 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRBPGAN: Recurrent Back-Projection GAN for Video Super Resolution
Nov 24, 2023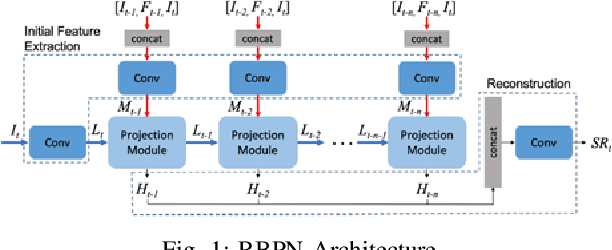
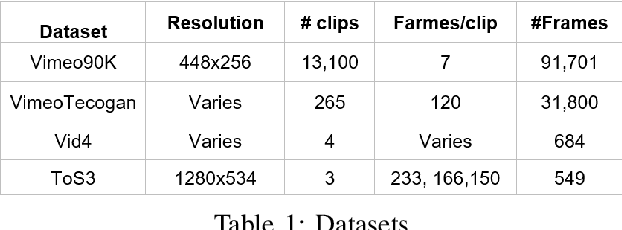
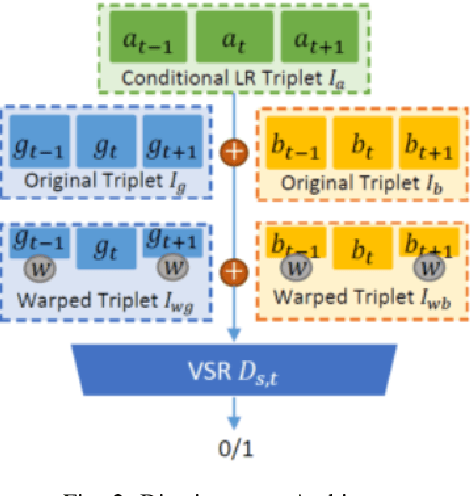
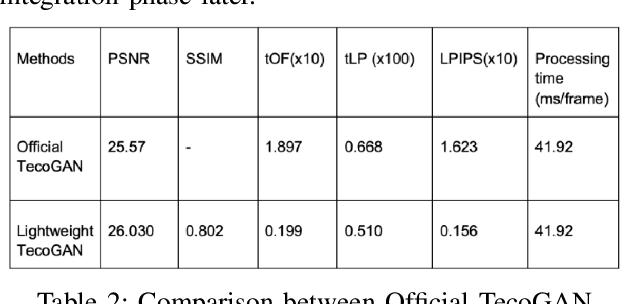
Recently, video super resolution (VSR) has become a very impactful task in the area of Computer Vision due to its various applications. In this paper, we propose Recurrent Back-Projection Generative Adversarial Network (RBPGAN) for VSR in an attempt to generate temporally coherent solutions while preserving spatial details. RBPGAN integrates two state-of-the-art models to get the best in both worlds without compromising the accuracy of produced video. The generator of the model is inspired by RBPN system, while the discriminator is inspired by TecoGAN. We also utilize Ping-Pong loss to increase temporal consistency over time. Our contribution together results in a model that outperforms earlier work in terms of temporally consistent details, as we will demonstrate qualitatively and quantitatively using different datasets.
Convolutional Transformer for Autonomous Recognition and Grading of Tomatoes Under Various Lighting, Occlusion, and Ripeness Conditions
Jul 04, 2023Harvesting fully ripe tomatoes with mobile robots presents significant challenges in real-world scenarios. These challenges arise from factors such as occlusion caused by leaves and branches, as well as the color similarity between tomatoes and the surrounding foliage during the fruit development stage. The natural environment further compounds these issues with varying light conditions, viewing angles, occlusion factors, and different maturity levels. To overcome these obstacles, this research introduces a novel framework that leverages a convolutional transformer architecture to autonomously recognize and grade tomatoes, irrespective of their occlusion level, lighting conditions, and ripeness. The proposed model is trained and tested using carefully annotated images curated specifically for this purpose. The dataset is prepared under various lighting conditions, viewing perspectives, and employs different mobile camera sensors, distinguishing it from existing datasets such as Laboro Tomato and Rob2Pheno Annotated Tomato. The effectiveness of the proposed framework in handling cluttered and occluded tomato instances was evaluated using two additional public datasets, Laboro Tomato and Rob2Pheno Annotated Tomato, as benchmarks. The evaluation results across these three datasets demonstrate the exceptional performance of our proposed framework, surpassing the state-of-the-art by 58.14%, 65.42%, and 66.39% in terms of mean average precision scores for KUTomaData, Laboro Tomato, and Rob2Pheno Annotated Tomato, respectively. The results underscore the superiority of the proposed model in accurately detecting and delineating tomatoes compared to baseline methods and previous approaches. Specifically, the model achieves an F1-score of 80.14%, a Dice coefficient of 73.26%, and a mean IoU of 66.41% on the KUTomaData image dataset.