 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Trajectory Prediction via Late Fusion
Apr 24, 2026Predicting future trajectories of surrounding traffic agents is critical for safe autonomous navigation and collision avoidance. Despite all advances in the trajectory forecasting realm, the prediction models remains vulnerable to uncertainty caused by occlusions, limited sensing range, and perception errors. Collaborative vehicle-to-vehicle (V2V) approaches help reduce this uncertainty by sharing complementary information. Existing collaborative trajectory prediction methods typically fuse feature maps at the perception stage to construct a holistic scene view. Further this holistic representation is decoded into the future trajectories. Such design incurs substantial communication overhead due to the exchange of high-dimensional feature representations and often assumes idealized bandwidth and synchronization, limiting practical deployment. We address these limitations by shifting collaboration from perception to the prediction module and introducing a late-fusion framework for shared forecasts. The framework is model-agnostic and treats collaborating vehicles as independent asynchronous agents. We evaluate the approach on the OPV2V, V2V4Real, and DeepAccident datasets, comparing individual and collaborative forecasting. Across all datasets, late fusion consistently reduces miss rate and improves trajectory success rate ($\mathrm{TSR}_{0.5}$), defined as the fraction of ground-truth agents with final displacement error below 0.5 m. On the real-world V2V4Real dataset, collaborative prediction improves the success rate by $1.69\%$ and $1.22\%$ for both intelligent vehicles, respectively, compared with individual forecasting.
Climate Adaptation-Aware Flood Prediction for Coastal Cities Using Deep Learning
Oct 29, 2025Climate change and sea-level rise (SLR) pose escalating threats to coastal cities, intensifying the need for efficient and accurate methods to predict potential flood hazards. Traditional physics-based hydrodynamic simulators, although precise, are computationally expensive and impractical for city-scale coastal planning applications. Deep Learning (DL) techniques offer promising alternatives, however, they are often constrained by challenges such as data scarcity and high-dimensional output requirements. Leveraging a recently proposed vision-based, low-resource DL framework, we develop a novel, lightweight Convolutional Neural Network (CNN)-based model designed to predict coastal flooding under variable SLR projections and shoreline adaptation scenarios. Furthermore, we demonstrate the ability of the model to generalize across diverse geographical contexts by utilizing datasets from two distinct regions: Abu Dhabi and San Francisco. Our findings demonstrate that the proposed model significantly outperforms state-of-the-art methods, reducing the mean absolute error (MAE) in predicted flood depth maps on average by nearly 20%. These results highlight the potential of our approach to serve as a scalable and practical tool for coastal flood management, empowering decision-makers to develop effective mitigation strategies in response to the growing impacts of climate change. Project Page: https://caspiannet.github.io/
Towards Accurate State Estimation: Kalman Filter Incorporating Motion Dynamics for 3D Multi-Object Tracking
May 12, 2025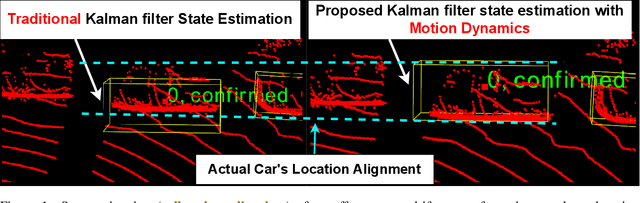
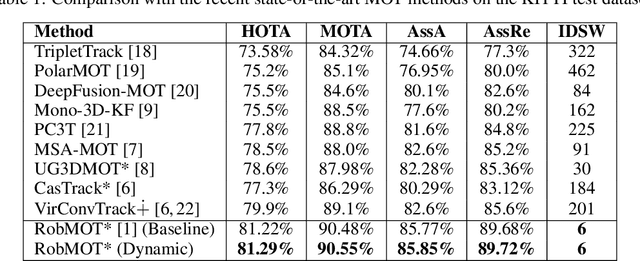
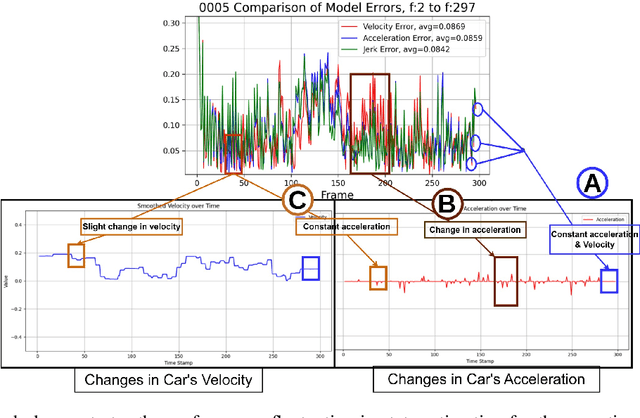
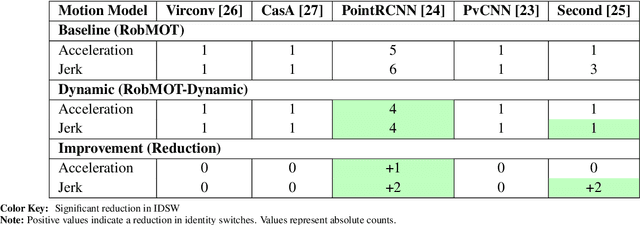
This work addresses the critical lack of precision in state estimation in the Kalman filter for 3D multi-object tracking (MOT) and the ongoing challenge of selecting the appropriate motion model. Existing literature commonly relies on constant motion models for estimating the states of objects, neglecting the complex motion dynamics unique to each object. Consequently, trajectory division and imprecise object localization arise, especially under occlusion conditions. The core of these challenges lies in the limitations of the current Kalman filter formulation, which fails to account for the variability of motion dynamics as objects navigate their environments. This work introduces a novel formulation of the Kalman filter that incorporates motion dynamics, allowing the motion model to adaptively adjust according to changes in the object's movement. The proposed Kalman filter substantially improves state estimation, localization, and trajectory prediction compared to the traditional Kalman filter. This is reflected in tracking performance that surpasses recent benchmarks on the KITTI and Waymo Open Datasets, with margins of 0.56\% and 0.81\% in higher order tracking accuracy (HOTA) and multi-object tracking accuracy (MOTA), respectively. Furthermore, the proposed Kalman filter consistently outperforms the baseline across various detectors. Additionally, it shows an enhanced capability in managing long occlusions compared to the baseline Kalman filter, achieving margins of 1.22\% in higher order tracking accuracy (HOTA) and 1.55\% in multi-object tracking accuracy (MOTA) on the KITTI dataset. The formulation's efficiency is evident, with an additional processing time of only approximately 0.078 ms per frame, ensuring its applicability in real-time applications.
EMT: A Visual Multi-Task Benchmark Dataset for Autonomous Driving in the Arab Gulf Region
Feb 26, 2025

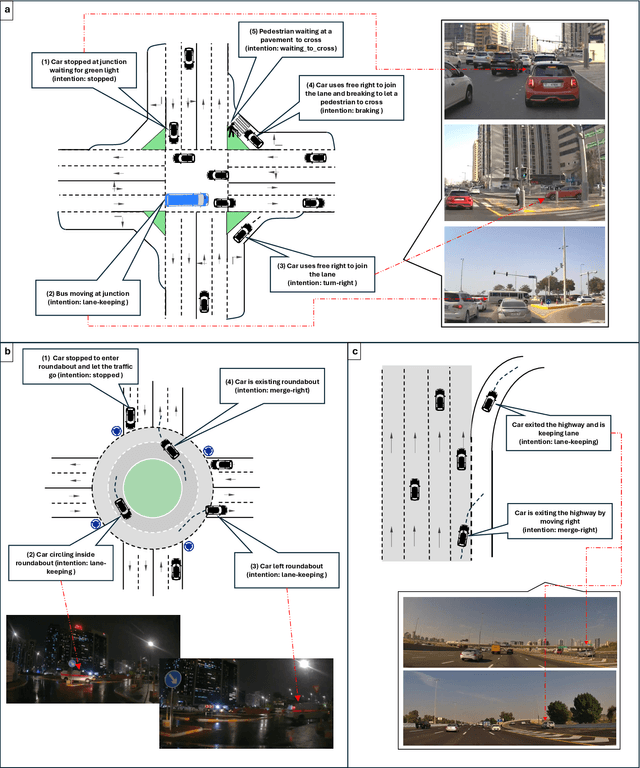

This paper introduces the Emirates Multi-Task (EMT) dataset - the first publicly available dataset for autonomous driving collected in the Arab Gulf region. The EMT dataset captures the unique road topology, high traffic congestion, and distinctive characteristics of the Gulf region, including variations in pedestrian clothing and weather conditions. It contains over 30,000 frames from a dash-camera perspective, along with 570,000 annotated bounding boxes, covering approximately 150 kilometers of driving routes. The EMT dataset supports three primary tasks: tracking, trajectory forecasting and intention prediction. Each benchmark dataset is complemented with corresponding evaluations: (1) multi-agent tracking experiments, focusing on multi-class scenarios and occlusion handling; (2) trajectory forecasting evaluation using deep sequential and interaction-aware models; and (3) intention benchmark experiments conducted for predicting agents intentions from observed trajectories. The dataset is publicly available at https://avlab.io/emt-dataset, and pre-processing scripts along with evaluation models can be accessed at https://github.com/AV-Lab/emt-dataset.
Media Forensics and Deepfake Systematic Survey
Jun 19, 2024Deepfake is a generative deep learning algorithm that creates or changes facial features in a very realistic way making it hard to differentiate the real from the fake features It can be used to make movies look better as well as to spread false information by imitating famous people In this paper many different ways to make a Deepfake are explained analyzed and separated categorically Using Deepfake datasets models are trained and tested for reliability through experiments Deepfakes are a type of facial manipulation that allow people to change their entire faces identities attributes and expressions The trends in the available Deepfake datasets are also discussed with a focus on how they have changed Using Deep learning a general Deepfake detection model is made Moreover the problems in making and detecting Deepfakes are also mentioned As a result of this survey it is expected that the development of new Deepfake based imaging tools will speed up in the future This survey gives indepth review of methods for manipulating images of face and various techniques to spot altered face images Four types of facial manipulation are specifically discussed which are attribute manipulation expression swap entire face synthesis and identity swap Across every manipulation category we yield information on manipulation techniques significant benchmarks for technical evaluation of counterfeit detection techniques available public databases and a summary of the outcomes of all such analyses From all of the topics in the survey we focus on the most recent development of Deepfake showing its advances and obstacles in detecting fake images
RobMOT: Robust 3D Multi-Object Tracking by Observational Noise and State Estimation Drift Mitigation on LiDAR PointCloud
May 19, 2024
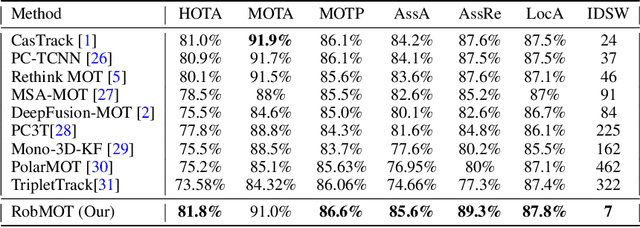
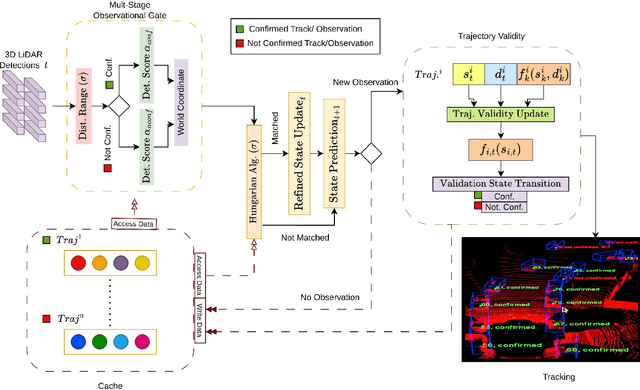
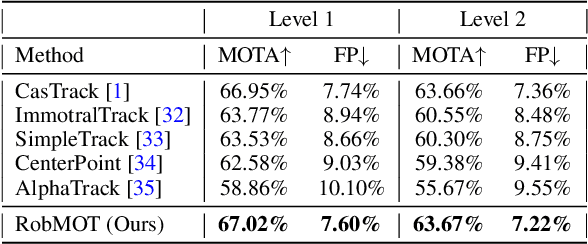
This work addresses the inherited limitations in the current state-of-the-art 3D multi-object tracking (MOT) methods that follow the tracking-by-detection paradigm, notably trajectory estimation drift for long-occluded objects in LiDAR point cloud streams acquired by autonomous cars. In addition, the absence of adequate track legitimacy verification results in ghost track accumulation. To tackle these issues, we introduce a two-fold innovation. Firstly, we propose refinement in Kalman filter that enhances trajectory drift noise mitigation, resulting in more robust state estimation for occluded objects. Secondly, we propose a novel online track validity mechanism to distinguish between legitimate and ghost tracks combined with a multi-stage observational gating process for incoming observations. This mechanism substantially reduces ghost tracks by up to 80\% and improves HOTA by 7\%. Accordingly, we propose an online 3D MOT framework, RobMOT, that demonstrates superior performance over the top-performing state-of-the-art methods, including deep learning approaches, across various detectors with up to 3.28\% margin in MOTA and 2.36\% in HOTA. RobMOT excels under challenging conditions, such as prolonged occlusions and the tracking of distant objects, with up to 59\% enhancement in processing latency.
A Comprehensive Review of Artificial Intelligence Applications in Major Retinal Conditions
Nov 22, 2023
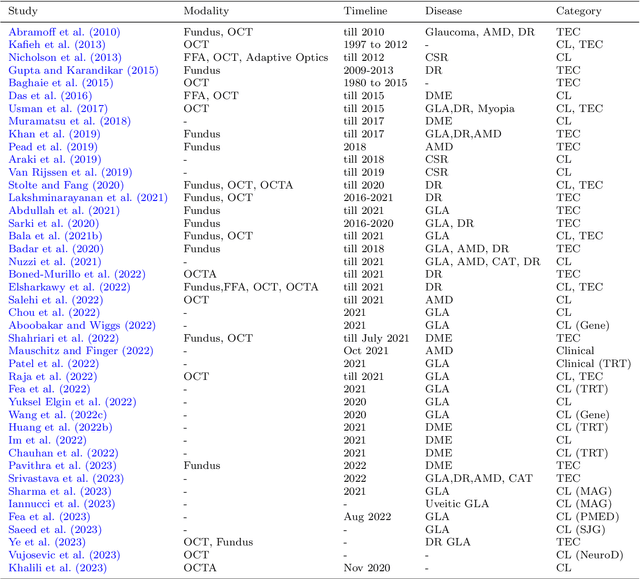
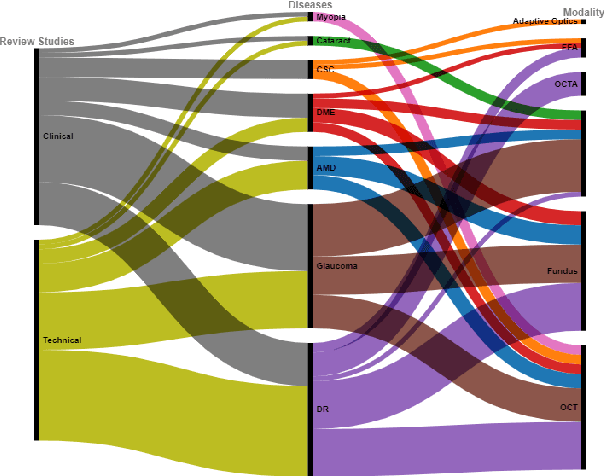
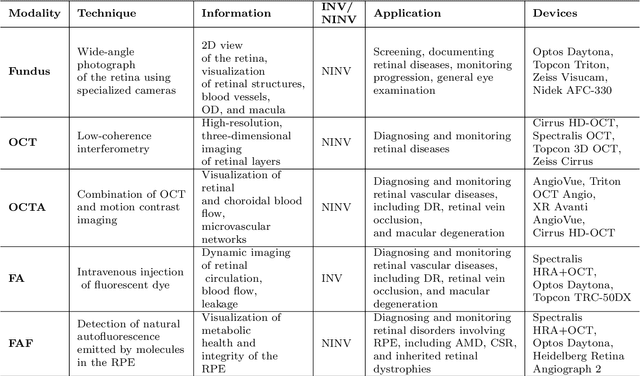
This paper provides a systematic survey of retinal diseases that cause visual impairments or blindness, emphasizing the importance of early detection for effective treatment. It covers both clinical and automated approaches for detecting retinal disease, focusing on studies from the past decade. The survey evaluates various algorithms for identifying structural abnormalities and diagnosing retinal diseases, and it identifies future research directions based on a critical analysis of existing literature. This comprehensive study, which reviews both clinical and automated detection methods using different modalities, appears to be unique in its scope. Additionally, the survey serves as a helpful guide for researchers interested in digital retinopathy.
Incremental Cross-Domain Adaptation for Robust Retinopathy Screening via Bayesian Deep Learning
Nov 04, 2021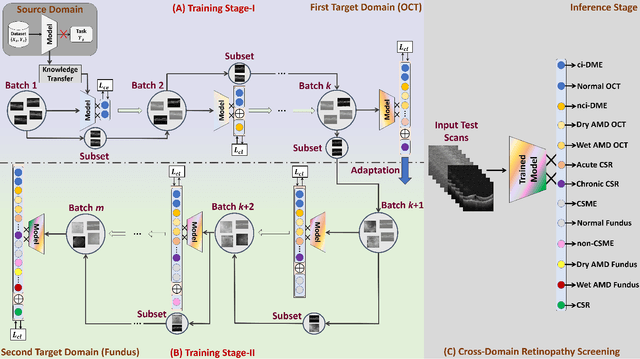
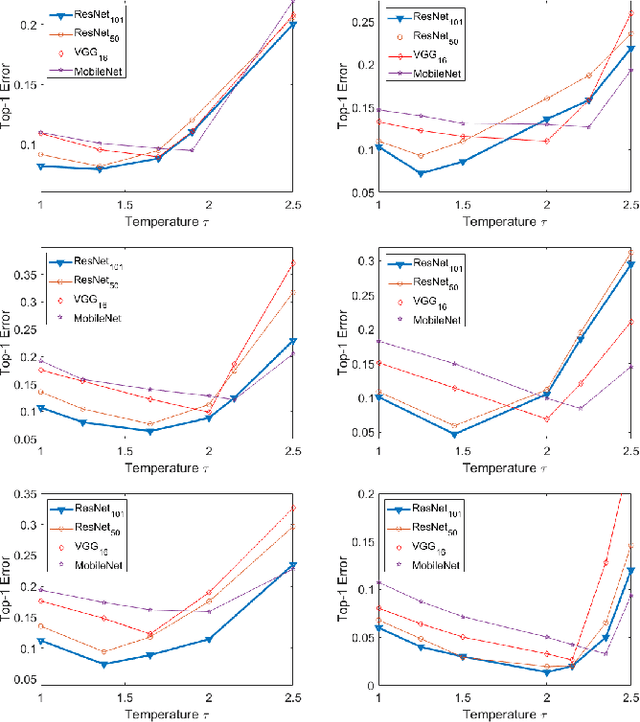
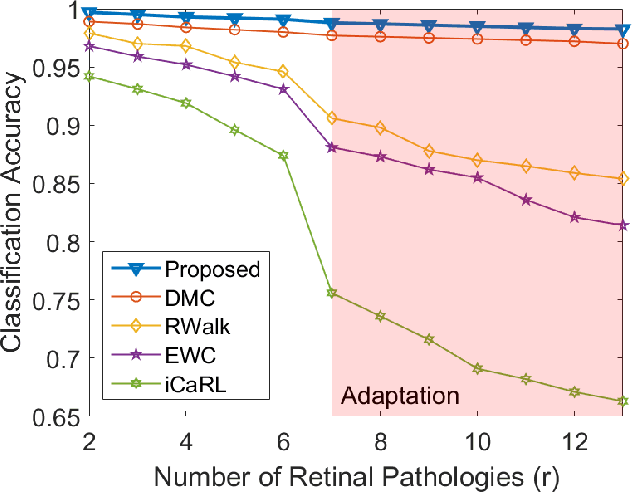
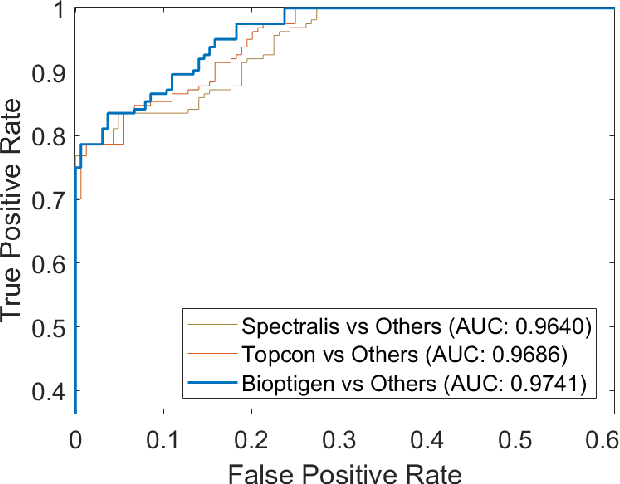
Retinopathy represents a group of retinal diseases that, if not treated timely, can cause severe visual impairments or even blindness. Many researchers have developed autonomous systems to recognize retinopathy via fundus and optical coherence tomography (OCT) imagery. However, most of these frameworks employ conventional transfer learning and fine-tuning approaches, requiring a decent amount of well-annotated training data to produce accurate diagnostic performance. This paper presents a novel incremental cross-domain adaptation instrument that allows any deep classification model to progressively learn abnormal retinal pathologies in OCT and fundus imagery via few-shot training. Furthermore, unlike its competitors, the proposed instrument is driven via a Bayesian multi-objective function that not only enforces the candidate classification network to retain its prior learned knowledge during incremental training but also ensures that the network understands the structural and semantic relationships between previously learned pathologies and newly added disease categories to effectively recognize them at the inference stage. The proposed framework, evaluated on six public datasets acquired with three different scanners to screen thirteen retinal pathologies, outperforms the state-of-the-art competitors by achieving an overall accuracy and F1 score of 0.9826 and 0.9846, respectively.
* Accepted in IEEE Transactions on Instrumentation and Measurement. Source code is available at https://github.com/taimurhassan/continual_learning/
Automated segmentation and extraction of posterior eye segment using OCT scans
Sep 21, 2021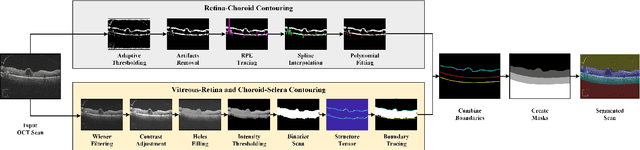


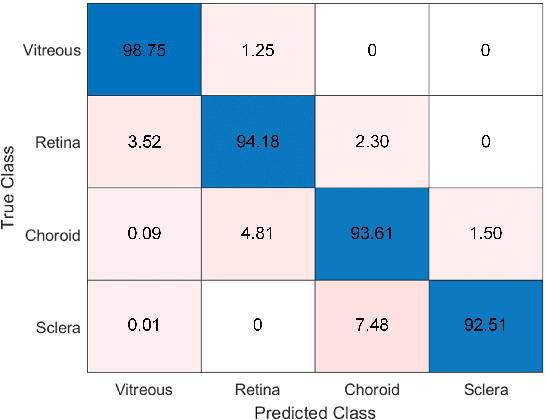
This paper proposes an automated method for the segmentation and extraction of the posterior segment of the human eye, including the vitreous, retina, choroid, and sclera compartments, using multi-vendor optical coherence tomography (OCT) scans. The proposed method works in two phases. First extracts the retinal pigment epithelium (RPE) layer by applying the adaptive thresholding technique to identify the retina-choroid junction. Then, it exploits the structure tensor guided approach to extract the inner limiting membrane (ILM) and the choroidal stroma (CS) layers, locating the vitreous-retina and choroid-sclera junctions in the candidate OCT scan. Furthermore, these three junction boundaries are utilized to conduct posterior eye compartmentalization effectively for both healthy and disease eye OCT scans. The proposed framework is evaluated over 1000 OCT scans, where it obtained the mean intersection over union (IoU) and mean Dice similarity coefficient (DSC) scores of 0.874 and 0.930, respectively.
SIP-SegNet: A Deep Convolutional Encoder-Decoder Network for Joint Semantic Segmentation and Extraction of Sclera, Iris and Pupil based on Periocular Region Suppression
Feb 15, 2020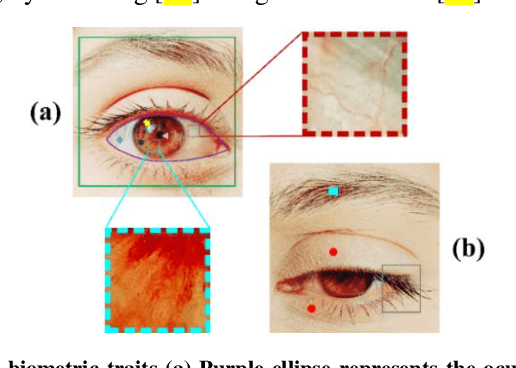
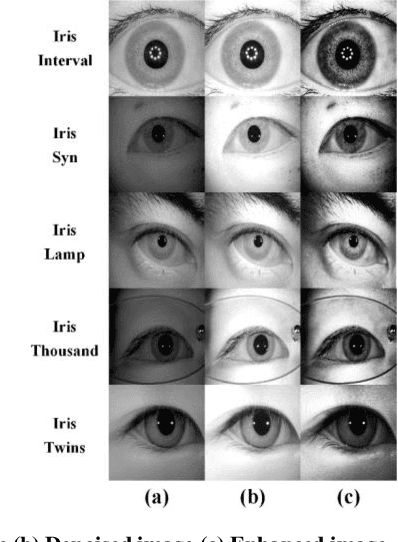
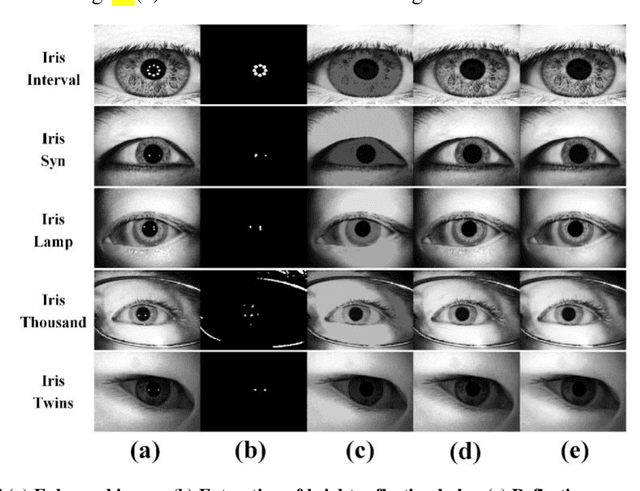
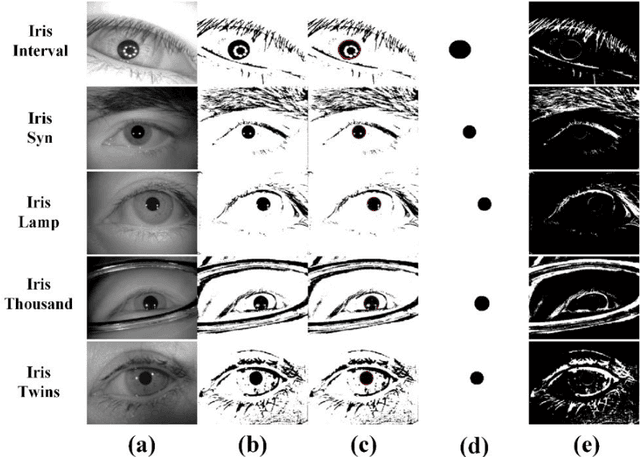
The current developments in the field of machine vision have opened new vistas towards deploying multimodal biometric recognition systems in various real-world applications. These systems have the ability to deal with the limitations of unimodal biometric systems which are vulnerable to spoofing, noise, non-universality and intra-class variations. In addition, the ocular traits among various biometric traits are preferably used in these recognition systems. Such systems possess high distinctiveness, permanence, and performance while, technologies based on other biometric traits (fingerprints, voice etc.) can be easily compromised. This work presents a novel deep learning framework called SIP-SegNet, which performs the joint semantic segmentation of ocular traits (sclera, iris and pupil) in unconstrained scenarios with greater accuracy. The acquired images under these scenarios exhibit purkinje reflexes, specular reflections, eye gaze, off-angle shots, low resolution, and various occlusions particularly by eyelids and eyelashes. To address these issues, SIP-SegNet begins with denoising the pristine image using denoising convolutional neural network (DnCNN), followed by reflection removal and image enhancement based on contrast limited adaptive histogram equalization (CLAHE). Our proposed framework then extracts the periocular information using adaptive thresholding and employs the fuzzy filtering technique to suppress this information. Finally, the semantic segmentation of sclera, iris and pupil is achieved using the densely connected fully convolutional encoder-decoder network. We used five CASIA datasets to evaluate the performance of SIP-SegNet based on various evaluation metrics. The simulation results validate the optimal segmentation of the proposed SIP-SegNet, with the mean f1 scores of 93.35, 95.11 and 96.69 for the sclera, iris and pupil classes respectively.