 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DCoMPaT$^{++}$: An improved Large-scale 3D Vision Dataset for Compositional Recognition
Oct 27, 2023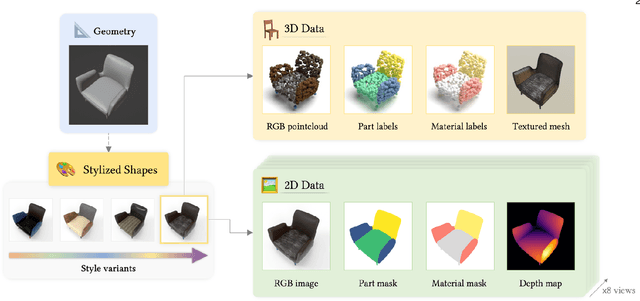
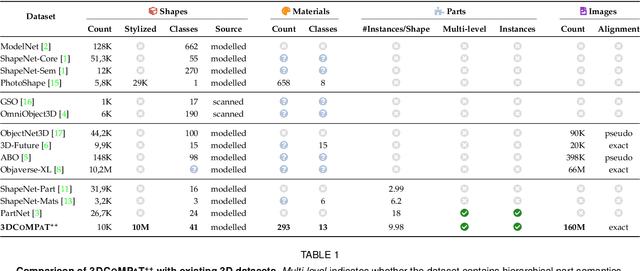

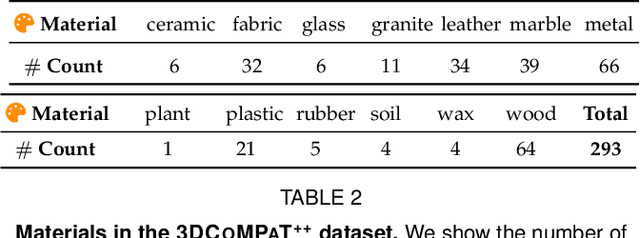
In this work, we present 3DCoMPaT$^{++}$, a multimodal 2D/3D dataset with 160 million rendered views of more than 10 million stylized 3D shapes carefully annotated at the part-instance level, alongside matching RGB point clouds, 3D textured meshes, depth maps, and segmentation masks. 3DCoMPaT$^{++}$ covers 41 shape categories, 275 fine-grained part categories, and 293 fine-grained material classes that can be compositionally applied to parts of 3D objects. We render a subset of one million stylized shapes from four equally spaced views as well as four randomized views, leading to a total of 160 million renderings. Parts are segmented at the instance level, with coarse-grained and fine-grained semantic levels. We introduce a new task, called Grounded CoMPaT Recognition (GCR), to collectively recognize and ground compositions of materials on parts of 3D objects. Additionally, we report the outcomes of a data challenge organized at CVPR2023, showcasing the winning method's utilization of a modified PointNet$^{++}$ model trained on 6D inputs, and exploring alternative techniques for GCR enhancement. We hope our work will help ease future research on compositional 3D Vision.
CoT3DRef: Chain-of-Thoughts Data-Efficient 3D Visual Grounding
Oct 10, 2023
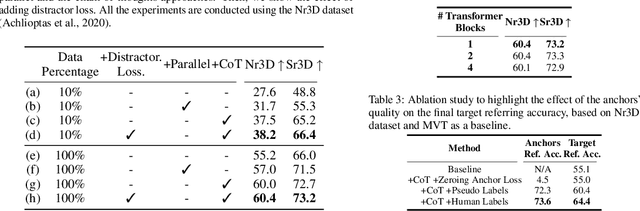
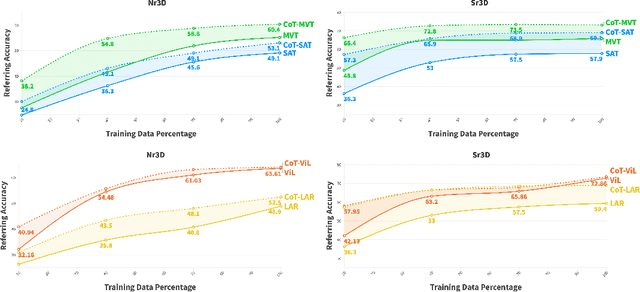
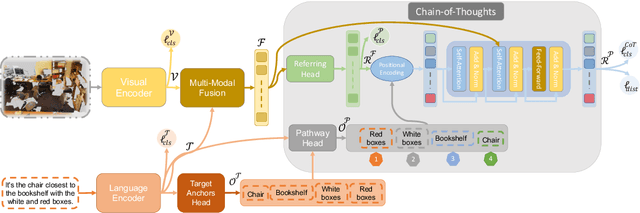
3D visual grounding is the ability to localize objects in 3D scenes conditioned by utterances. Most existing methods devote the referring head to localize the referred object directly, causing failure in complex scenarios. In addition, it does not illustrate how and why the network reaches the final decision. In this paper, we address this question Can we design an interpretable 3D visual grounding framework that has the potential to mimic the human perception system?. To this end, we formulate the 3D visual grounding problem as a sequence-to-sequence task by first predicting a chain of anchors and then the final target. Interpretability not only improves the overall performance but also helps us identify failure cases. Following the chain of thoughts approach enables us to decompose the referring task into interpretable intermediate steps, boosting the performance and making our framework extremely data-efficient. Moreover, our proposed framework can be easily integrated into any existing architecture. We validate our approach through comprehensive experiments on the Nr3D, Sr3D, and Scanrefer benchmarks and show consistent performance gains compared to existing methods without requiring manually annotated data. Furthermore, our proposed framework, dubbed CoT3DRef, is significantly data-efficient, whereas on the Sr3D dataset, when trained only on 10% of the data, we match the SOTA performance that trained on the entire data.
Dataset Knowledge Transfer for Class-Incremental Learning without Memory
Oct 16, 2021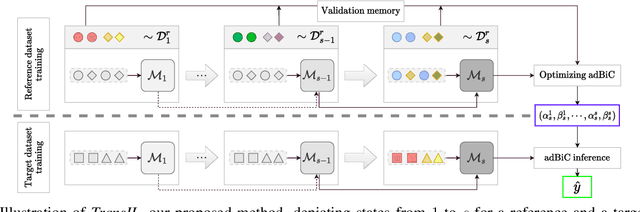
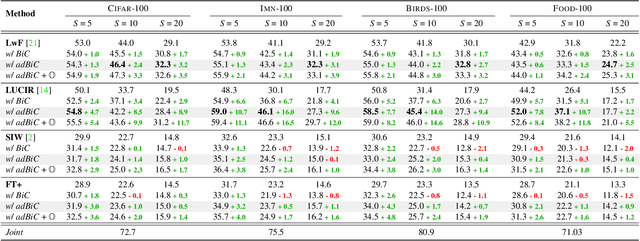
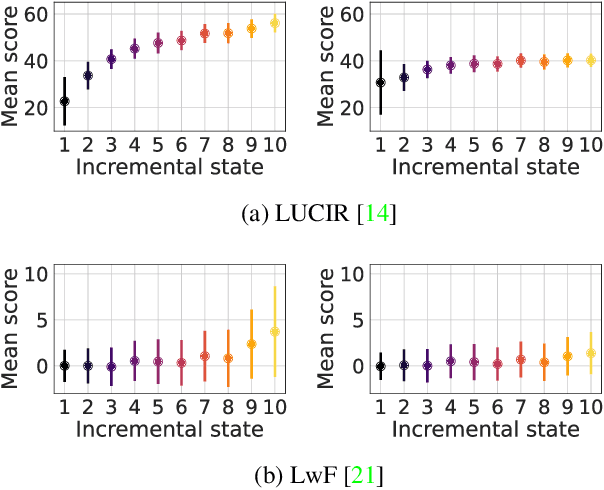
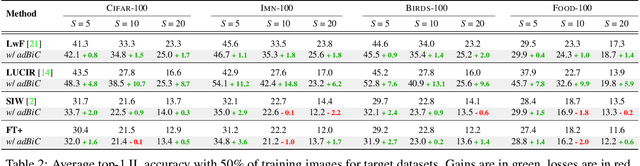
Incremental learning enables artificial agents to learn from sequential data. While important progress was made by exploiting deep neural networks, incremental learning remains very challenging. This is particularly the case when no memory of past data is allowed and catastrophic forgetting has a strong negative effect. We tackle class-incremental learning without memory by adapting prediction bias correction, a method which makes predictions of past and new classes more comparable. It was proposed when a memory is allowed and cannot be directly used without memory, since samples of past classes are required. We introduce a two-step learning process which allows the transfer of bias correction parameters between reference and target datasets. Bias correction is first optimized offline on reference datasets which have an associated validation memory. The obtained correction parameters are then transferred to target datasets, for which no memory is available. The second contribution is to introduce a finer modeling of bias correction by learning its parameters per incremental state instead of the usual past vs. new class modeling. The proposed dataset knowledge transfer is applicable to any incremental method which works without memory. We test its effectiveness by applying it to four existing methods. Evaluation with four target datasets and different configurations shows consistent improvement, with practically no computational and memory overhead.