 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithFill: Faithful Inpainting for Object Completion Using a Single Reference Image
Paper and Code
Jun 12, 2024
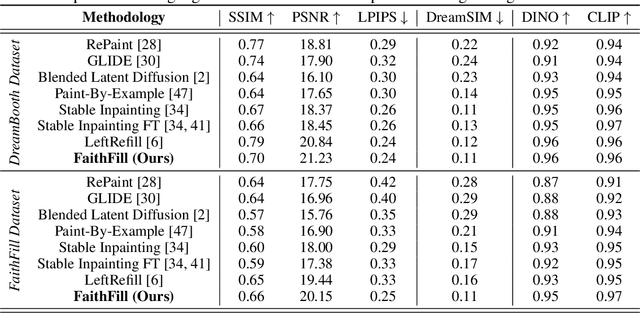
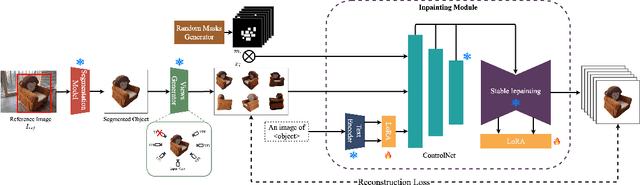

We present FaithFill, a diffusion-based inpainting object completion approach for realistic generation of missing object parts. Typically, multiple reference images are needed to achieve such realistic generation, otherwise the generation would not faithfully preserve shape, texture, color, and background. In this work, we propose a pipeline that utilizes only a single input reference image -having varying lighting, background, object pose, and/or viewpoint. The singular reference image is used to generate multiple views of the object to be inpainted. We demonstrate that FaithFill produces faithful generation of the object's missing parts, together with background/scene preservation, from a single reference image. This is demonstrated through standard similarity metrics, human judgement, and GPT evaluation. Our results are presented on the DreamBooth dataset, and a novel proposed dataset.