 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScoresActivation: A New Activation Function for Model Agnostic Global Explainability by Design
Nov 17, 2025Understanding the decision of large deep learning models is a critical challenge for building transparent and trustworthy systems. Although the current post hoc explanation methods offer valuable insights into feature importance, they are inherently disconnected from the model training process, limiting their faithfulness and utility. In this work, we introduce a novel differentiable approach to global explainability by design, integrating feature importance estimation directly into model training. Central to our method is the ScoresActivation function, a feature-ranking mechanism embedded within the learning pipeline. This integration enables models to prioritize features according to their contribution to predictive performance in a differentiable and end-to-end trainable manner. Evaluations across benchmark datasets show that our approach yields globally faithful, stable feature rankings aligned with SHAP values and ground-truth feature importance, while maintaining high predictive performance. Moreover, feature scoring is 150 times faster than the classical SHAP method, requiring only 2 seconds during training compared to SHAP's 300 seconds for feature ranking in the same configuration. Our method also improves classification accuracy by 11.24% with 10 features (5 relevant) and 29.33% with 16 features (5 relevant, 11 irrelevant), demonstrating robustness to irrelevant inputs. This work bridges the gap between model accuracy and interpretability, offering a scalable framework for inherently explainable machine learning.
ExDDV: A New Dataset for Explainable Deepfake Detection in Video
Mar 18, 2025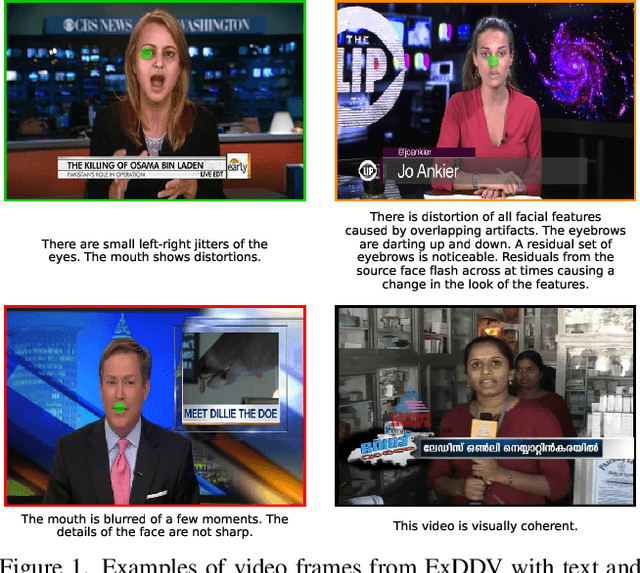
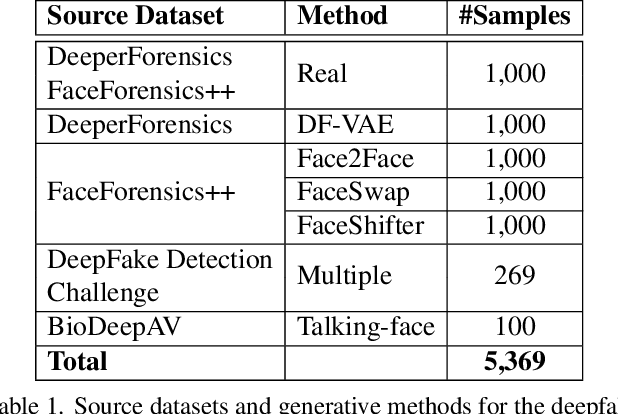
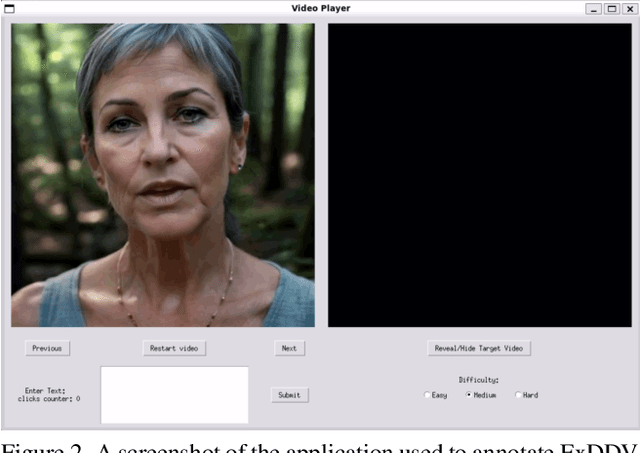
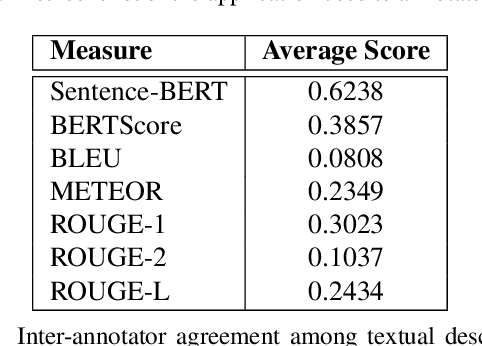
The ever growing realism and quality of generated videos makes it increasingly harder for humans to spot deepfake content, who need to rely more and more on automatic deepfake detectors. However, deepfake detectors are also prone to errors, and their decisions are not explainable, leaving humans vulnerable to deepfake-based fraud and misinformation. To this end, we introduce ExDDV, the first dataset and benchmark for Explainable Deepfake Detection in Video. ExDDV comprises around 5.4K real and deepfake videos that are manually annotated with text descriptions (to explain the artifacts) and clicks (to point out the artifacts). We evaluate a number of vision-language models on ExDDV, performing experiments with various fine-tuning and in-context learning strategies. Our results show that text and click supervision are both required to develop robust explainable models for deepfake videos, which are able to localize and describe the observed artifacts. Our novel dataset and code to reproduce the results are available at https://github.com/vladhondru25/ExDDV.
FeTrIL++: Feature Translation for Exemplar-Free Class-Incremental Learning with Hill-Climbing
Mar 12, 2024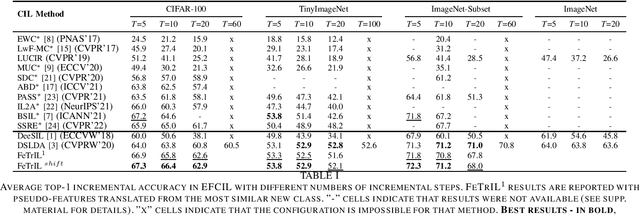
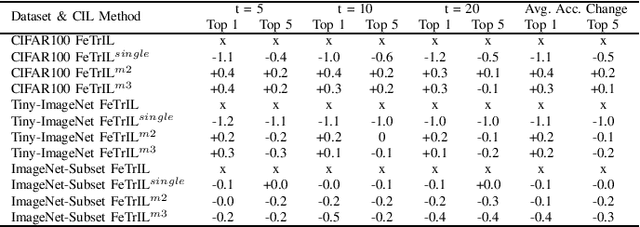
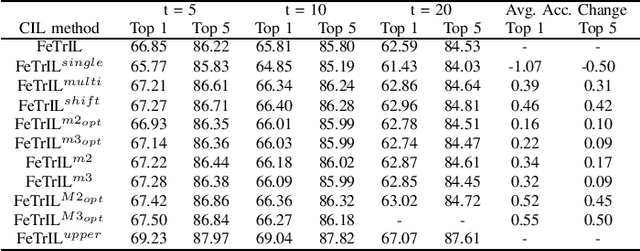
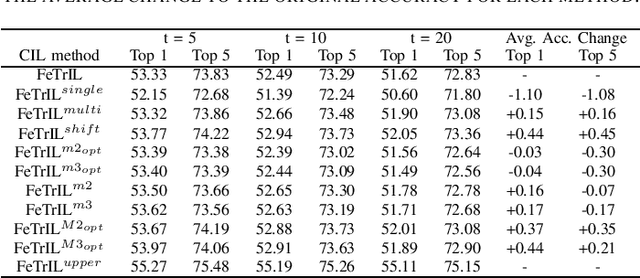
Exemplar-free class-incremental learning (EFCIL) poses significant challenges, primarily due to catastrophic forgetting, necessitating a delicate balance between stability and plasticity to accurately recognize both new and previous classes. Traditional EFCIL approaches typically skew towards either model plasticity through successive fine-tuning or stability by employing a fixed feature extractor beyond the initial incremental state. Building upon the foundational FeTrIL framework, our research extends into novel experimental domains to examine the efficacy of various oversampling techniques and dynamic optimization strategies across multiple challenging datasets and incremental settings. We specifically explore how oversampling impacts accuracy relative to feature availability and how different optimization methodologies, including dynamic recalibration and feature pool diversification, influence incremental learning outcomes. The results from these comprehensive experiments, conducted on CIFAR100, Tiny-ImageNet, and an ImageNet-Subset, under-score the superior performance of FeTrIL in balancing accuracy for both new and past classes against ten contemporary methods. Notably, our extensions reveal the nuanced impacts of oversampling and optimization on EFCIL, contributing to a more refined understanding of feature-space manipulation for class incremental learning. FeTrIL and its extended analysis in this paper FeTrIL++ pave the way for more adaptable and efficient EFCIL methodologies, promising significant improvements in handling catastrophic forgetting without the need for exemplars.
Neuro-symbolic model for cantilever beams damage detection
May 04, 2023In the last decade, damage detection approaches swiftly changed from advanced signal processing methods to machine learning and especially deep learning models, to accurately and non-intrusively estimate the state of the beam structures. But as the deep learning models reached their peak performances, also their limitations in applicability and vulnerabilities were observed. One of the most important reason for the lack of trustworthiness in operational conditions is the absence of intrinsic explainability of the deep learning system, due to the encoding of the knowledge in tensor values and without the inclusion of logical constraints. In this paper, we propose a neuro-symbolic model for the detection of damages in cantilever beams based on a novel cognitive architecture in which we join the processing power of convolutional networks with the interactive control offered by queries realized through the inclusion of real logic directly into the model. The hybrid discriminative model is introduced under the name Logic Convolutional Neural Regressor and it is tested on a dataset of values of the relative natural frequency shifts of cantilever beams derived from an original mathematical relation. While the obtained results preserve all the predictive capabilities of deep learning models, the usage of three distances as predicates for satisfiability, makes the system more trustworthy and scalable for practical applications. Extensive numerical and laboratory experiments were performed, and they all demonstrated the superiority of the hybrid approach, which can open a new path for solving the damage detection problem.
Dataset Knowledge Transfer for Class-Incremental Learning without Memory
Oct 16, 2021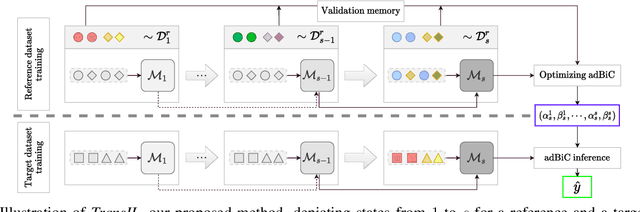
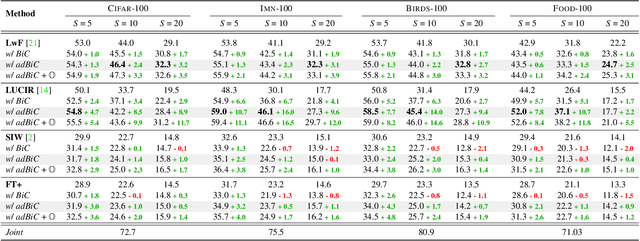
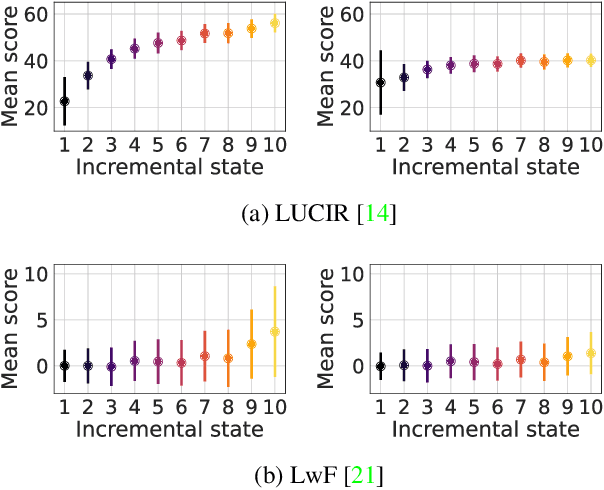
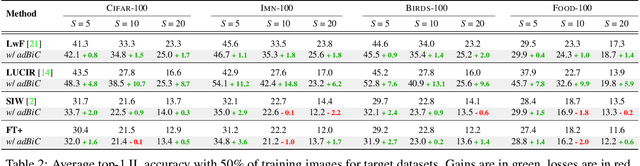
Incremental learning enables artificial agents to learn from sequential data. While important progress was made by exploiting deep neural networks, incremental learning remains very challenging. This is particularly the case when no memory of past data is allowed and catastrophic forgetting has a strong negative effect. We tackle class-incremental learning without memory by adapting prediction bias correction, a method which makes predictions of past and new classes more comparable. It was proposed when a memory is allowed and cannot be directly used without memory, since samples of past classes are required. We introduce a two-step learning process which allows the transfer of bias correction parameters between reference and target datasets. Bias correction is first optimized offline on reference datasets which have an associated validation memory. The obtained correction parameters are then transferred to target datasets, for which no memory is available. The second contribution is to introduce a finer modeling of bias correction by learning its parameters per incremental state instead of the usual past vs. new class modeling. The proposed dataset knowledge transfer is applicable to any incremental method which works without memory. We test its effectiveness by applying it to four existing methods. Evaluation with four target datasets and different configurations shows consistent improvement, with practically no computational and memory overhead.