 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign, Results and Industry Implications of the World's First Insurance Large Language Model Evaluation Benchmark
Nov 11, 2025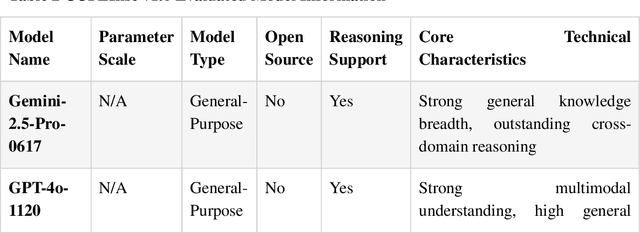
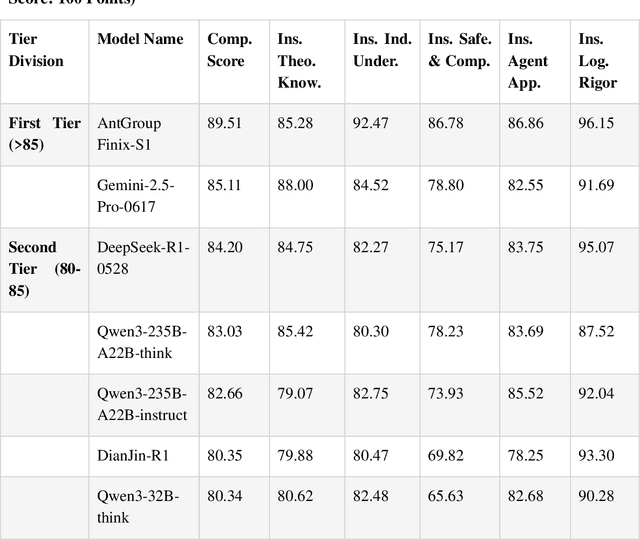
This paper comprehensively elaborates on the construction methodology, multi-dimensional evaluation system, and underlying design philosophy of CUFEInse v1.0. Adhering to the principles of "quantitative-oriented, expert-driven, and multi-validation," the benchmark establishes an evaluation framework covering 5 core dimensions, 54 sub-indicators, and 14,430 high-quality questions, encompassing insurance theoretical knowledge, industry understanding, safety and compliance, intelligent agent application, and logical rigor. Based on this benchmark, a comprehensive evaluation was conducted on 11 mainstream large language models. The evaluation results reveal that general-purpose models suffer from common bottlenecks such as weak actuarial capabilities and inadequate compliance adaptation. High-quality domain-specific training demonstrates significant advantages in insurance vertical scenarios but exhibits shortcomings in business adaptation and compliance. The evaluation also accurately identifies the common bottlenecks of current large models in professional scenarios such as insurance actuarial, underwriting and claim settlement reasoning, and compliant marketing copywriting. The establishment of CUFEInse not only fills the gap in professional evaluation benchmarks for the insurance field, providing academia and industry with a professional, systematic, and authoritative evaluation tool, but also its construction concept and methodology offer important references for the evaluation paradigm of large models in vertical fields, serving as an authoritative reference for academic model optimization and industrial model selection. Finally, the paper looks forward to the future iteration direction of the evaluation benchmark and the core development direction of "domain adaptation + reasoning enhancement" for insurance large models.
POSE: Phased One-Step Adversarial Equilibrium for Video Diffusion Models
Aug 28, 2025



The field of video diffusion generation faces critical bottlenecks in sampling efficiency, especially for large-scale models and long sequences. Existing video acceleration methods adopt image-based techniques but suffer from fundamental limitations: they neither model the temporal coherence of video frames nor provide single-step distillation for large-scale video models. To bridge this gap, we propose POSE (Phased One-Step Equilibrium), a distillation framework that reduces the sampling steps of large-scale video diffusion models, enabling the generation of high-quality videos in a single step. POSE employs a carefully designed two-phase process to distill video models:(i) stability priming: a warm-up mechanism to stabilize adversarial distillation that adapts the high-quality trajectory of the one-step generator from high to low signal-to-noise ratio regimes, optimizing the video quality of single-step mappings near the endpoints of flow trajectories. (ii) unified adversarial equilibrium: a flexible self-adversarial distillation mechanism that promotes stable single-step adversarial training towards a Nash equilibrium within the Gaussian noise space, generating realistic single-step videos close to real videos. For conditional video generation, we propose (iii) conditional adversarial consistency, a method to improve both semantic consistency and frame consistency between conditional frames and generated frames. Comprehensive experiments demonstrate that POSE outperforms other acceleration methods on VBench-I2V by average 7.15% in semantic alignment, temporal conference and frame quality, reducing the latency of the pre-trained model by 100$\times$, from 1000 seconds to 10 seconds, while maintaining competitive performance.
Automatic Construction of Multiple Classification Dimensions for Managing Approaches in Scientific Papers
May 29, 2025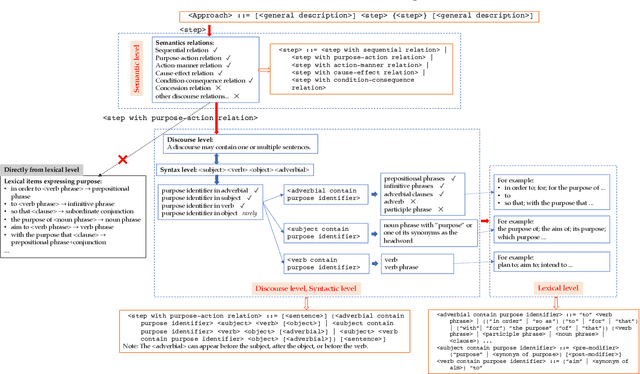
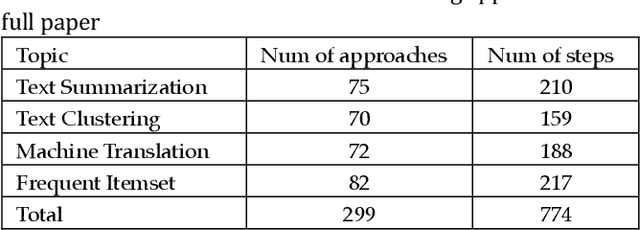


Approaches form the foundation for conducting scientific research. Querying approaches from a vast body of scientific papers is extremely time-consuming, and without a well-organized management framework, researchers may face significant challenges in querying and utilizing relevant approaches. Constructing multiple dimensions on approaches and managing them from these dimensions can provide an efficient solution. Firstly, this paper identifies approach patterns using a top-down way, refining the patterns through four distinct linguistic levels: semantic level, discourse level, syntactic level, and lexical level. Approaches in scientific papers are extracted based on approach patterns. Additionally, five dimensions for categorizing approaches are identified using these patterns. This paper proposes using tree structure to represent step and measuring the similarity between different steps with a tree-structure-based similarity measure that focuses on syntactic-level similarities. A collection similarity measure is proposed to compute the similarity between approaches. A bottom-up clustering algorithm is proposed to construct class trees for approach components within each dimension by merging each approach component or class with its most similar approach component or class in each iteration. The class labels generated during the clustering process indicate the common semantics of the step components within the approach components in each class and are used to manage the approaches within the class. The class trees of the five dimensions collectively form a multi-dimensional approach space. The application of approach queries on the multi-dimensional approach space demonstrates that querying within this space ensures strong relevance between user queries and results and rapidly reduces search space through a class-based query mechanism.
IFAdapter: Instance Feature Control for Grounded Text-to-Image Generation
Sep 12, 2024



While Text-to-Image (T2I) diffusion models excel at generating visually appealing images of individual instances, they struggle to accurately position and control the features generation of multiple instances. The Layout-to-Image (L2I) task was introduced to address the positioning challenges by incorporating bounding boxes as spatial control signals, but it still falls short in generating precise instance features. In response, we propose the Instance Feature Generation (IFG) task, which aims to ensure both positional accuracy and feature fidelity in generated instances. To address the IFG task, we introduce the Instance Feature Adapter (IFAdapter). The IFAdapter enhances feature depiction by incorporating additional appearance tokens and utilizing an Instance Semantic Map to align instance-level features with spatial locations. The IFAdapter guides the diffusion process as a plug-and-play module, making it adaptable to various community models. For evaluation, we contribute an IFG benchmark and develop a verification pipeline to objectively compare models' abilities to generate instances with accurate positioning and features. Experimental results demonstrate that IFAdapter outperforms other models in both quantitative and qualitative evaluations.
Mining both Commonality and Specificity from Multiple Documents for Multi-Document Summarization
Mar 05, 2023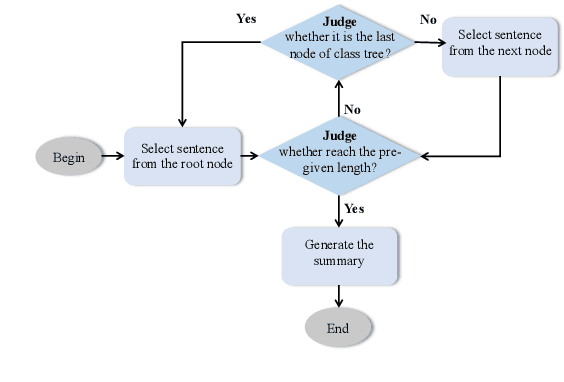
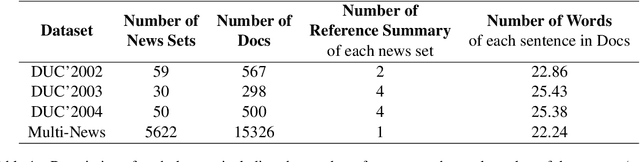
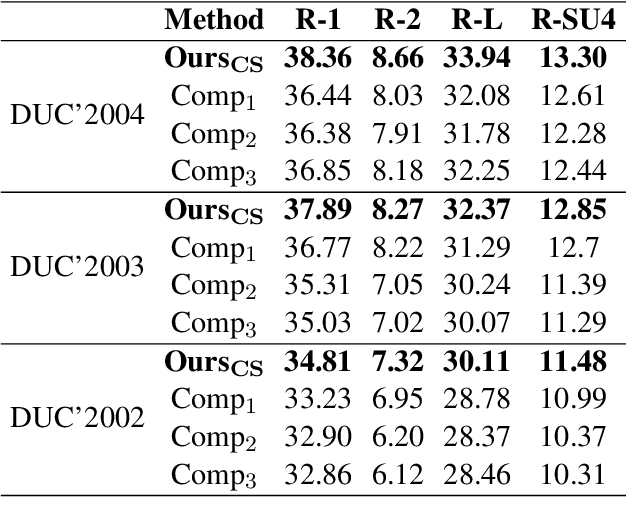
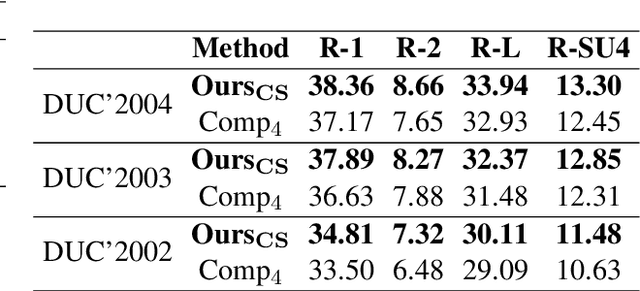
The multi-document summarization task requires the designed summarizer to generate a short text that covers the important information of original documents and satisfies content diversity. This paper proposes a multi-document summarization approach based on hierarchical clustering of documents. It utilizes the constructed class tree of documents to extract both the sentences reflecting the commonality of all documents and the sentences reflecting the specificity of some subclasses of these documents for generating a summary, so as to satisfy the coverage and diversity requirements of multi-document summarization. Comparative experiments with different variant approaches on DUC'2002-2004 datasets prove the effectiveness of mining both the commonality and specificity of documents for multi-document summarization. Experiments on DUC'2004 and Multi-News datasets show that our approach achieves competitive performance compared to the state-of-the-art unsupervised and supervised approaches.