 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DCoMPaT200: Language-Grounded Compositional Understanding of Parts and Materials of 3D Shapes
Jan 12, 2025



Understanding objects in 3D at the part level is essential for humans and robots to navigate and interact with the environment. Current datasets for part-level 3D object understanding encompass a limited range of categories. For instance, the ShapeNet-Part and PartNet datasets only include 16, and 24 object categories respectively. The 3DCoMPaT dataset, specifically designed for compositional understanding of parts and materials, contains only 42 object categories. To foster richer and fine-grained part-level 3D understanding, we introduce 3DCoMPaT200, a large-scale dataset tailored for compositional understanding of object parts and materials, with 200 object categories with $\approx$5 times larger object vocabulary compared to 3DCoMPaT and $\approx$ 4 times larger part categories. Concretely, 3DCoMPaT200 significantly expands upon 3DCoMPaT, featuring 1,031 fine-grained part categories and 293 distinct material classes for compositional application to 3D object parts. Additionally, to address the complexities of compositional 3D modeling, we propose a novel task of Compositional Part Shape Retrieval using ULIP to provide a strong 3D foundational model for 3D Compositional Understanding. This method evaluates the model shape retrieval performance given one, three, or six parts described in text format. These results show that the model's performance improves with an increasing number of style compositions, highlighting the critical role of the compositional dataset. Such results underscore the dataset's effectiveness in enhancing models' capability to understand complex 3D shapes from a compositional perspective. Code and Data can be found at http://github.com/3DCoMPaT200/3DCoMPaT200
Kestrel: Point Grounding Multimodal LLM for Part-Aware 3D Vision-Language Understanding
May 29, 2024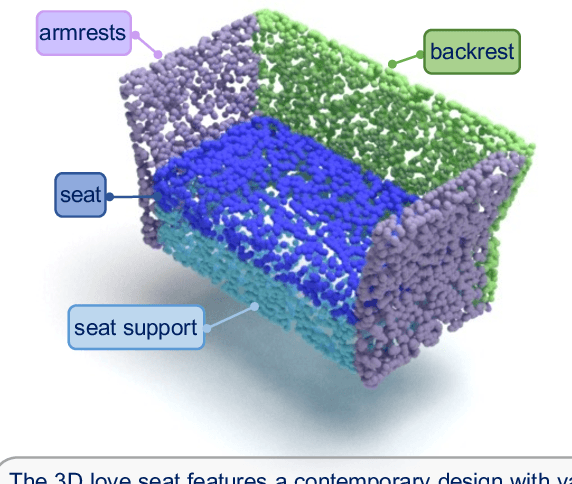
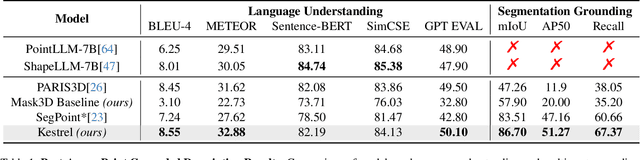
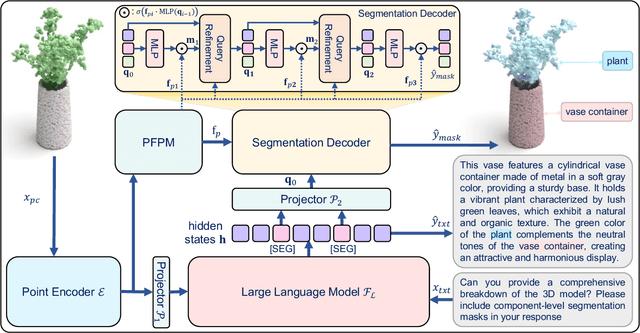
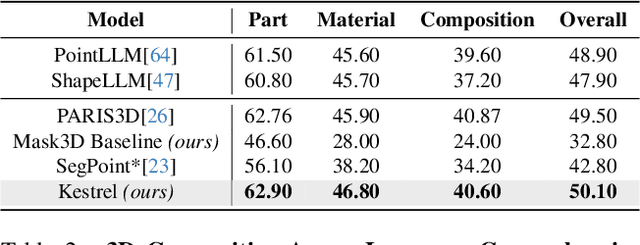
While 3D MLLMs have achieved significant progress, they are restricted to object and scene understanding and struggle to understand 3D spatial structures at the part level. In this paper, we introduce Kestrel, representing a novel approach that empowers 3D MLLMs with part-aware understanding, enabling better interpretation and segmentation grounding of 3D objects at the part level. Despite its significance, the current landscape lacks tasks and datasets that endow and assess this capability. Therefore, we propose two novel tasks: (1) Part-Aware Point Grounding, the model is tasked with directly predicting a part-level segmentation mask based on user instructions, and (2) Part-Aware Point Grounded Captioning, the model provides a detailed caption that includes part-level descriptions and their corresponding masks. To support learning and evaluating for these tasks, we introduce 3DCoMPaT Grounded Instructions Dataset (3DCoMPaT-GRIN). 3DCoMPaT-GRIN Vanilla, comprising 789k part-aware point cloud-instruction-segmentation mask triplets, is used to evaluate MLLMs' ability of part-aware segmentation grounding. 3DCoMPaT-GRIN Grounded Caption, containing 107k part-aware point cloud-instruction-grounded caption triplets, assesses both MLLMs' part-aware language comprehension and segmentation grounding capabilities. Our introduced tasks, dataset, and Kestrel represent a preliminary effort to bridge the gap between human cognition and 3D MLLMs, i.e., the ability to perceive and engage with the environment at both global and part levels. Extensive experiments on the 3DCoMPaT-GRIN show that Kestrel can generate user-specified segmentation masks, a capability not present in any existing 3D MLLM. Kestrel thus established a benchmark for evaluating the part-aware language comprehension and segmentation grounding of 3D objects. Project page at https://feielysia.github.io/Kestrel.github.io/
The Right Losses for the Right Gains: Improving the Semantic Consistency of Deep Text-to-Image Generation with Distribution-Sensitive Losses
Dec 18, 2023One of the major challenges in training deep neural networks for text-to-image generation is the significant linguistic discrepancy between ground-truth captions of each image in most popular datasets. The large difference in the choice of words in such captions results in synthesizing images that are semantically dissimilar to each other and to their ground-truth counterparts. Moreover, existing models either fail to generate the fine-grained details of the image or require a huge number of parameters that renders them inefficient for text-to-image synthesis. To fill this gap in the literature, we propose using the contrastive learning approach with a novel combination of two loss functions: fake-to-fake loss to increase the semantic consistency between generated images of the same caption, and fake-to-real loss to reduce the gap between the distributions of real images and fake ones. We test this approach on two baseline models: SSAGAN and AttnGAN (with style blocks to enhance the fine-grained details of the images.) Results show that our approach improves the qualitative results on AttnGAN with style blocks on the CUB dataset. Additionally, on the challenging COCO dataset, our approach achieves competitive results against the state-of-the-art Lafite model, outperforms the FID score of SSAGAN model by 44.
3DCoMPaT$^{++}$: An improved Large-scale 3D Vision Dataset for Compositional Recognition
Oct 27, 2023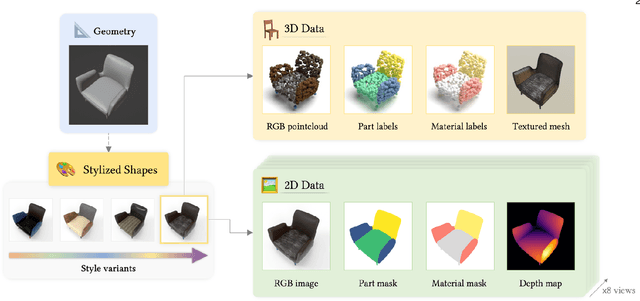
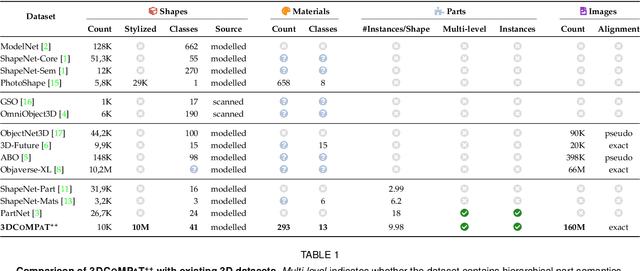

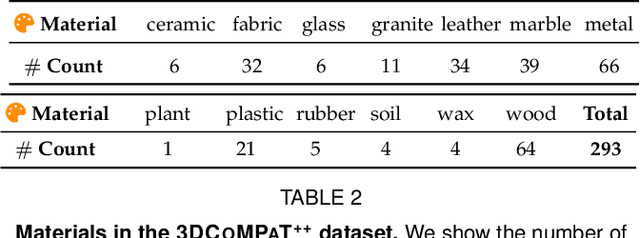
In this work, we present 3DCoMPaT$^{++}$, a multimodal 2D/3D dataset with 160 million rendered views of more than 10 million stylized 3D shapes carefully annotated at the part-instance level, alongside matching RGB point clouds, 3D textured meshes, depth maps, and segmentation masks. 3DCoMPaT$^{++}$ covers 41 shape categories, 275 fine-grained part categories, and 293 fine-grained material classes that can be compositionally applied to parts of 3D objects. We render a subset of one million stylized shapes from four equally spaced views as well as four randomized views, leading to a total of 160 million renderings. Parts are segmented at the instance level, with coarse-grained and fine-grained semantic levels. We introduce a new task, called Grounded CoMPaT Recognition (GCR), to collectively recognize and ground compositions of materials on parts of 3D objects. Additionally, we report the outcomes of a data challenge organized at CVPR2023, showcasing the winning method's utilization of a modified PointNet$^{++}$ model trained on 6D inputs, and exploring alternative techniques for GCR enhancement. We hope our work will help ease future research on compositional 3D Vision.
CoT3DRef: Chain-of-Thoughts Data-Efficient 3D Visual Grounding
Oct 10, 2023
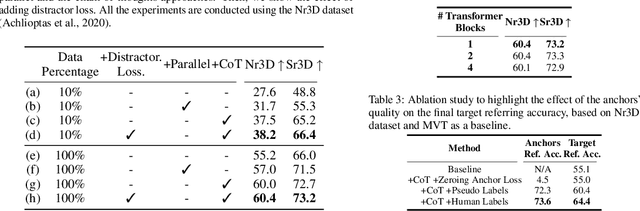
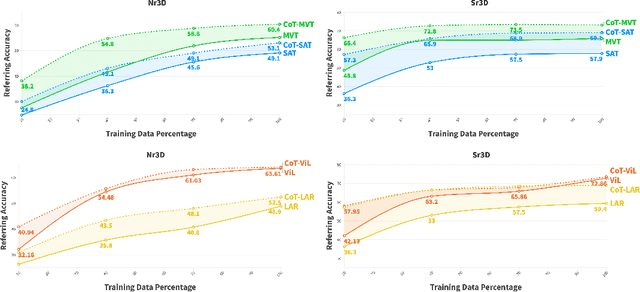
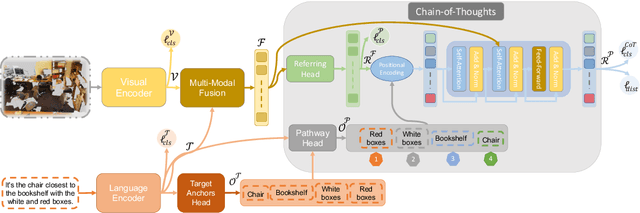
3D visual grounding is the ability to localize objects in 3D scenes conditioned by utterances. Most existing methods devote the referring head to localize the referred object directly, causing failure in complex scenarios. In addition, it does not illustrate how and why the network reaches the final decision. In this paper, we address this question Can we design an interpretable 3D visual grounding framework that has the potential to mimic the human perception system?. To this end, we formulate the 3D visual grounding problem as a sequence-to-sequence task by first predicting a chain of anchors and then the final target. Interpretability not only improves the overall performance but also helps us identify failure cases. Following the chain of thoughts approach enables us to decompose the referring task into interpretable intermediate steps, boosting the performance and making our framework extremely data-efficient. Moreover, our proposed framework can be easily integrated into any existing architecture. We validate our approach through comprehensive experiments on the Nr3D, Sr3D, and Scanrefer benchmarks and show consistent performance gains compared to existing methods without requiring manually annotated data. Furthermore, our proposed framework, dubbed CoT3DRef, is significantly data-efficient, whereas on the Sr3D dataset, when trained only on 10% of the data, we match the SOTA performance that trained on the entire data.