 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKestrel: Point Grounding Multimodal LLM for Part-Aware 3D Vision-Language Understanding
Paper and Code
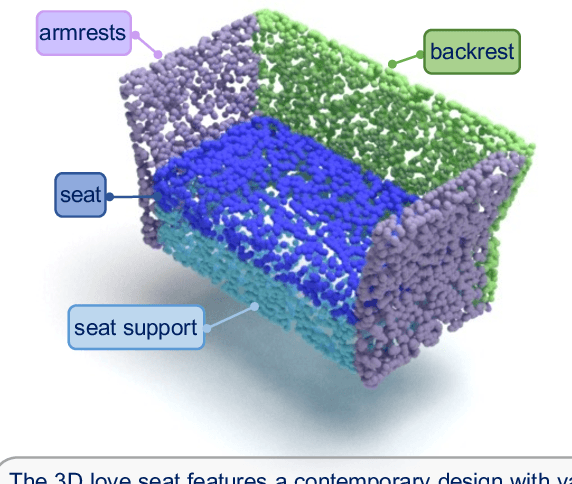
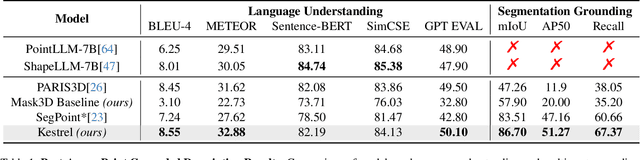
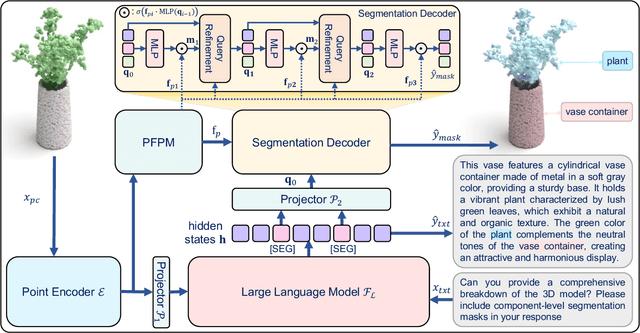
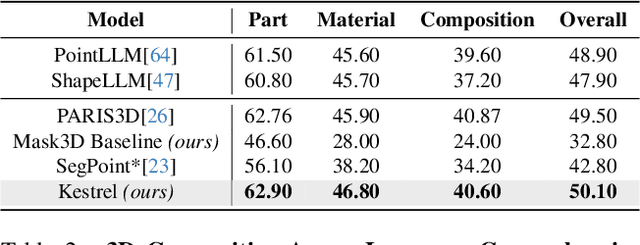
While 3D MLLMs have achieved significant progress, they are restricted to object and scene understanding and struggle to understand 3D spatial structures at the part level. In this paper, we introduce Kestrel, representing a novel approach that empowers 3D MLLMs with part-aware understanding, enabling better interpretation and segmentation grounding of 3D objects at the part level. Despite its significance, the current landscape lacks tasks and datasets that endow and assess this capability. Therefore, we propose two novel tasks: (1) Part-Aware Point Grounding, the model is tasked with directly predicting a part-level segmentation mask based on user instructions, and (2) Part-Aware Point Grounded Captioning, the model provides a detailed caption that includes part-level descriptions and their corresponding masks. To support learning and evaluating for these tasks, we introduce 3DCoMPaT Grounded Instructions Dataset (3DCoMPaT-GRIN). 3DCoMPaT-GRIN Vanilla, comprising 789k part-aware point cloud-instruction-segmentation mask triplets, is used to evaluate MLLMs' ability of part-aware segmentation grounding. 3DCoMPaT-GRIN Grounded Caption, containing 107k part-aware point cloud-instruction-grounded caption triplets, assesses both MLLMs' part-aware language comprehension and segmentation grounding capabilities. Our introduced tasks, dataset, and Kestrel represent a preliminary effort to bridge the gap between human cognition and 3D MLLMs, i.e., the ability to perceive and engage with the environment at both global and part levels. Extensive experiments on the 3DCoMPaT-GRIN show that Kestrel can generate user-specified segmentation masks, a capability not present in any existing 3D MLLM. Kestrel thus established a benchmark for evaluating the part-aware language comprehension and segmentation grounding of 3D objects. Project page at https://feielysia.github.io/Kestrel.github.io/