 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriFusion-SR: Joint Tri-Modal Medical Image Fusion and SR
Mar 10, 2026Multimodal medical image fusion facilitates comprehensive diagnosis by aggregating complementary structural and functional information, but its effectiveness is limited by resolution degradation and modality discrepancies. Existing approaches typically perform image fusion and super-resolution (SR) in separate stages, leading to artifacts and degraded perceptual quality. These limitations are further amplified in tri-modal settings that combine anatomical modalities (e.g., MRI, CT) with functional scans (e.g., PET, SPECT) due to pronounced frequency domain imbalances. We propose TriFusionSR, a wavelet-guided conditional diffusion framework for joint tri-modal fusion and SR. The framework explicitly decomposes multimodal features into frequency bands using the 2D Discrete Wavelet Transform, enabling frequency-aware crossmodal interaction. We further introduce a Rectified Wavelet Features (RWF) strategy for latent coefficient calibration, followed by an Adaptive Spatial-Frequency Fusion (ASFF) module with gated channel-spatial attention to enable structure-driven multimodal refinement. Extensive experiments demonstrate state-of-the-art performance, achieving 4.8-12.4% PSNR improvement and substantial reductions in RMSE and LPIPS across multiple upsampling scales.
CLIP-Guided Multi-Task Regression for Multi-View Plant Phenotyping
Mar 04, 2026Modeling plant growth dynamics plays a central role in modern agricultural research. However, learning robust predictors from multi-view plant imagery remains challenging due to strong viewpoint redundancy and viewpoint-dependent appearance changes. We propose a level-aware vision language framework that jointly predicts plant age and leaf count using a single multi-task model built on CLIP embeddings. Our method aggregates rotational views into angle-invariant representations and conditions visual features on lightweight text priors encoding viewpoint level for stable prediction under incomplete or unordered inputs. On the GroMo25 benchmark, our approach reduces mean age MAE from 7.74 to 3.91 and mean leaf-count MAE from 5.52 to 3.08 compared to the GroMo baseline, corresponding to improvements of 49.5% and 44.2%, respectively. The unified formulation simplifies the pipeline by replacing the conventional dual-model setup while improving robustness to missing views. The models and code is available at: https://github.com/SimonWarmers/CLIP-MVP
Illuminating Darkness: Enhancing Real-world Low-light Scenes with Smartphone Images
Mar 10, 2025Digital cameras often struggle to produce plausible images in low-light conditions. Improving these single-shot images remains challenging due to a lack of diverse real-world pair data samples. To address this limitation, we propose a large-scale high-resolution (i.e., beyond 4k) pair Single-Shot Low-Light Enhancement (SLLIE) dataset. Our dataset comprises 6,425 unique focus-aligned image pairs captured with smartphone sensors in dynamic settings under challenging lighting conditions (0.1--200 lux), covering various indoor and outdoor scenes with varying noise and intensity. We extracted and refined around 180,000 non-overlapping patches from 6,025 collected scenes for training while reserving 400 pairs for benchmarking. In addition to that, we collected 2,117 low-light scenes from different sources for extensive real-world aesthetic evaluation. To our knowledge, this is the largest real-world dataset available for SLLIE research. We also propose learning luminance-chrominance (LC) attributes separately through a tuning fork-shaped transformer model to enhance real-world low-light images, addressing challenges like denoising and over-enhancement in complex scenes. We also propose an LC cross-attention block for feature fusion, an LC refinement block for enhanced reconstruction, and LC-guided supervision to ensure perceptually coherent enhancements. We demonstrated our method's effectiveness across various hardware and scenarios, proving its practicality in real-world applications. Code and dataset available at https://github.com/sharif-apu/LSD-TFFormer.
ContextFormer: Redefining Efficiency in Semantic Segmentation
Jan 31, 2025



Semantic segmentation assigns labels to pixels in images, a critical yet challenging task in computer vision. Convolutional methods, although capturing local dependencies well, struggle with long-range relationships. Vision Transformers (ViTs) excel in global context capture but are hindered by high computational demands, especially for high-resolution inputs. Most research optimizes the encoder architecture, leaving the bottleneck underexplored - a key area for enhancing performance and efficiency. We propose ContextFormer, a hybrid framework leveraging the strengths of CNNs and ViTs in the bottleneck to balance efficiency, accuracy, and robustness for real-time semantic segmentation. The framework's efficiency is driven by three synergistic modules: the Token Pyramid Extraction Module (TPEM) for hierarchical multi-scale representation, the Transformer and Modulating DepthwiseConv (Trans-MDC) block for dynamic scale-aware feature modeling, and the Feature Merging Module (FMM) for robust integration with enhanced spatial and contextual consistency. Extensive experiments on ADE20K, Pascal Context, CityScapes, and COCO-Stuff datasets show ContextFormer significantly outperforms existing models, achieving state-of-the-art mIoU scores, setting a new benchmark for efficiency and performance. The codes will be made publicly available.
CPLIP: Zero-Shot Learning for Histopathology with Comprehensive Vision-Language Alignment
Jun 07, 2024



This paper proposes Comprehensive Pathology Language Image Pre-training (CPLIP), a new unsupervised technique designed to enhance the alignment of images and text in histopathology for tasks such as classification and segmentation. This methodology enriches vision-language models by leveraging extensive data without needing ground truth annotations. CPLIP involves constructing a pathology-specific dictionary, generating textual descriptions for images using language models, and retrieving relevant images for each text snippet via a pre-trained model. The model is then fine-tuned using a many-to-many contrastive learning method to align complex interrelated concepts across both modalities. Evaluated across multiple histopathology tasks, CPLIP shows notable improvements in zero-shot learning scenarios, outperforming existing methods in both interpretability and robustness and setting a higher benchmark for the application of vision-language models in the field. To encourage further research and replication, the code for CPLIP is available on GitHub at https://cplip.github.io/
Improving Underwater Visual Tracking With a Large Scale Dataset and Image Enhancement
Aug 31, 2023This paper presents a new dataset and general tracker enhancement method for Underwater Visual Object Tracking (UVOT). Despite its significance, underwater tracking has remained unexplored due to data inaccessibility. It poses distinct challenges; the underwater environment exhibits non-uniform lighting conditions, low visibility, lack of sharpness, low contrast, camouflage, and reflections from suspended particles. Performance of traditional tracking methods designed primarily for terrestrial or open-air scenarios drops in such conditions. We address the problem by proposing a novel underwater image enhancement algorithm designed specifically to boost tracking quality. The method has resulted in a significant performance improvement, of up to 5.0% AUC, of state-of-the-art (SOTA) visual trackers. To develop robust and accurate UVOT methods, large-scale datasets are required. To this end, we introduce a large-scale UVOT benchmark dataset consisting of 400 video segments and 275,000 manually annotated frames enabling underwater training and evaluation of deep trackers. The videos are labelled with several underwater-specific tracking attributes including watercolor variation, target distractors, camouflage, target relative size, and low visibility conditions. The UVOT400 dataset, tracking results, and the code are publicly available on: https://github.com/BasitAlawode/UWVOT400.
AI and 6G into the Metaverse: Fundamentals, Challenges and Future Research Trends
Aug 23, 2022



Since Facebook was renamed Meta, a lot of attention, debate, and exploration have intensified about what the Metaverse is, how it works, and the possible ways to exploit it. It is anticipated that Metaverse will be a continuum of rapidly emerging technologies, usecases, capabilities, and experiences that will make it up for the next evolution of the Internet. Several researchers have already surveyed the literature on artificial intelligence (AI) and wireless communications in realizing the Metaverse. However, due to the rapid emergence of technologies, there is a need for a comprehensive and in-depth review of the role of AI, 6G, and the nexus of both in realizing the immersive experiences of Metaverse. Therefore, in this survey, we first introduce the background and ongoing progress in augmented reality (AR), virtual reality (VR), mixed reality (MR) and spatial computing, followed by the technical aspects of AI and 6G. Then, we survey the role of AI in the Metaverse by reviewing the state-of-the-art in deep learning, computer vision, and edge AI. Next, we investigate the promising services of B5G/6G towards Metaverse, followed by identifying the role of AI in 6G networks and 6G networks for AI in support of Metaverse applications. Finally, we enlist the existing and potential applications, usecases, and projects to highlight the importance of progress in the Metaverse. Moreover, in order to provide potential research directions to researchers, we enlist the challenges, research gaps, and lessons learned identified from the literature review of the aforementioned technologies.
Multimodal-Boost: Multimodal Medical Image Super-Resolution using Multi-Attention Network with Wavelet Transform
Oct 22, 2021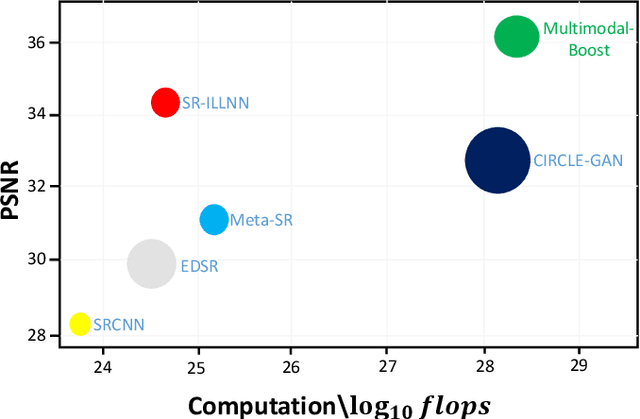
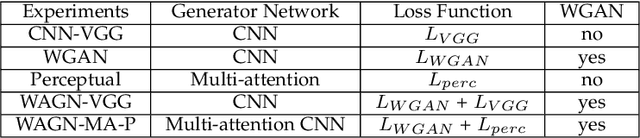
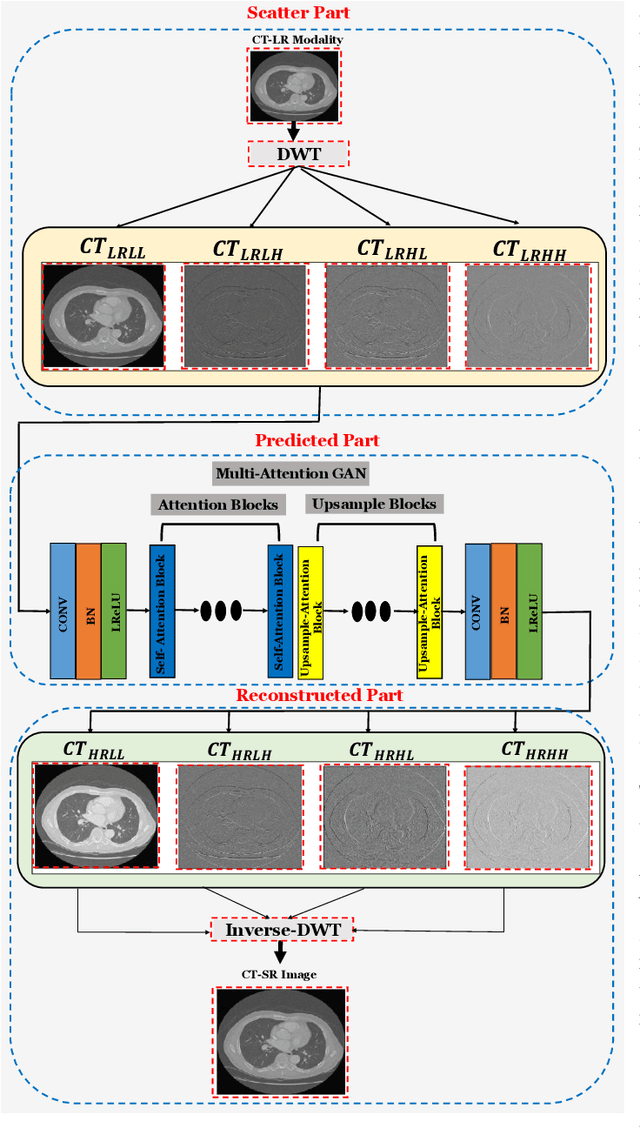

Multimodal medical images are widely used by clinicians and physicians to analyze and retrieve complementary information from high-resolution images in a non-invasive manner. The loss of corresponding image resolution degrades the overall performance of medical image diagnosis. Deep learning based single image super resolution (SISR) algorithms has revolutionized the overall diagnosis framework by continually improving the architectural components and training strategies associated with convolutional neural networks (CNN) on low-resolution images. However, existing work lacks in two ways: i) the SR output produced exhibits poor texture details, and often produce blurred edges, ii) most of the models have been developed for a single modality, hence, require modification to adapt to a new one. This work addresses (i) by proposing generative adversarial network (GAN) with deep multi-attention modules to learn high-frequency information from low-frequency data. Existing approaches based on the GAN have yielded good SR results; however, the texture details of their SR output have been experimentally confirmed to be deficient for medical images particularly. The integration of wavelet transform (WT) and GANs in our proposed SR model addresses the aforementioned limitation concerning textons. The WT divides the LR image into multiple frequency bands, while the transferred GAN utilizes multiple attention and upsample blocks to predict high-frequency components. Moreover, we present a learning technique for training a domain-specific classifier as a perceptual loss function. Combining multi-attention GAN loss with a perceptual loss function results in a reliable and efficient performance. Applying the same model for medical images from diverse modalities is challenging, our work addresses (ii) by training and performing on several modalities via transfer learning.
Data Augmentation for Graph Convolutional Network on Semi-Supervised Classification
Jun 16, 2021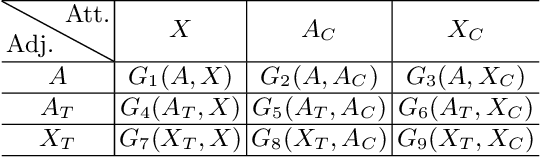
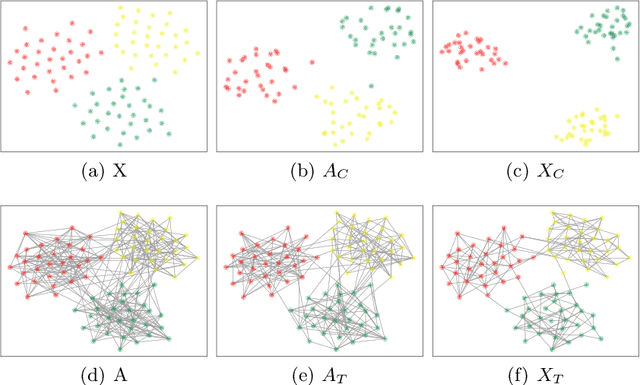
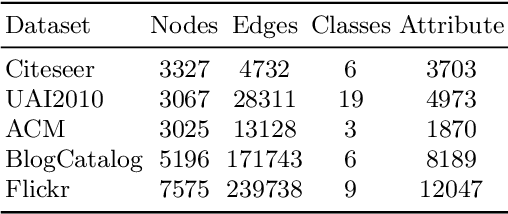
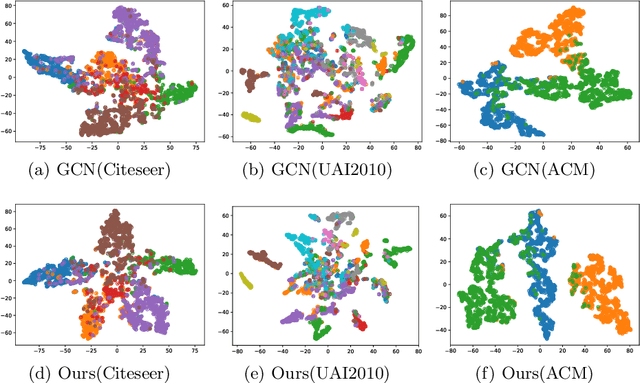
Data augmentation aims to generate new and synthetic features from the original data, which can identify a better representation of data and improve the performance and generalizability of downstream tasks. However, data augmentation for graph-based models remains a challenging problem, as graph data is more complex than traditional data, which consists of two features with different properties: graph topology and node attributes. In this paper, we study the problem of graph data augmentation for Graph Convolutional Network (GCN) in the context of improving the node embeddings for semi-supervised node classification. Specifically, we conduct cosine similarity based cross operation on the original features to create new graph features, including new node attributes and new graph topologies, and we combine them as new pairwise inputs for specific GCNs. Then, we propose an attentional integrating model to weighted sum the hidden node embeddings encoded by these GCNs into the final node embeddings. We also conduct a disparity constraint on these hidden node embeddings when training to ensure that non-redundant information is captured from different features. Experimental results on five real-world datasets show that our method improves the classification accuracy with a clear margin (+2.5% - +84.2%) than the original GCN model.
TWIST-GAN: Towards Wavelet Transform and Transferred GAN for Spatio-Temporal Single Image Super Resolution
Apr 20, 2021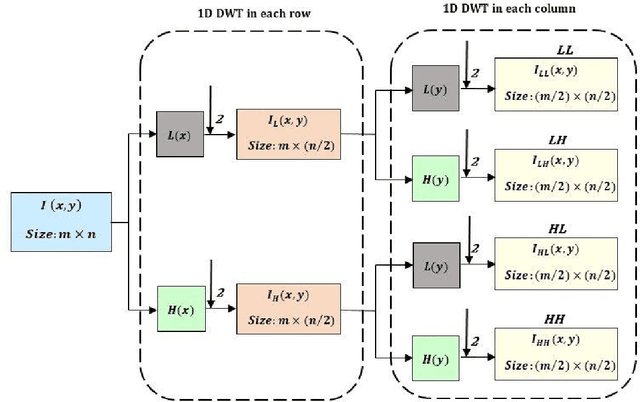
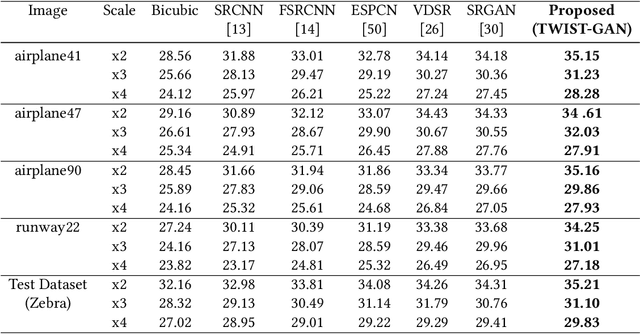

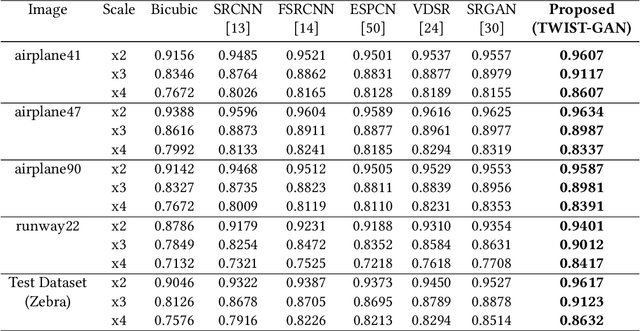
Single Image Super-resolution (SISR) produces high-resolution images with fine spatial resolutions from aremotely sensed image with low spatial resolution. Recently, deep learning and generative adversarial networks(GANs) have made breakthroughs for the challenging task of single image super-resolution (SISR). However, thegenerated image still suffers from undesirable artifacts such as, the absence of texture-feature representationand high-frequency information. We propose a frequency domain-based spatio-temporal remote sensingsingle image super-resolution technique to reconstruct the HR image combined with generative adversarialnetworks (GANs) on various frequency bands (TWIST-GAN). We have introduced a new method incorporatingWavelet Transform (WT) characteristics and transferred generative adversarial network. The LR image hasbeen split into various frequency bands by using the WT, whereas, the transfer generative adversarial networkpredicts high-frequency components via a proposed architecture. Finally, the inverse transfer of waveletsproduces a reconstructed image with super-resolution. The model is first trained on an external DIV2 Kdataset and validated with the UC Merceed Landsat remote sensing dataset and Set14 with each image sizeof 256x256. Following that, transferred GANs are used to process spatio-temporal remote sensing images inorder to minimize computation cost differences and improve texture information. The findings are comparedqualitatively and qualitatively with the current state-of-art approaches. In addition, we saved about 43% of theGPU memory during training and accelerated the execution of our simplified version by eliminating batchnormalization layers.