 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTING-BEE: Towards Vision-Language Model for Real-World X-ray Baggage Security Inspection
Apr 03, 2025Advancements in Computer-Aided Screening (CAS) systems are essential for improving the detection of security threats in X-ray baggage scans. However, current datasets are limited in representing real-world, sophisticated threats and concealment tactics, and existing approaches are constrained by a closed-set paradigm with predefined labels. To address these challenges, we introduce STCray, the first multimodal X-ray baggage security dataset, comprising 46,642 image-caption paired scans across 21 threat categories, generated using an X-ray scanner for airport security. STCray is meticulously developed with our specialized protocol that ensures domain-aware, coherent captions, that lead to the multi-modal instruction following data in X-ray baggage security. This allows us to train a domain-aware visual AI assistant named STING-BEE that supports a range of vision-language tasks, including scene comprehension, referring threat localization, visual grounding, and visual question answering (VQA), establishing novel baselines for multi-modal learning in X-ray baggage security. Further, STING-BEE shows state-of-the-art generalization in cross-domain settings. Code, data, and models are available at https://divs1159.github.io/STING-BEE/.
Discriminative Kernel Convolution Network for Multi-Label Ophthalmic Disease Detection on Imbalanced Fundus Image Dataset
Jul 16, 2022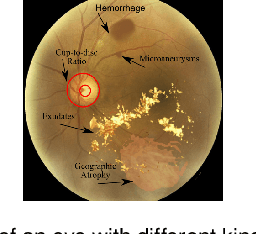
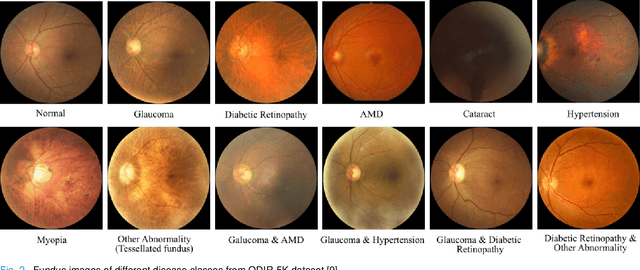

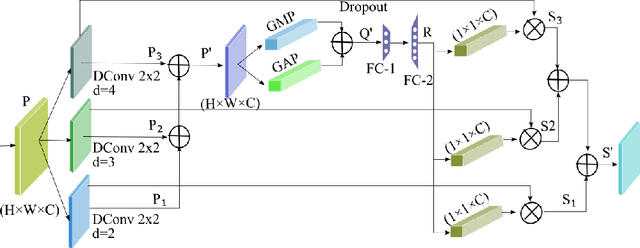
It is feasible to recognize the presence and seriousness of eye disease by investigating the progressions in retinal biological structure. Fundus examination is a diagnostic procedure to examine the biological structure and anomaly of the eye. Ophthalmic diseases like glaucoma, diabetic retinopathy, and cataract are the main reason for visual impairment around the world. Ocular Disease Intelligent Recognition (ODIR-5K) is a benchmark structured fundus image dataset utilized by researchers for multi-label multi-disease classification of fundus images. This work presents a discriminative kernel convolution network (DKCNet), which explores discriminative region-wise features without adding extra computational cost. DKCNet is composed of an attention block followed by a squeeze and excitation (SE) block. The attention block takes features from the backbone network and generates discriminative feature attention maps. The SE block takes the discriminative feature maps and improves channel interdependencies. Better performance of DKCNet is observed with InceptionResnet backbone network for multi-label classification of ODIR-5K fundus images with 96.08 AUC, 94.28 F1-score and 0.81 kappa score. The proposed method splits the common target label for an eye pair based on the diagnostic keyword. Based on these labels oversampling and undersampling is done to resolve class imbalance. To check the biasness of proposed model towards training data, the model trained on ODIR dataset is tested on three publicly available benchmark datasets. It is found to give good performance on completely unseen fundus images also.