attentions. Notably, in the inference phase, given that the model already learns knowledge from two inverse directions, we only use the L2R branch for inference, keeping the original parameter size and inference speed. Extensive experiments demonstrate that our proposed approach achieves the recognition accuracy of 56.85 % on CROHME 2014, 52.92 % on CROHME 2016, and 53.96 % on CROHME 2019 without data augmentation and model ensembling, substantially outperforming the state-of-the-art methods. The source code is available in the supplementary materials.
* 9 pages,5 figures, to be published in AAAI 2022