 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Right Losses for the Right Gains: Improving the Semantic Consistency of Deep Text-to-Image Generation with Distribution-Sensitive Losses
Dec 18, 2023One of the major challenges in training deep neural networks for text-to-image generation is the significant linguistic discrepancy between ground-truth captions of each image in most popular datasets. The large difference in the choice of words in such captions results in synthesizing images that are semantically dissimilar to each other and to their ground-truth counterparts. Moreover, existing models either fail to generate the fine-grained details of the image or require a huge number of parameters that renders them inefficient for text-to-image synthesis. To fill this gap in the literature, we propose using the contrastive learning approach with a novel combination of two loss functions: fake-to-fake loss to increase the semantic consistency between generated images of the same caption, and fake-to-real loss to reduce the gap between the distributions of real images and fake ones. We test this approach on two baseline models: SSAGAN and AttnGAN (with style blocks to enhance the fine-grained details of the images.) Results show that our approach improves the qualitative results on AttnGAN with style blocks on the CUB dataset. Additionally, on the challenging COCO dataset, our approach achieves competitive results against the state-of-the-art Lafite model, outperforms the FID score of SSAGAN model by 44.
RBPGAN: Recurrent Back-Projection GAN for Video Super Resolution
Nov 24, 2023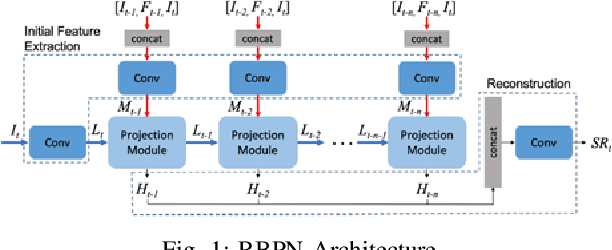
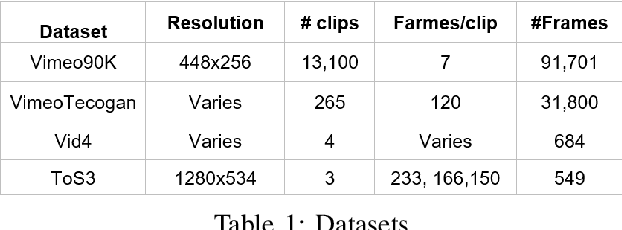
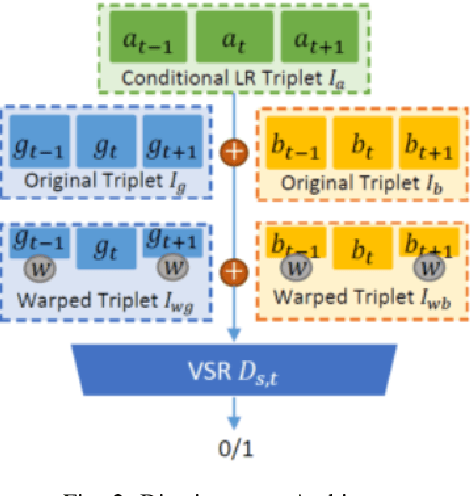
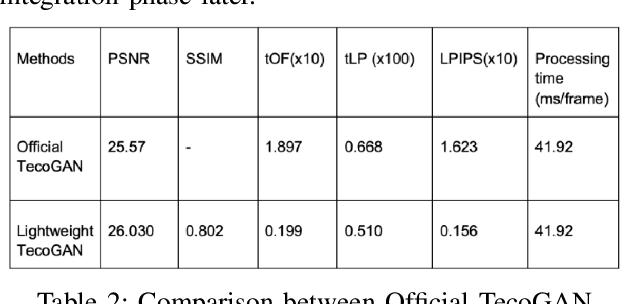
Recently, video super resolution (VSR) has become a very impactful task in the area of Computer Vision due to its various applications. In this paper, we propose Recurrent Back-Projection Generative Adversarial Network (RBPGAN) for VSR in an attempt to generate temporally coherent solutions while preserving spatial details. RBPGAN integrates two state-of-the-art models to get the best in both worlds without compromising the accuracy of produced video. The generator of the model is inspired by RBPN system, while the discriminator is inspired by TecoGAN. We also utilize Ping-Pong loss to increase temporal consistency over time. Our contribution together results in a model that outperforms earlier work in terms of temporally consistent details, as we will demonstrate qualitatively and quantitatively using different datasets.
Reactive Collision Avoidance using Evolutionary Neural Networks
Sep 27, 2016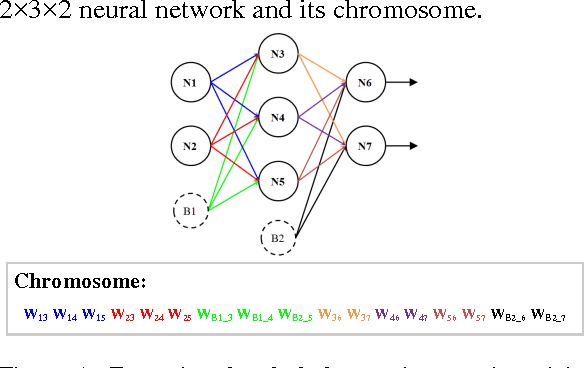
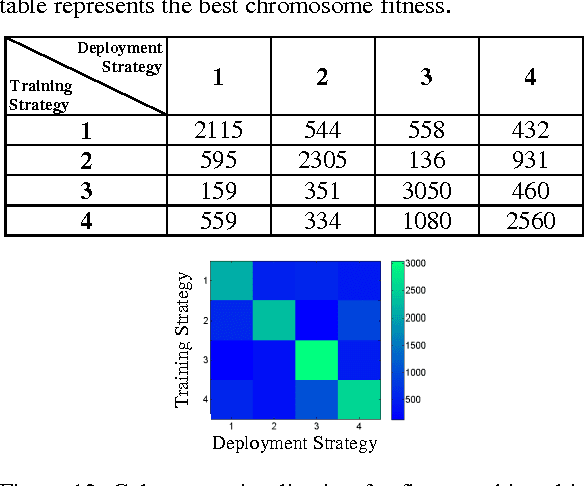
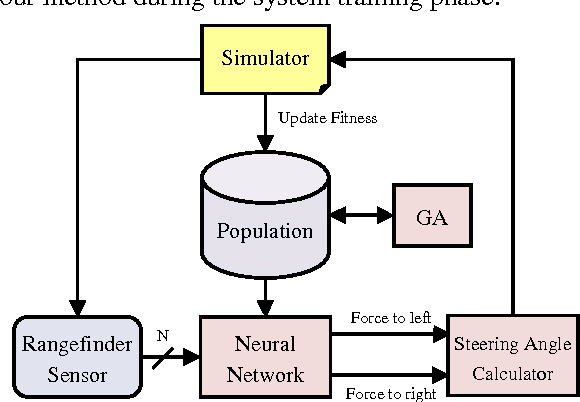
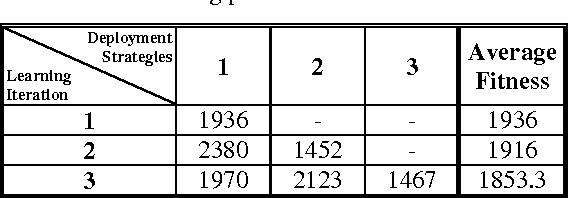
Collision avoidance systems can play a vital role in reducing the number of accidents and saving human lives. In this paper, we introduce and validate a novel method for vehicles reactive collision avoidance using evolutionary neural networks (ENN). A single front-facing rangefinder sensor is the only input required by our method. The training process and the proposed method analysis and validation are carried out using simulation. Extensive experiments are conducted to analyse the proposed method and evaluate its performance. Firstly, we experiment the ability to learn collision avoidance in a static free track. Secondly, we analyse the effect of the rangefinder sensor resolution on the learning process. Thirdly, we experiment the ability of a vehicle to individually and simultaneously learn collision avoidance. Finally, we test the generality of the proposed method. We used a more realistic and powerful simulation environment (CarMaker), a camera as an alternative input sensor, and lane keeping as an extra feature to learn. The results are encouraging; the proposed method successfully allows vehicles to learn collision avoidance in different scenarios that are unseen during training. It also generalizes well if any of the input sensor, the simulator, or the task to be learned is changed.