 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMining both Commonality and Specificity from Multiple Documents for Multi-Document Summarization
Paper and Code
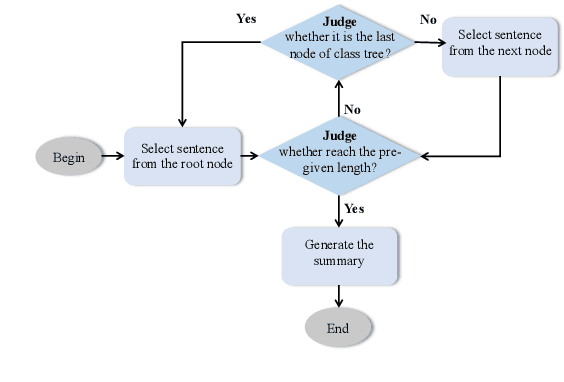
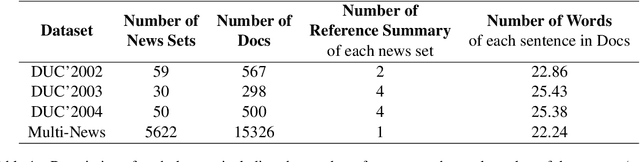
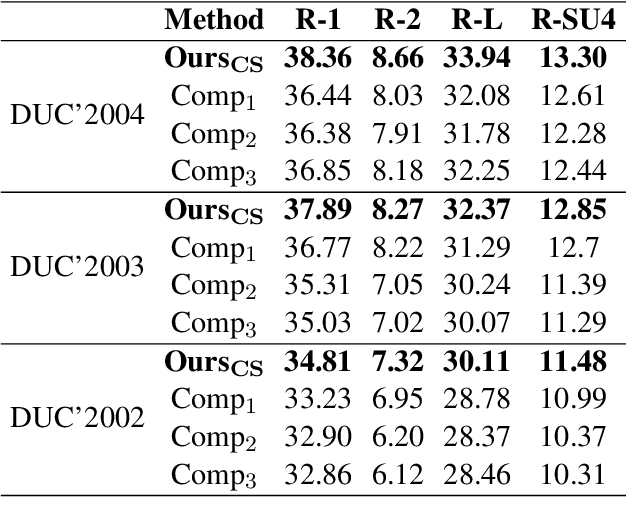
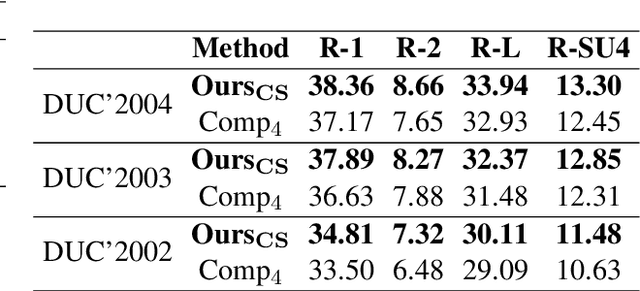
The multi-document summarization task requires the designed summarizer to generate a short text that covers the important information of original documents and satisfies content diversity. This paper proposes a multi-document summarization approach based on hierarchical clustering of documents. It utilizes the constructed class tree of documents to extract both the sentences reflecting the commonality of all documents and the sentences reflecting the specificity of some subclasses of these documents for generating a summary, so as to satisfy the coverage and diversity requirements of multi-document summarization. Comparative experiments with different variant approaches on DUC'2002-2004 datasets prove the effectiveness of mining both the commonality and specificity of documents for multi-document summarization. Experiments on DUC'2004 and Multi-News datasets show that our approach achieves competitive performance compared to the state-of-the-art unsupervised and supervised approaches.