 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContactless Cardiac Pulse Monitoring Using Event Cameras
May 14, 2025Time event cameras are a novel technology for recording scene information at extremely low latency and with low power consumption. Event cameras output a stream of events that encapsulate pixel-level light intensity changes within the scene, capturing information with a higher dynamic range and temporal resolution than traditional cameras. This study investigates the contact-free reconstruction of an individual's cardiac pulse signal from time event recording of their face using a supervised convolutional neural network (CNN) model. An end-to-end model is trained to extract the cardiac signal from a two-dimensional representation of the event stream, with model performance evaluated based on the accuracy of the calculated heart rate. The experimental results confirm that physiological cardiac information in the facial region is effectively preserved within the event stream, showcasing the potential of this novel sensor for remote heart rate monitoring. The model trained on event frames achieves a root mean square error (RMSE) of 3.32 beats per minute (bpm) compared to the RMSE of 2.92 bpm achieved by the baseline model trained on standard camera frames. Furthermore, models trained on event frames generated at 60 and 120 FPS outperformed the 30 FPS standard camera results, achieving an RMSE of 2.54 and 2.13 bpm, respectively.
Real-Time Hand Gesture Recognition: Integrating Skeleton-Based Data Fusion and Multi-Stream CNN
Jun 21, 2024This study focuses on Hand Gesture Recognition (HGR), which is vital for perceptual computing across various real-world contexts. The primary challenge in the HGR domain lies in dealing with the individual variations inherent in human hand morphology. To tackle this challenge, we introduce an innovative HGR framework that combines data-level fusion and an Ensemble Tuner Multi-stream CNN architecture. This approach effectively encodes spatiotemporal gesture information from the skeleton modality into RGB images, thereby minimizing noise while improving semantic gesture comprehension. Our framework operates in real-time, significantly reducing hardware requirements and computational complexity while maintaining competitive performance on benchmark datasets such as SHREC2017, DHG1428, FPHA, LMDHG and CNR. This improvement in HGR demonstrates robustness and paves the way for practical, real-time applications that leverage resource-limited devices for human-machine interaction and ambient intelligence.
The Right Losses for the Right Gains: Improving the Semantic Consistency of Deep Text-to-Image Generation with Distribution-Sensitive Losses
Dec 18, 2023One of the major challenges in training deep neural networks for text-to-image generation is the significant linguistic discrepancy between ground-truth captions of each image in most popular datasets. The large difference in the choice of words in such captions results in synthesizing images that are semantically dissimilar to each other and to their ground-truth counterparts. Moreover, existing models either fail to generate the fine-grained details of the image or require a huge number of parameters that renders them inefficient for text-to-image synthesis. To fill this gap in the literature, we propose using the contrastive learning approach with a novel combination of two loss functions: fake-to-fake loss to increase the semantic consistency between generated images of the same caption, and fake-to-real loss to reduce the gap between the distributions of real images and fake ones. We test this approach on two baseline models: SSAGAN and AttnGAN (with style blocks to enhance the fine-grained details of the images.) Results show that our approach improves the qualitative results on AttnGAN with style blocks on the CUB dataset. Additionally, on the challenging COCO dataset, our approach achieves competitive results against the state-of-the-art Lafite model, outperforms the FID score of SSAGAN model by 44.
Dataset Creation Pipeline for Camera-Based Heart Rate Estimation
Mar 02, 2023Heart rate is one of the most vital health metrics which can be utilized to investigate and gain intuitions into various human physiological and psychological information. Estimating heart rate without the constraints of contact-based sensors thus presents itself as a very attractive field of research as it enables well-being monitoring in a wider variety of scenarios. Consequently, various techniques for camera-based heart rate estimation have been developed ranging from classical image processing to convoluted deep learning models and architectures. At the heart of such research efforts lies health and visual data acquisition, cleaning, transformation, and annotation. In this paper, we discuss how to prepare data for the task of developing or testing an algorithm or machine learning model for heart rate estimation from images of facial regions. The data prepared is to include camera frames as well as sensor readings from an electrocardiograph sensor. The proposed pipeline is divided into four main steps, namely removal of faulty data, frame and electrocardiograph timestamp de-jittering, signal denoising and filtering, and frame annotation creation. Our main contributions are a novel technique of eliminating jitter from health sensor and camera timestamps and a method to accurately time align both visual frame and electrocardiogram sensor data which is also applicable to other sensor types.
Pervasive Hand Gesture Recognition for Smartphones using Non-audible Sound and Deep Learning
Aug 04, 2021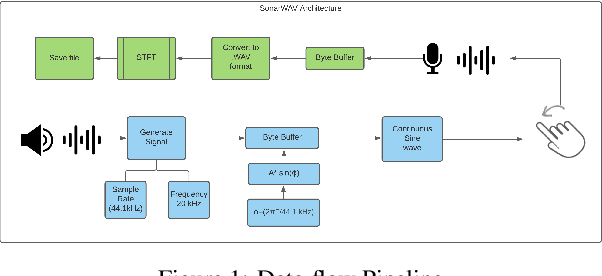
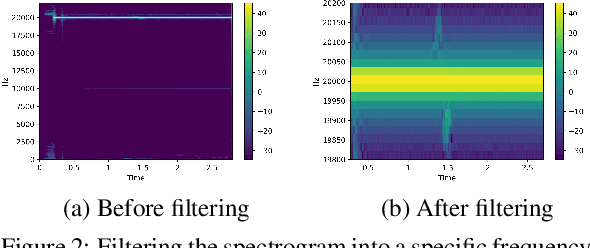
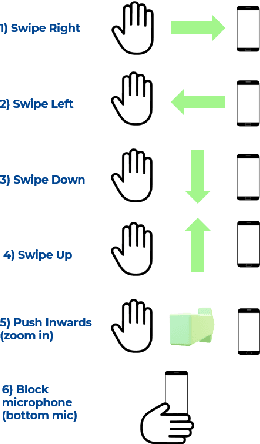
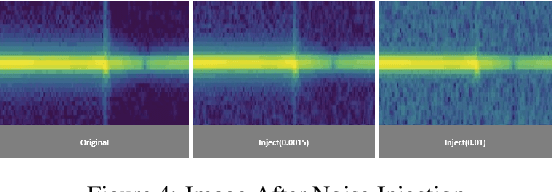
Due to the mass advancement in ubiquitous technologies nowadays, new pervasive methods have come into the practice to provide new innovative features and stimulate the research on new human-computer interactions. This paper presents a hand gesture recognition method that utilizes the smartphone's built-in speakers and microphones. The proposed system emits an ultrasonic sonar-based signal (inaudible sound) from the smartphone's stereo speakers, which is then received by the smartphone's microphone and processed via a Convolutional Neural Network (CNN) for Hand Gesture Recognition. Data augmentation techniques are proposed to improve the detection accuracy and three dual-channel input fusion methods are compared. The first method merges the dual-channel audio as a single input spectrogram image. The second method adopts early fusion by concatenating the dual-channel spectrograms. The third method adopts late fusion by having two convectional input branches processing each of the dual-channel spectrograms and then the outputs are merged by the last layers. Our experimental results demonstrate a promising detection accuracy for the six gestures presented in our publicly available dataset with an accuracy of 93.58\% as a baseline.
Enhanced 3D Myocardial Strain Estimation from Multi-View 2D CMR Imaging
Sep 25, 2020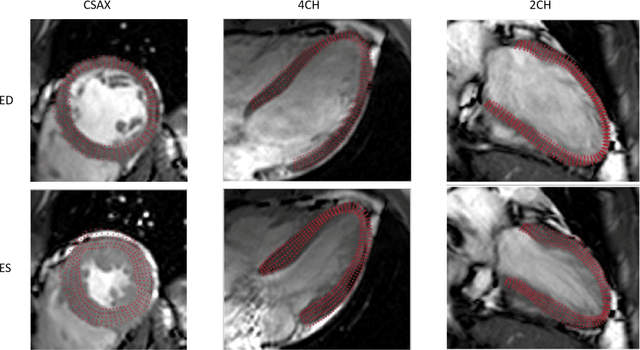
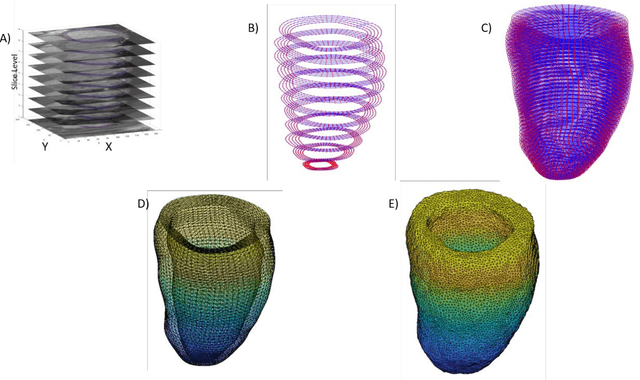
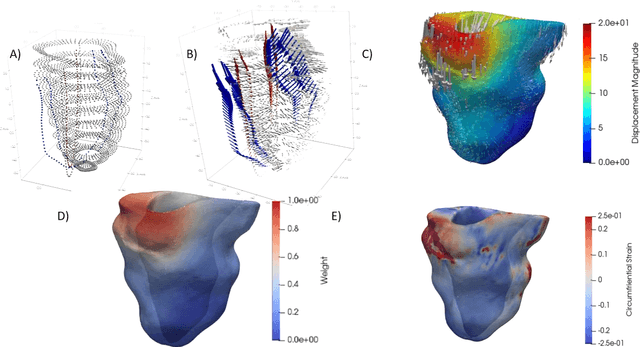
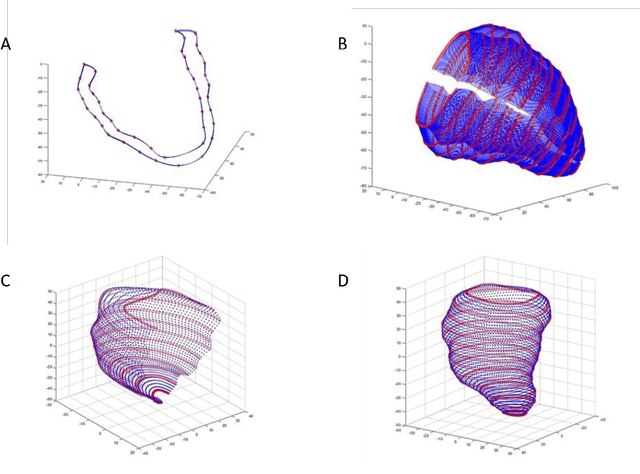
In this paper, we propose an enhanced 3D myocardial strain estimation procedure which combines complementary displacement information from multiple orientations of a single imaging modality (untagged CMR SSFP images). To estimate myocardial strain across the left ventricle, we register the sets of short-axis, four-chamber and twochamber views via a 2D non-rigid registration algorithm implemented in a commercial software (Segment, Medviso). We then create a series of interpolating functions for the three orthogonal directions of motion and use them to deform a tetrahedral mesh representation of a patient-specific left ventricle. Additionally, we correct for overestimation of displacement by introducing a weighting scheme that is based on displacement along the long axis. The procedure was evaluated on the STACOM 2011 dataset containing CMR SSFP images for 16 healthy volunteers. We show increased accuracy in estimating the three strain components (radial, circumferential, longitudinal) compared to reported results in the challenge, for the imaging modality of interest (SSFP). Our peak strain estimates are also significantly closer to reported measurements from studies of a larger cohort in the literature. Our proposed procedure provides a fast way to accurately reconstruct a deforming patient-specific model of the left ventricle using the commonest imaging modality routinely administered in clinical settings, without requiring additional or specialized imaging protocols.
A Hybrid Deep Learning Approach for Texture Analysis
Mar 24, 2017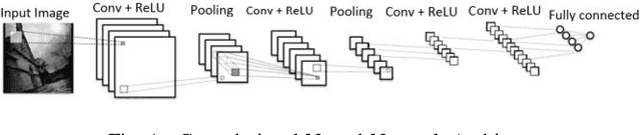
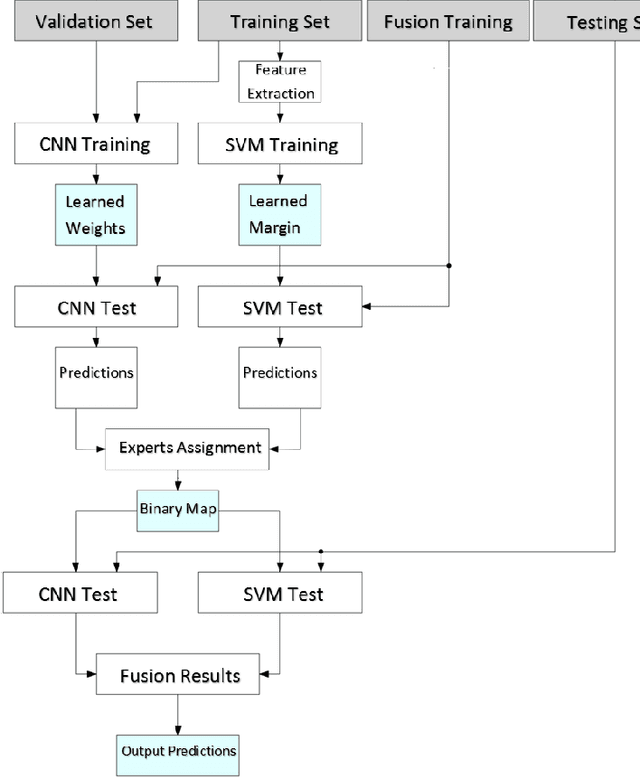
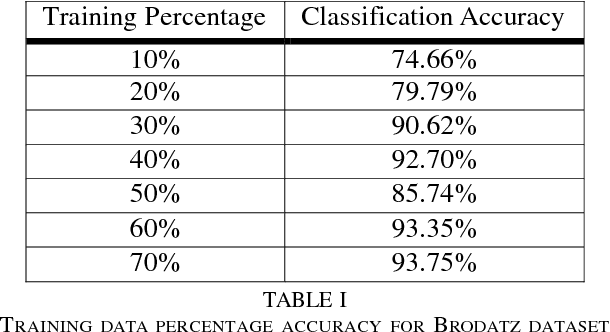
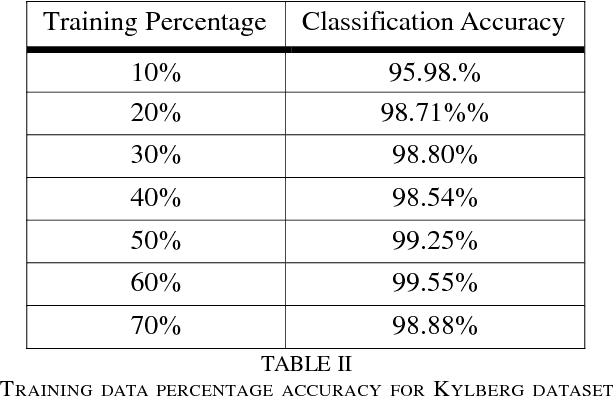
Texture classification is a problem that has various applications such as remote sensing and forest species recognition. Solutions tend to be custom fit to the dataset used but fails to generalize. The Convolutional Neural Network (CNN) in combination with Support Vector Machine (SVM) form a robust selection between powerful invariant feature extractor and accurate classifier. The fusion of experts provides stability in classification rates among different datasets.
CIFAR-10: KNN-based Ensemble of Classifiers
Nov 15, 2016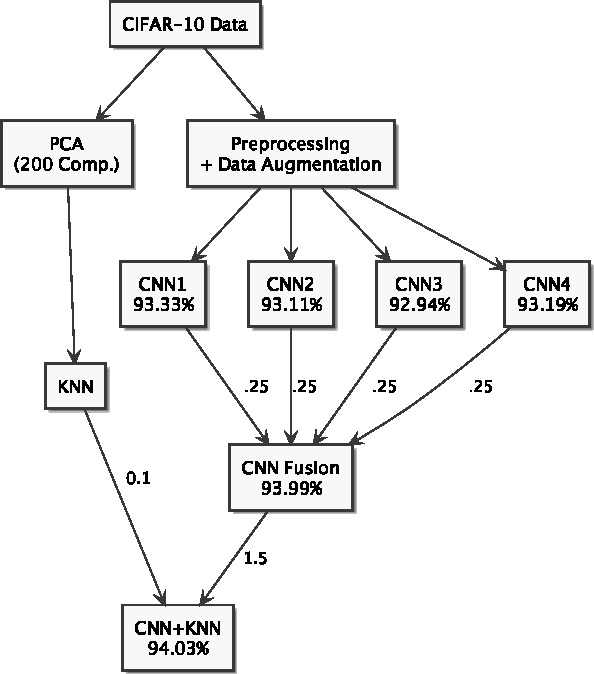


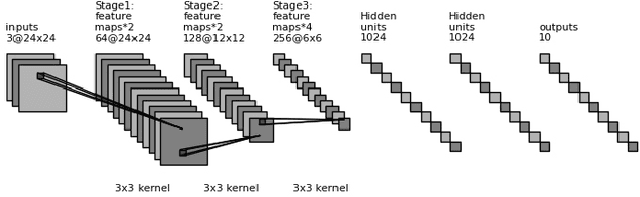
In this paper, we study the performance of different classifiers on the CIFAR-10 dataset, and build an ensemble of classifiers to reach a better performance. We show that, on CIFAR-10, K-Nearest Neighbors (KNN) and Convolutional Neural Network (CNN), on some classes, are mutually exclusive, thus yield in higher accuracy when combined. We reduce KNN overfitting using Principal Component Analysis (PCA), and ensemble it with a CNN to increase its accuracy. Our approach improves our best CNN model from 93.33% to 94.03%.
Reactive Collision Avoidance using Evolutionary Neural Networks
Sep 27, 2016
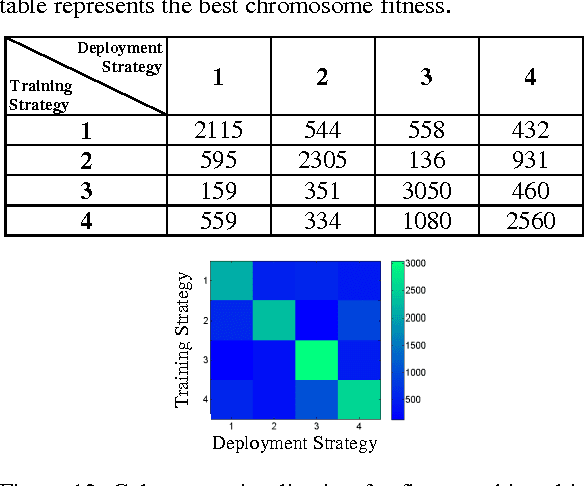
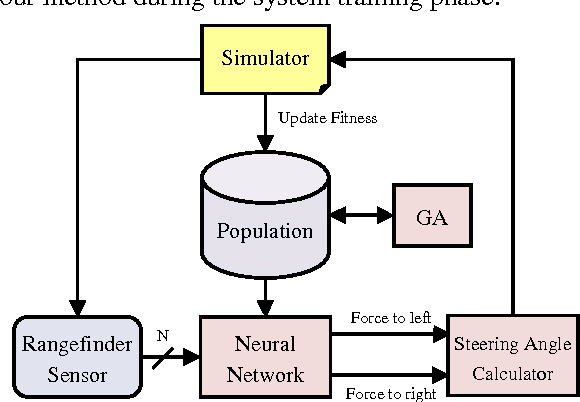
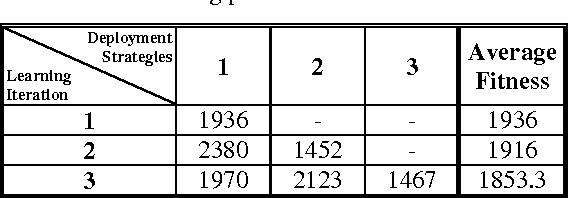
Collision avoidance systems can play a vital role in reducing the number of accidents and saving human lives. In this paper, we introduce and validate a novel method for vehicles reactive collision avoidance using evolutionary neural networks (ENN). A single front-facing rangefinder sensor is the only input required by our method. The training process and the proposed method analysis and validation are carried out using simulation. Extensive experiments are conducted to analyse the proposed method and evaluate its performance. Firstly, we experiment the ability to learn collision avoidance in a static free track. Secondly, we analyse the effect of the rangefinder sensor resolution on the learning process. Thirdly, we experiment the ability of a vehicle to individually and simultaneously learn collision avoidance. Finally, we test the generality of the proposed method. We used a more realistic and powerful simulation environment (CarMaker), a camera as an alternative input sensor, and lane keeping as an extra feature to learn. The results are encouraging; the proposed method successfully allows vehicles to learn collision avoidance in different scenarios that are unseen during training. It also generalizes well if any of the input sensor, the simulator, or the task to be learned is changed.
House price estimation from visual and textual features
Sep 27, 2016
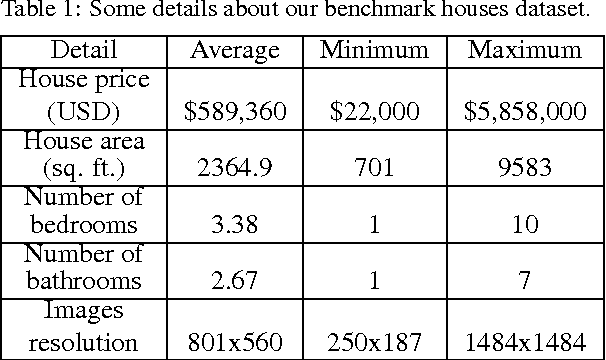
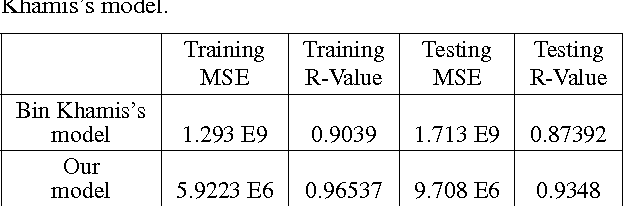

Most existing automatic house price estimation systems rely only on some textual data like its neighborhood area and the number of rooms. The final price is estimated by a human agent who visits the house and assesses it visually. In this paper, we propose extracting visual features from house photographs and combining them with the house's textual information. The combined features are fed to a fully connected multilayer Neural Network (NN) that estimates the house price as its single output. To train and evaluate our network, we have collected the first houses dataset (to our knowledge) that combines both images and textual attributes. The dataset is composed of 535 sample houses from the state of California, USA. Our experiments showed that adding the visual features increased the R-value by a factor of 3 and decreased the Mean Square Error (MSE) by one order of magnitude compared with textual-only features. Additionally, when trained on the benchmark textual-only features housing dataset, our proposed NN still outperformed the existing model published results.