 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverFill: Two-Stage Models for Efficient Language Model Decoding
Aug 11, 2025Large language models (LLMs) excel across diverse tasks but face significant deployment challenges due to high inference costs. LLM inference comprises prefill (compute-bound) and decode (memory-bound) stages, with decode dominating latency particularly for long sequences. Current decoder-only models handle both stages uniformly, despite their distinct computational profiles. We propose OverFill, which decouples these stages to optimize accuracy-efficiency tradeoffs. OverFill begins with a full model for prefill, processing system and user inputs in parallel. It then switches to a dense pruned model, while generating tokens sequentially. Leveraging more compute during prefill, OverFill improves generation quality with minimal latency overhead. Our 3B-to-1B OverFill configuration outperforms 1B pruned models by 83.2%, while the 8B-to-3B configuration improves over 3B pruned models by 79.2% on average across standard benchmarks. OverFill matches the performance of same-sized models trained from scratch, while using significantly less training data. Our code is available at https://github.com/friendshipkim/overfill.
FlashDepth: Real-time Streaming Video Depth Estimation at 2K Resolution
Apr 09, 2025A versatile video depth estimation model should (1) be accurate and consistent across frames, (2) produce high-resolution depth maps, and (3) support real-time streaming. We propose FlashDepth, a method that satisfies all three requirements, performing depth estimation on a 2044x1148 streaming video at 24 FPS. We show that, with careful modifications to pretrained single-image depth models, these capabilities are enabled with relatively little data and training. We evaluate our approach across multiple unseen datasets against state-of-the-art depth models, and find that ours outperforms them in terms of boundary sharpness and speed by a significant margin, while maintaining competitive accuracy. We hope our model will enable various applications that require high-resolution depth, such as video editing, and online decision-making, such as robotics.
Radial Networks: Dynamic Layer Routing for High-Performance Large Language Models
Apr 07, 2024Large language models (LLMs) often struggle with strict memory, latency, and power demands. To meet these demands, various forms of dynamic sparsity have been proposed that reduce compute on an input-by-input basis. These methods improve over static methods by exploiting the variance across individual inputs, which has steadily grown with the exponential increase in training data. Yet, the increasing depth within modern models, currently with hundreds of layers, has opened opportunities for dynamic layer sparsity, which skips the computation for entire layers. In this work, we explore the practicality of layer sparsity by profiling residual connections and establish the relationship between model depth and layer sparsity. For example, the residual blocks in the OPT-66B model have a median contribution of 5% to its output. We then take advantage of this dynamic sparsity and propose Radial Networks, which perform token-level routing between layers guided by a trained router module. These networks can be used in a post-training distillation from sequential networks or trained from scratch to co-learn the router and layer weights. They enable scaling to larger model sizes by decoupling the number of layers from the dynamic depth of the network, and their design allows for layer reuse. By varying the compute token by token, they reduce the overall resources needed for generating entire sequences. Overall, this leads to larger capacity networks with significantly lower compute and serving costs for large language models.
Exploring the Limits of Semantic Image Compression at Micro-bits per Pixel
Feb 21, 2024



Traditional methods, such as JPEG, perform image compression by operating on structural information, such as pixel values or frequency content. These methods are effective to bitrates around one bit per pixel (bpp) and higher at standard image sizes. In contrast, text-based semantic compression directly stores concepts and their relationships using natural language, which has evolved with humans to efficiently represent these salient concepts. These methods can operate at extremely low bitrates by disregarding structural information like location, size, and orientation. In this work, we use GPT-4V and DALL-E3 from OpenAI to explore the quality-compression frontier for image compression and identify the limitations of current technology. We push semantic compression as low as 100 $\mu$bpp (up to $10,000\times$ smaller than JPEG) by introducing an iterative reflection process to improve the decoded image. We further hypothesize this 100 $\mu$bpp level represents a soft limit on semantic compression at standard image resolutions.
The Right Losses for the Right Gains: Improving the Semantic Consistency of Deep Text-to-Image Generation with Distribution-Sensitive Losses
Dec 18, 2023One of the major challenges in training deep neural networks for text-to-image generation is the significant linguistic discrepancy between ground-truth captions of each image in most popular datasets. The large difference in the choice of words in such captions results in synthesizing images that are semantically dissimilar to each other and to their ground-truth counterparts. Moreover, existing models either fail to generate the fine-grained details of the image or require a huge number of parameters that renders them inefficient for text-to-image synthesis. To fill this gap in the literature, we propose using the contrastive learning approach with a novel combination of two loss functions: fake-to-fake loss to increase the semantic consistency between generated images of the same caption, and fake-to-real loss to reduce the gap between the distributions of real images and fake ones. We test this approach on two baseline models: SSAGAN and AttnGAN (with style blocks to enhance the fine-grained details of the images.) Results show that our approach improves the qualitative results on AttnGAN with style blocks on the CUB dataset. Additionally, on the challenging COCO dataset, our approach achieves competitive results against the state-of-the-art Lafite model, outperforms the FID score of SSAGAN model by 44.
ArtELingo: A Million Emotion Annotations of WikiArt with Emphasis on Diversity over Language and Culture
Nov 19, 2022



This paper introduces ArtELingo, a new benchmark and dataset, designed to encourage work on diversity across languages and cultures. Following ArtEmis, a collection of 80k artworks from WikiArt with 0.45M emotion labels and English-only captions, ArtELingo adds another 0.79M annotations in Arabic and Chinese, plus 4.8K in Spanish to evaluate "cultural-transfer" performance. More than 51K artworks have 5 annotations or more in 3 languages. This diversity makes it possible to study similarities and differences across languages and cultures. Further, we investigate captioning tasks, and find diversity improves the performance of baseline models. ArtELingo is publicly available at https://www.artelingo.org/ with standard splits and baseline models. We hope our work will help ease future research on multilinguality and culturally-aware AI.
Journey Towards Tiny Perceptual Super-Resolution
Jul 08, 2020

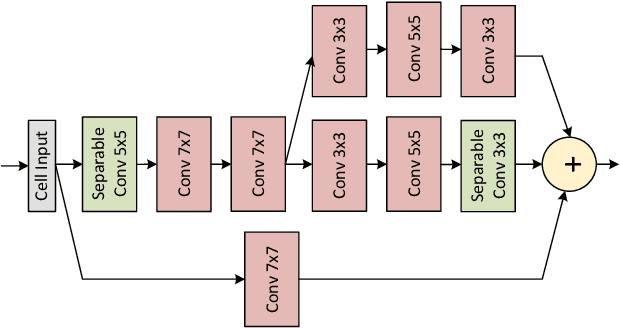
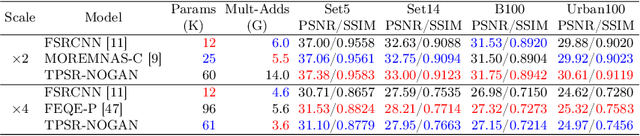
Recent works in single-image perceptual super-resolution (SR) have demonstrated unprecedented performance in generating realistic textures by means of deep convolutional networks. However, these convolutional models are excessively large and expensive, hindering their effective deployment to end devices. In this work, we propose a neural architecture search (NAS) approach that integrates NAS and generative adversarial networks (GANs) with recent advances in perceptual SR and pushes the efficiency of small perceptual SR models to facilitate on-device execution. Specifically, we search over the architectures of both the generator and the discriminator sequentially, highlighting the unique challenges and key observations of searching for an SR-optimized discriminator and comparing them with existing discriminator architectures in the literature. Our tiny perceptual SR (TPSR) models outperform SRGAN and EnhanceNet on both full-reference perceptual metric (LPIPS) and distortion metric (PSNR) while being up to 26.4$\times$ more memory efficient and 33.6$\times$ more compute efficient respectively.