 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEXUS: Bit-Exact ANN-to-SNN Equivalence via Neuromorphic Gate Circuits with Surrogate-Free Training
Jan 29, 2026Spiking Neural Networks (SNNs) promise energy-efficient computing through event-driven sparsity, yet all existing approaches sacrifice accuracy by approximating continuous values with discrete spikes. We propose NEXUS, a framework that achieves bit-exact ANN-to-SNN equivalence -- not approximate, but mathematically identical outputs. Our key insight is constructing all arithmetic operations, both linear and nonlinear, from pure IF neuron logic gates that implement IEEE-754 compliant floating-point arithmetic. Through spatial bit encoding (zero encoding error by construction), hierarchical neuromorphic gate circuits (from basic logic gates to complete transformer layers), and surrogate-free STE training (exact identity mapping rather than heuristic approximation), NEXUS produces outputs identical to standard ANNs up to machine precision. Experiments on models up to LLaMA-2 70B demonstrate identical task accuracy (0.00\% degradation) with mean ULP error of only 6.19, while achieving 27-168,000$\times$ energy reduction on neuromorphic hardware. Crucially, spatial bit encoding's single-timestep design renders the framework inherently immune to membrane potential leakage (100\% accuracy across all decay factors $β\in[0.1,1.0]$), while tolerating synaptic noise up to $σ=0.2$ with >98\% gate-level accuracy.
The Native Spiking Microarchitecture: From Iontronic Primitives to Bit-Exact FP8 Arithmetic
Dec 08, 2025The 2025 Nobel Prize in Chemistry for Metal-Organic Frameworks (MOFs) and recent breakthroughs by Huanting Wang's team at Monash University establish angstrom-scale channels as promising post-silicon substrates with native integrate-and-fire (IF) dynamics. However, utilizing these stochastic, analog materials for deterministic, bit-exact AI workloads (e.g., FP8) remains a paradox. Existing neuromorphic methods often settle for approximation, failing Transformer precision standards. To traverse the gap "from stochastic ions to deterministic floats," we propose a Native Spiking Microarchitecture. Treating noisy neurons as logic primitives, we introduce a Spatial Combinational Pipeline and a Sticky-Extra Correction mechanism. Validation across all 16,129 FP8 pairs confirms 100% bit-exact alignment with PyTorch. Crucially, our architecture reduces Linear layer latency to O(log N), yielding a 17x speedup. Physical simulations further demonstrate robustness against extreme membrane leakage (beta approx 0.01), effectively immunizing the system against the stochastic nature of the hardware.
Data Augmentation for Graph Convolutional Network on Semi-Supervised Classification
Jun 16, 2021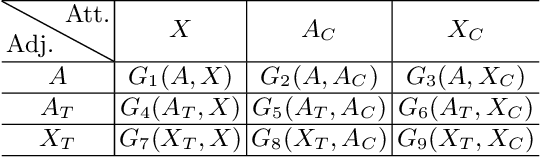
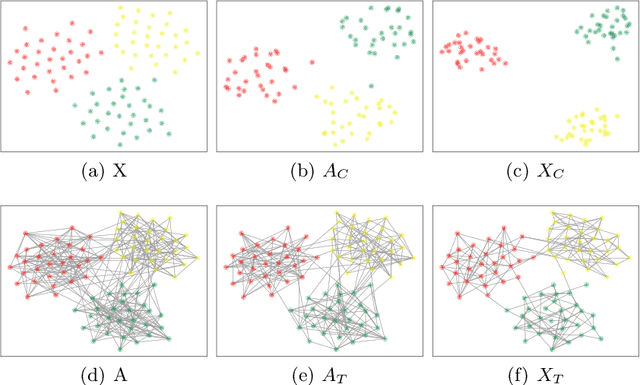
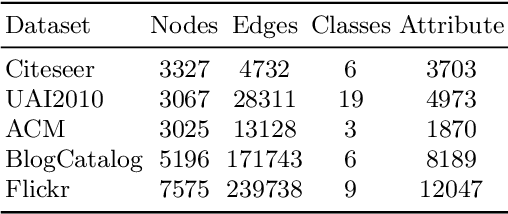
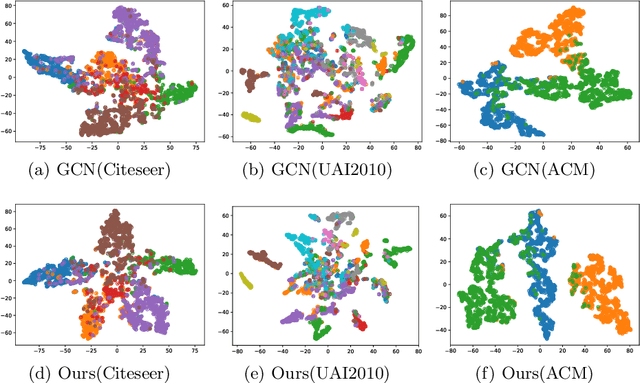
Data augmentation aims to generate new and synthetic features from the original data, which can identify a better representation of data and improve the performance and generalizability of downstream tasks. However, data augmentation for graph-based models remains a challenging problem, as graph data is more complex than traditional data, which consists of two features with different properties: graph topology and node attributes. In this paper, we study the problem of graph data augmentation for Graph Convolutional Network (GCN) in the context of improving the node embeddings for semi-supervised node classification. Specifically, we conduct cosine similarity based cross operation on the original features to create new graph features, including new node attributes and new graph topologies, and we combine them as new pairwise inputs for specific GCNs. Then, we propose an attentional integrating model to weighted sum the hidden node embeddings encoded by these GCNs into the final node embeddings. We also conduct a disparity constraint on these hidden node embeddings when training to ensure that non-redundant information is captured from different features. Experimental results on five real-world datasets show that our method improves the classification accuracy with a clear margin (+2.5% - +84.2%) than the original GCN model.