 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExDDV: A New Dataset for Explainable Deepfake Detection in Video
Paper and Code
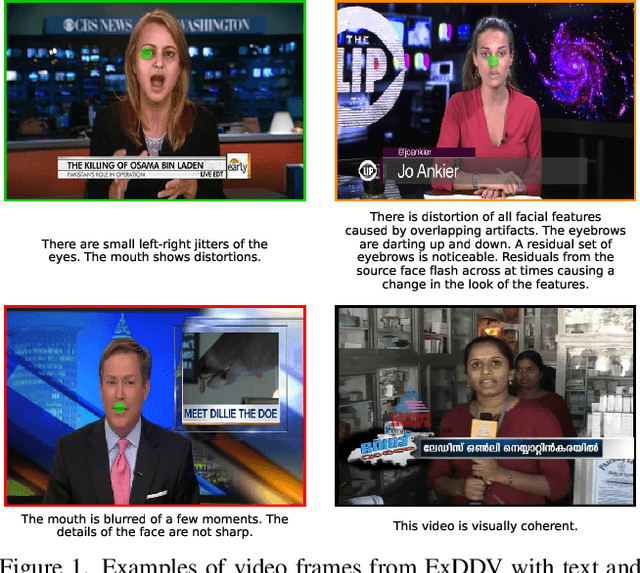
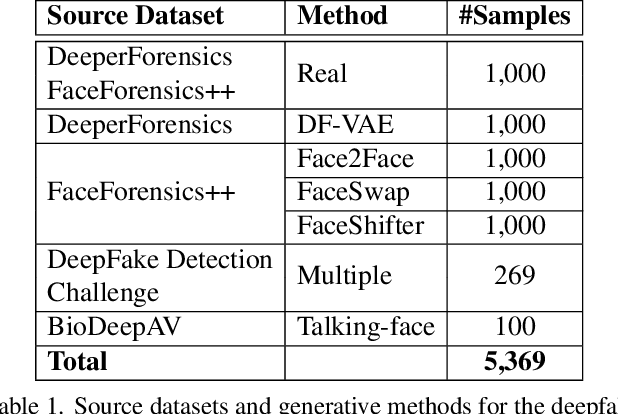
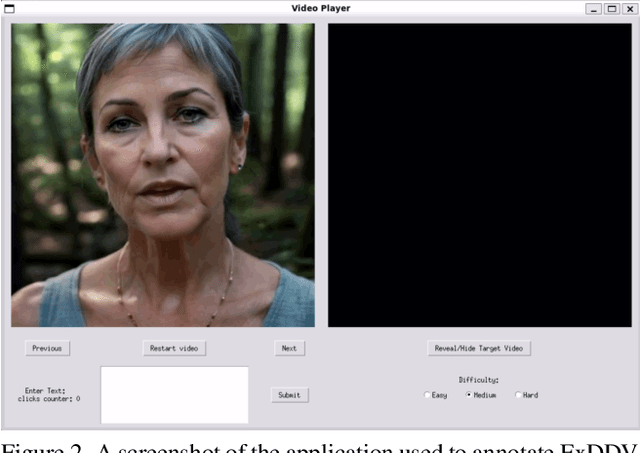
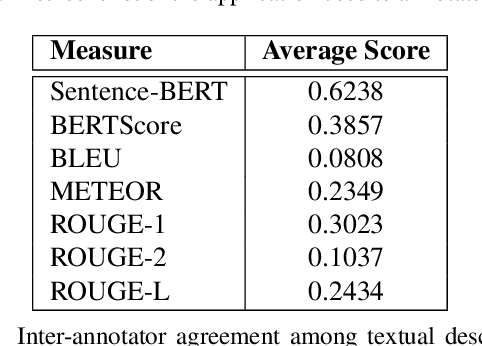
The ever growing realism and quality of generated videos makes it increasingly harder for humans to spot deepfake content, who need to rely more and more on automatic deepfake detectors. However, deepfake detectors are also prone to errors, and their decisions are not explainable, leaving humans vulnerable to deepfake-based fraud and misinformation. To this end, we introduce ExDDV, the first dataset and benchmark for Explainable Deepfake Detection in Video. ExDDV comprises around 5.4K real and deepfake videos that are manually annotated with text descriptions (to explain the artifacts) and clicks (to point out the artifacts). We evaluate a number of vision-language models on ExDDV, performing experiments with various fine-tuning and in-context learning strategies. Our results show that text and click supervision are both required to develop robust explainable models for deepfake videos, which are able to localize and describe the observed artifacts. Our novel dataset and code to reproduce the results are available at https://github.com/vladhondru25/ExDDV.