 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTING-BEE: Towards Vision-Language Model for Real-World X-ray Baggage Security Inspection
Apr 03, 2025Advancements in Computer-Aided Screening (CAS) systems are essential for improving the detection of security threats in X-ray baggage scans. However, current datasets are limited in representing real-world, sophisticated threats and concealment tactics, and existing approaches are constrained by a closed-set paradigm with predefined labels. To address these challenges, we introduce STCray, the first multimodal X-ray baggage security dataset, comprising 46,642 image-caption paired scans across 21 threat categories, generated using an X-ray scanner for airport security. STCray is meticulously developed with our specialized protocol that ensures domain-aware, coherent captions, that lead to the multi-modal instruction following data in X-ray baggage security. This allows us to train a domain-aware visual AI assistant named STING-BEE that supports a range of vision-language tasks, including scene comprehension, referring threat localization, visual grounding, and visual question answering (VQA), establishing novel baselines for multi-modal learning in X-ray baggage security. Further, STING-BEE shows state-of-the-art generalization in cross-domain settings. Code, data, and models are available at https://divs1159.github.io/STING-BEE/.
Dehazing-aided Multi-Rate Multi-Modal Pose Estimation Framework for Mitigating Visual Disturbances in Extreme Underwater Domain
Nov 21, 2024



This paper delves into the potential of DU-VIO, a dehazing-aided hybrid multi-rate multi-modal Visual-Inertial Odometry (VIO) estimation framework, designed to thrive in the challenging realm of extreme underwater environments. The cutting-edge DU-VIO framework is incorporating a GAN-based pre-processing module and a hybrid CNN-LSTM module for precise pose estimation, using visibility-enhanced underwater images and raw IMU data. Accurate pose estimation is paramount for various underwater robotics and exploration applications. However, underwater visibility is often compromised by suspended particles and attenuation effects, rendering visual-inertial pose estimation a formidable challenge. DU-VIO aims to overcome these limitations by effectively removing visual disturbances from raw image data, enhancing the quality of image features used for pose estimation. We demonstrate the effectiveness of DU-VIO by calculating RMSE scores for translation and rotation vectors in comparison to their reference values. These scores are then compared to those of a base model using a modified AQUALOC Dataset. This study's significance lies in its potential to revolutionize underwater robotics and exploration. DU-VIO offers a robust solution to the persistent challenge of underwater visibility, significantly improving the accuracy of pose estimation. This research contributes valuable insights and tools for advancing underwater technology, with far-reaching implications for scientific research, environmental monitoring, and industrial applications.
Integrating Features for Recognizing Human Activities through Optimized Parameters in Graph Convolutional Networks and Transformer Architectures
Aug 29, 2024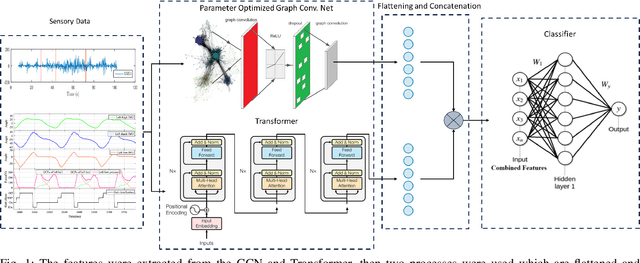
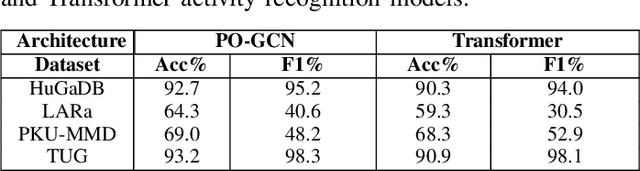
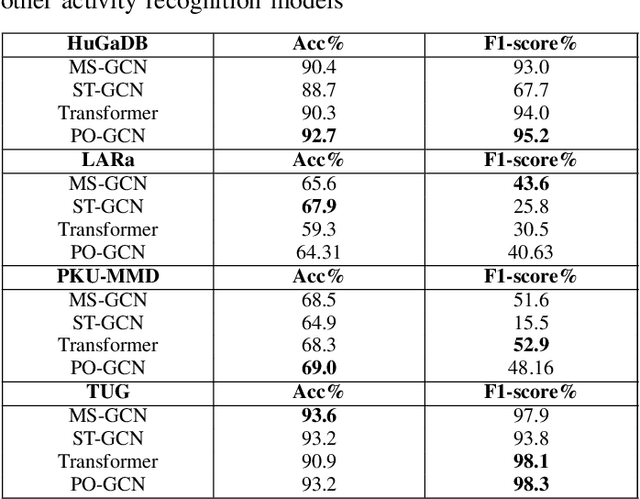

Human activity recognition is a major field of study that employs computer vision, machine vision, and deep learning techniques to categorize human actions. The field of deep learning has made significant progress, with architectures that are extremely effective at capturing human dynamics. This study emphasizes the influence of feature fusion on the accuracy of activity recognition. This technique addresses the limitation of conventional models, which face difficulties in identifying activities because of their limited capacity to understand spatial and temporal features. The technique employs sensory data obtained from four publicly available datasets: HuGaDB, PKU-MMD, LARa, and TUG. The accuracy and F1-score of two deep learning models, specifically a Transformer model and a Parameter-Optimized Graph Convolutional Network (PO-GCN), were evaluated using these datasets. The feature fusion technique integrated the final layer features from both models and inputted them into a classifier. Empirical evidence demonstrates that PO-GCN outperforms standard models in activity recognition. HuGaDB demonstrated a 2.3% improvement in accuracy and a 2.2% increase in F1-score. TUG showed a 5% increase in accuracy and a 0.5% rise in F1-score. On the other hand, LARa and PKU-MMD achieved lower accuracies of 64% and 69% respectively. This indicates that the integration of features enhanced the performance of both the Transformer model and PO-GCN.
Feature Fusion for Human Activity Recognition using Parameter-Optimized Multi-Stage Graph Convolutional Network and Transformer Models
Jun 24, 2024Human activity recognition (HAR) is a crucial area of research that involves understanding human movements using computer and machine vision technology. Deep learning has emerged as a powerful tool for this task, with models such as Convolutional Neural Networks (CNNs) and Transformers being employed to capture various aspects of human motion. One of the key contributions of this work is the demonstration of the effectiveness of feature fusion in improving HAR accuracy by capturing spatial and temporal features, which has important implications for the development of more accurate and robust activity recognition systems. The study uses sensory data from HuGaDB, PKU-MMD, LARa, and TUG datasets. Two model, the PO-MS-GCN and a Transformer were trained and evaluated, with PO-MS-GCN outperforming state-of-the-art models. HuGaDB and TUG achieved high accuracies and f1-scores, while LARa and PKU-MMD had lower scores. Feature fusion improved results across datasets.
A Comprehensive Review of Artificial Intelligence Applications in Major Retinal Conditions
Nov 22, 2023
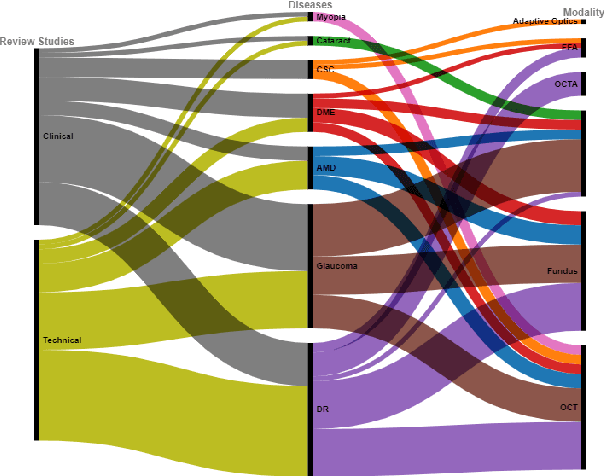
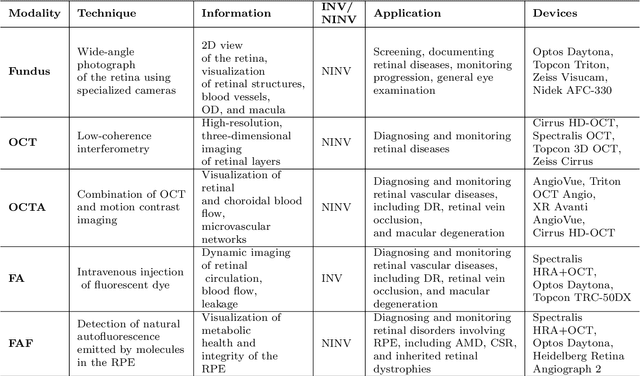
This paper provides a systematic survey of retinal diseases that cause visual impairments or blindness, emphasizing the importance of early detection for effective treatment. It covers both clinical and automated approaches for detecting retinal disease, focusing on studies from the past decade. The survey evaluates various algorithms for identifying structural abnormalities and diagnosing retinal diseases, and it identifies future research directions based on a critical analysis of existing literature. This comprehensive study, which reviews both clinical and automated detection methods using different modalities, appears to be unique in its scope. Additionally, the survey serves as a helpful guide for researchers interested in digital retinopathy.
Vision-Based Autonomous Navigation for Unmanned Surface Vessel in Extreme Marine Conditions
Aug 08, 2023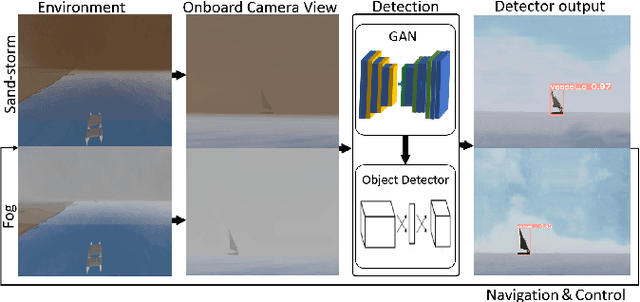
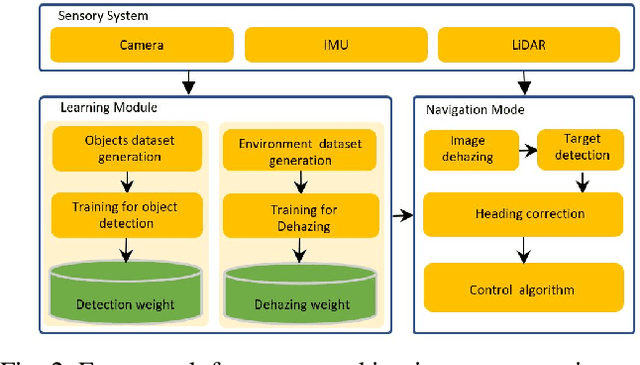

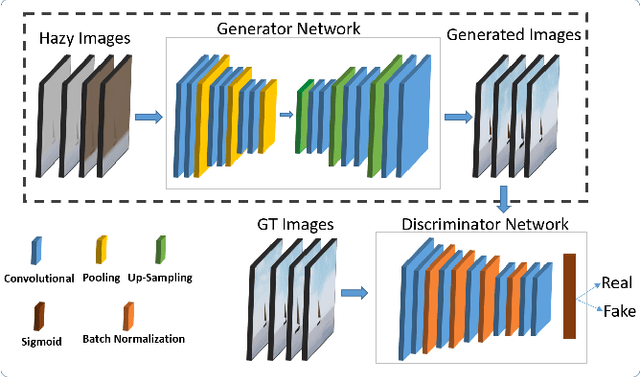
Visual perception is an important component for autonomous navigation of unmanned surface vessels (USV), particularly for the tasks related to autonomous inspection and tracking. These tasks involve vision-based navigation techniques to identify the target for navigation. Reduced visibility under extreme weather conditions in marine environments makes it difficult for vision-based approaches to work properly. To overcome these issues, this paper presents an autonomous vision-based navigation framework for tracking target objects in extreme marine conditions. The proposed framework consists of an integrated perception pipeline that uses a generative adversarial network (GAN) to remove noise and highlight the object features before passing them to the object detector (i.e., YOLOv5). The detected visual features are then used by the USV to track the target. The proposed framework has been thoroughly tested in simulation under extremely reduced visibility due to sandstorms and fog. The results are compared with state-of-the-art de-hazing methods across the benchmarked MBZIRC simulation dataset, on which the proposed scheme has outperformed the existing methods across various metrics.
Convolutional Transformer for Autonomous Recognition and Grading of Tomatoes Under Various Lighting, Occlusion, and Ripeness Conditions
Jul 04, 2023Harvesting fully ripe tomatoes with mobile robots presents significant challenges in real-world scenarios. These challenges arise from factors such as occlusion caused by leaves and branches, as well as the color similarity between tomatoes and the surrounding foliage during the fruit development stage. The natural environment further compounds these issues with varying light conditions, viewing angles, occlusion factors, and different maturity levels. To overcome these obstacles, this research introduces a novel framework that leverages a convolutional transformer architecture to autonomously recognize and grade tomatoes, irrespective of their occlusion level, lighting conditions, and ripeness. The proposed model is trained and tested using carefully annotated images curated specifically for this purpose. The dataset is prepared under various lighting conditions, viewing perspectives, and employs different mobile camera sensors, distinguishing it from existing datasets such as Laboro Tomato and Rob2Pheno Annotated Tomato. The effectiveness of the proposed framework in handling cluttered and occluded tomato instances was evaluated using two additional public datasets, Laboro Tomato and Rob2Pheno Annotated Tomato, as benchmarks. The evaluation results across these three datasets demonstrate the exceptional performance of our proposed framework, surpassing the state-of-the-art by 58.14%, 65.42%, and 66.39% in terms of mean average precision scores for KUTomaData, Laboro Tomato, and Rob2Pheno Annotated Tomato, respectively. The results underscore the superiority of the proposed model in accurately detecting and delineating tomatoes compared to baseline methods and previous approaches. Specifically, the model achieves an F1-score of 80.14%, a Dice coefficient of 73.26%, and a mean IoU of 66.41% on the KUTomaData image dataset.
An Incremental Learning Approach to Automatically Recognize Pulmonary Diseases from the Multi-vendor Chest Radiographs
Jan 14, 2022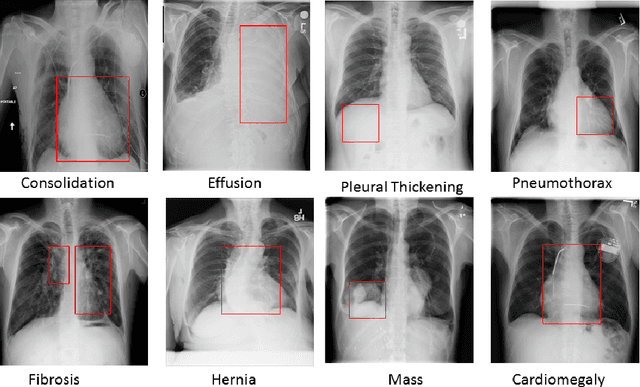
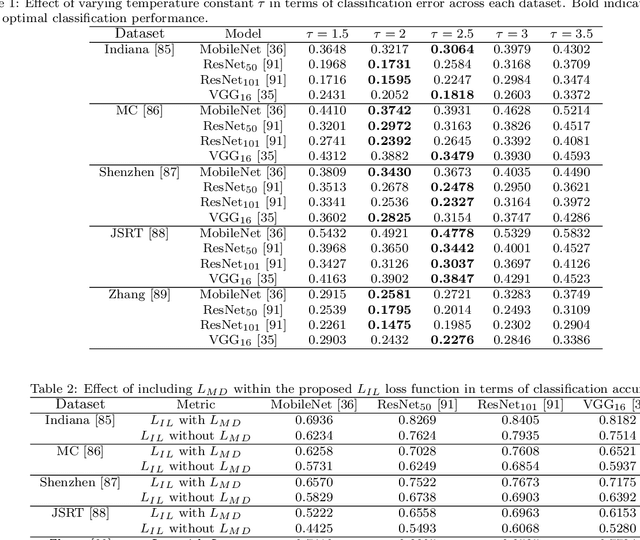
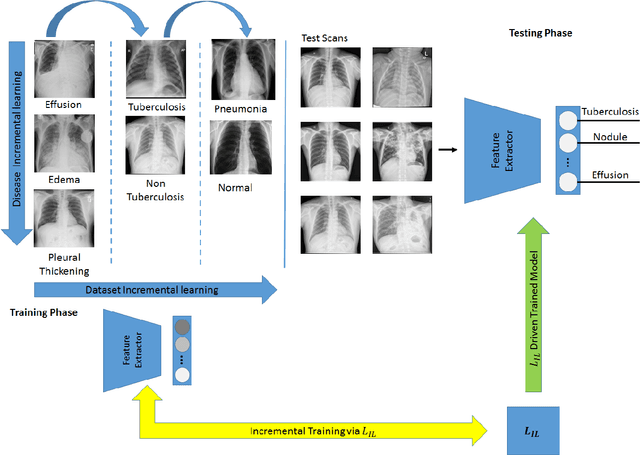
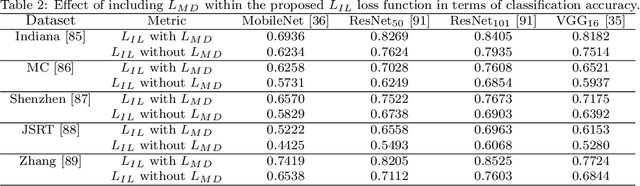
Pulmonary diseases can cause severe respiratory problems, leading to sudden death if not treated timely. Many researchers have utilized deep learning systems to diagnose pulmonary disorders using chest X-rays (CXRs). However, such systems require exhaustive training efforts on large-scale data to effectively diagnose chest abnormalities. Furthermore, procuring such large-scale data is often infeasible and impractical, especially for rare diseases. With the recent advances in incremental learning, researchers have periodically tuned deep neural networks to learn different classification tasks with few training examples. Although, such systems can resist catastrophic forgetting, they treat the knowledge representations independently of each other, and this limits their classification performance. Also, to the best of our knowledge, there is no incremental learning-driven image diagnostic framework that is specifically designed to screen pulmonary disorders from the CXRs. To address this, we present a novel framework that can learn to screen different chest abnormalities incrementally. In addition to this, the proposed framework is penalized through an incremental learning loss function that infers Bayesian theory to recognize structural and semantic inter-dependencies between incrementally learned knowledge representations to diagnose the pulmonary diseases effectively, regardless of the scanner specifications. We tested the proposed framework on five public CXR datasets containing different chest abnormalities, where it outperformed various state-of-the-art system through various metrics.
* Computers in Biology and Medicine
A Novel Incremental Learning Driven Instance Segmentation Framework to Recognize Highly Cluttered Instances of the Contraband Items
Jan 10, 2022
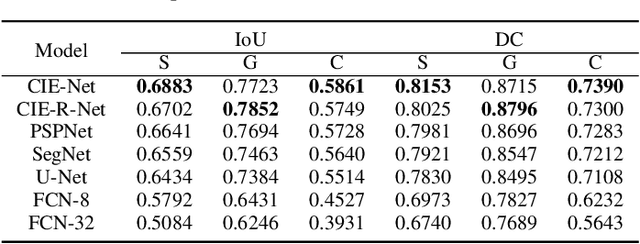
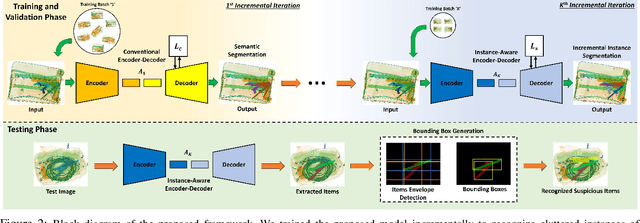
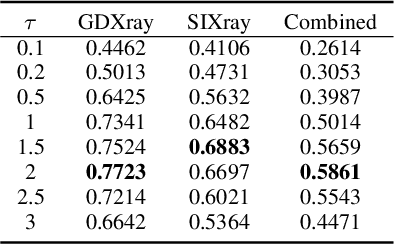
Screening cluttered and occluded contraband items from baggage X-ray scans is a cumbersome task even for the expert security staff. This paper presents a novel strategy that extends a conventional encoder-decoder architecture to perform instance-aware segmentation and extract merged instances of contraband items without using any additional sub-network or an object detector. The encoder-decoder network first performs conventional semantic segmentation and retrieves cluttered baggage items. The model then incrementally evolves during training to recognize individual instances using significantly reduced training batches. To avoid catastrophic forgetting, a novel objective function minimizes the network loss in each iteration by retaining the previously acquired knowledge while learning new class representations and resolving their complex structural inter-dependencies through Bayesian inference. A thorough evaluation of our framework on two publicly available X-ray datasets shows that it outperforms state-of-the-art methods, especially within the challenging cluttered scenarios, while achieving an optimal trade-off between detection accuracy and efficiency.
* IEEE Transactions on Systems, Man, and Cybernetics: Systems, Source code is available at https://github.com/taimurhassan/inc-inst-seg
Temporal Fusion Based Mutli-scale Semantic Segmentation for Detecting Concealed Baggage Threats
Nov 07, 2021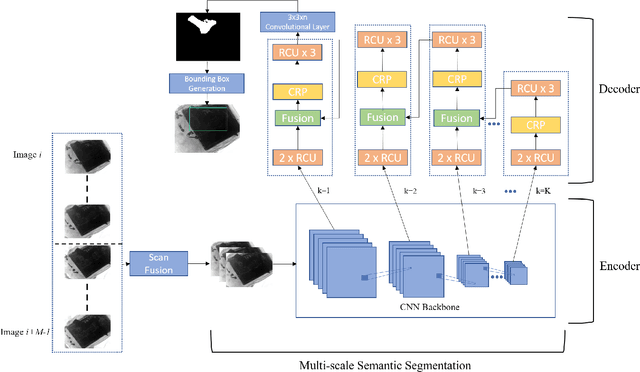
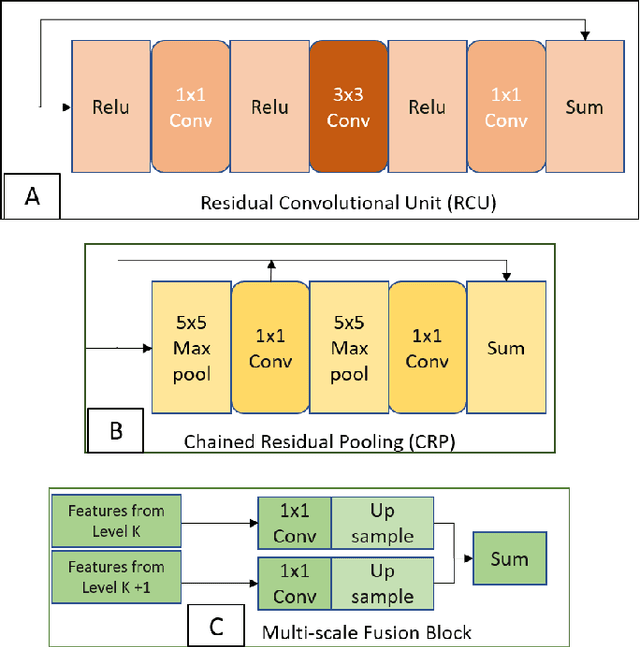

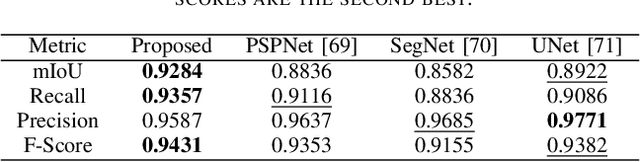
Detection of illegal and threatening items in baggage is one of the utmost security concern nowadays. Even for experienced security personnel, manual detection is a time-consuming and stressful task. Many academics have created automated frameworks for detecting suspicious and contraband data from X-ray scans of luggage. However, to our knowledge, no framework exists that utilizes temporal baggage X-ray imagery to effectively screen highly concealed and occluded objects which are barely visible even to the naked eye. To address this, we present a novel temporal fusion driven multi-scale residual fashioned encoder-decoder that takes series of consecutive scans as input and fuses them to generate distinct feature representations of the suspicious and non-suspicious baggage content, leading towards a more accurate extraction of the contraband data. The proposed methodology has been thoroughly tested using the publicly accessible GDXray dataset, which is the only dataset containing temporally linked grayscale X-ray scans showcasing extremely concealed contraband data. The proposed framework outperforms its competitors on the GDXray dataset on various metrics.