 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithFill: Faithful Inpainting for Object Completion Using a Single Reference Image
Jun 12, 2024
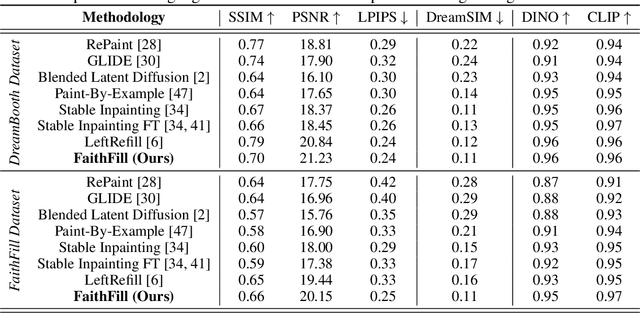
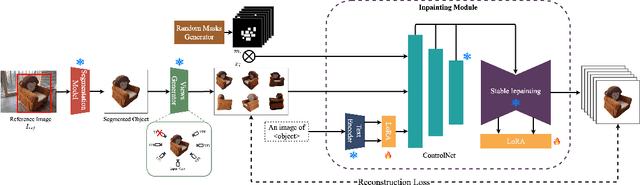

We present FaithFill, a diffusion-based inpainting object completion approach for realistic generation of missing object parts. Typically, multiple reference images are needed to achieve such realistic generation, otherwise the generation would not faithfully preserve shape, texture, color, and background. In this work, we propose a pipeline that utilizes only a single input reference image -having varying lighting, background, object pose, and/or viewpoint. The singular reference image is used to generate multiple views of the object to be inpainted. We demonstrate that FaithFill produces faithful generation of the object's missing parts, together with background/scene preservation, from a single reference image. This is demonstrated through standard similarity metrics, human judgement, and GPT evaluation. Our results are presented on the DreamBooth dataset, and a novel proposed dataset.
The Right Losses for the Right Gains: Improving the Semantic Consistency of Deep Text-to-Image Generation with Distribution-Sensitive Losses
Dec 18, 2023One of the major challenges in training deep neural networks for text-to-image generation is the significant linguistic discrepancy between ground-truth captions of each image in most popular datasets. The large difference in the choice of words in such captions results in synthesizing images that are semantically dissimilar to each other and to their ground-truth counterparts. Moreover, existing models either fail to generate the fine-grained details of the image or require a huge number of parameters that renders them inefficient for text-to-image synthesis. To fill this gap in the literature, we propose using the contrastive learning approach with a novel combination of two loss functions: fake-to-fake loss to increase the semantic consistency between generated images of the same caption, and fake-to-real loss to reduce the gap between the distributions of real images and fake ones. We test this approach on two baseline models: SSAGAN and AttnGAN (with style blocks to enhance the fine-grained details of the images.) Results show that our approach improves the qualitative results on AttnGAN with style blocks on the CUB dataset. Additionally, on the challenging COCO dataset, our approach achieves competitive results against the state-of-the-art Lafite model, outperforms the FID score of SSAGAN model by 44.