 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandwritten Mathematical Expression Recognition via Attention Aggregation based Bi-directional Mutual Learning
Paper and Code
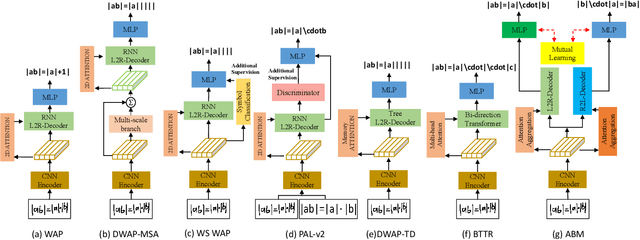
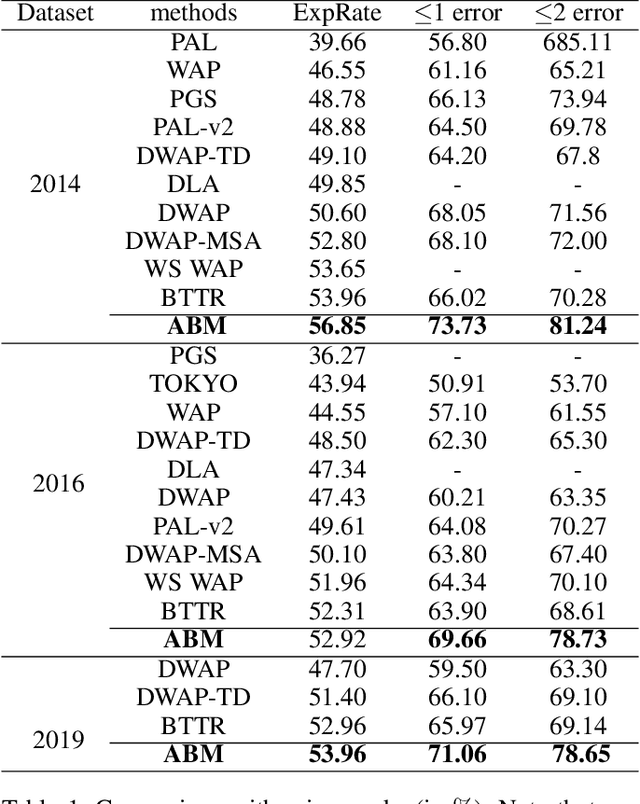
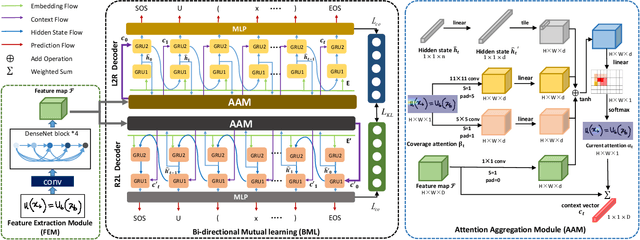
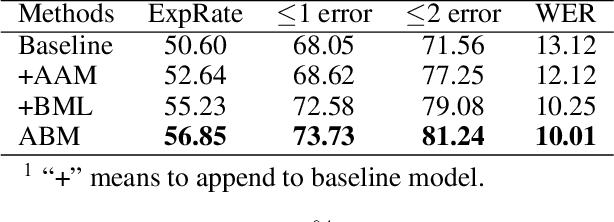
Handwritten mathematical expression recognition aims to automatically generate LaTeX sequences from given images. Currently, attention-based encoder-decoder models are widely used in this task. They typically generate target sequences in a left-to-right (L2R) manner, leaving the right-to-left (R2L) contexts unexploited. In this paper, we propose an Attention aggregation based Bi-directional Mutual learning Network (ABM) which consists of one shared encoder and two parallel inverse decoders (L2R and R2L). The two decoders are enhanced via mutual distillation, which involves one-to-one knowledge transfer at each training step, making full use of the complementary information from two inverse directions. Moreover, in order to deal with mathematical symbols in diverse scales, an Attention Aggregation Module (AAM) is proposed to effectively integrate multi-scale coverage attentions. Notably, in the inference phase, given that the model already learns knowledge from two inverse directions, we only use the L2R branch for inference, keeping the original parameter size and inference speed. Extensive experiments demonstrate that our proposed approach achieves the recognition accuracy of 56.85 % on CROHME 2014, 52.92 % on CROHME 2016, and 53.96 % on CROHME 2019 without data augmentation and model ensembling, substantially outperforming the state-of-the-art methods. The source code is available in the supplementary materials.