 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZodiAq: An Isotropic Flagella-Inspired Soft Underwater Drone for Safe Marine Exploration
Mar 25, 2025

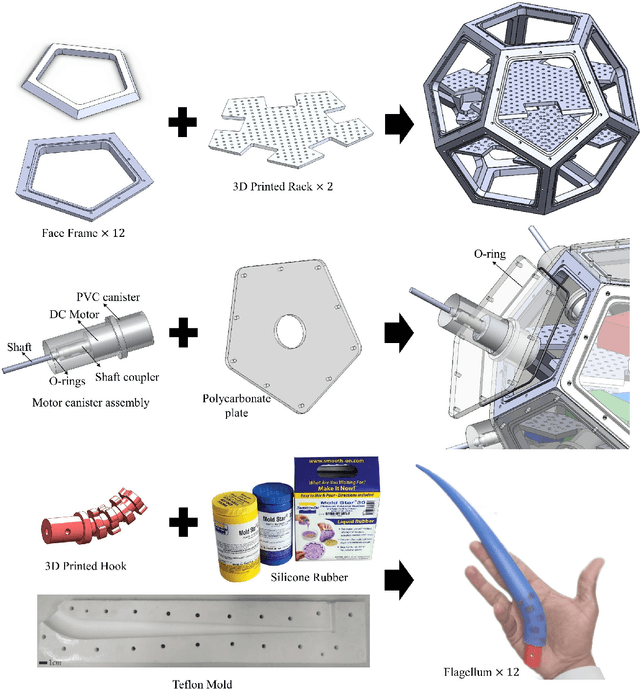

The inherent challenges of robotic underwater exploration, such as hydrodynamic effects, the complexity of dynamic coupling, and the necessity for sensitive interaction with marine life, call for the adoption of soft robotic approaches in marine exploration. To address this, we present a novel prototype, ZodiAq, a soft underwater drone inspired by prokaryotic bacterial flagella. ZodiAq's unique dodecahedral structure, equipped with 12 flagella-like arms, ensures design redundancy and compliance, ideal for navigating complex underwater terrains. The prototype features a central unit based on a Raspberry Pi, connected to a sensory system for inertial, depth, and vision detection, and an acoustic modem for communication. Combined with the implemented control law, it renders ZodiAq an intelligent system. This paper details the design and fabrication process of ZodiAq, highlighting design choices and prototype capabilities. Based on the strain-based modeling of Cosserat rods, we have developed a digital twin of the prototype within a simulation toolbox to ease analysis and control. To optimize its operation in dynamic aquatic conditions, a simplified model-based controller has been developed and implemented, facilitating intelligent and adaptive movement in the hydrodynamic environment. Extensive experimental demonstrations highlight the drone's potential, showcasing its design redundancy, embodied intelligence, crawling gait, and practical applications in diverse underwater settings. This research contributes significantly to the field of underwater soft robotics, offering a promising new avenue for safe, efficient, and environmentally conscious underwater exploration.
Friction-Scaled Vibrotactile Feedback for Real-Time Slip Detection in Manipulation using Robotic Sixth Finger
Mar 19, 2025


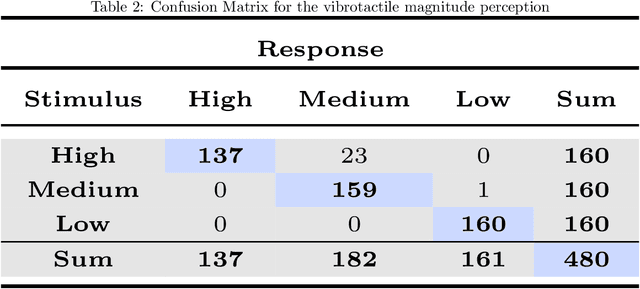
The integration of extra-robotic limbs/fingers to enhance and expand motor skills, particularly for grasping and manipulation, possesses significant challenges. The grasping performance of existing limbs/fingers is far inferior to that of human hands. Human hands can detect onset of slip through tactile feedback originating from tactile receptors during the grasping process, enabling precise and automatic regulation of grip force. The frictional information is perceived by humans depending upon slip happening between finger and object. Enhancing this capability in extra-robotic limbs or fingers used by humans is challenging. To address this challenge, this paper introduces novel approach to communicate frictional information to users through encoded vibrotactile cues. These cues are conveyed on onset of incipient slip thus allowing users to perceive friction and ultimately use this information to increase force to avoid dropping of object. In a 2-alternative forced-choice protocol, participants gripped and lifted a glass under three different frictional conditions, applying a normal force of 3.5 N. After reaching this force, glass was gradually released to induce slip. During this slipping phase, vibrations scaled according to static coefficient of friction were presented to users, reflecting frictional conditions. The results suggested an accuracy of 94.53 p/m 3.05 (mean p/mSD) in perceiving frictional information upon lifting objects with varying friction. The results indicate effectiveness of using vibrotactile feedback for sensory feedback, allowing users of extra-robotic limbs or fingers to perceive frictional information. This enables them to assess surface properties and adjust grip force according to frictional conditions, enhancing their ability to grasp, manipulate objects more effectively.
Benchmarking Vision-Based Object Tracking for USVs in Complex Maritime Environments
Dec 10, 2024Vision-based target tracking is crucial for unmanned surface vehicles (USVs) to perform tasks such as inspection, monitoring, and surveillance. However, real-time tracking in complex maritime environments is challenging due to dynamic camera movement, low visibility, and scale variation. Typically, object detection methods combined with filtering techniques are commonly used for tracking, but they often lack robustness, particularly in the presence of camera motion and missed detections. Although advanced tracking methods have been proposed recently, their application in maritime scenarios is limited. To address this gap, this study proposes a vision-guided object-tracking framework for USVs, integrating state-of-the-art tracking algorithms with low-level control systems to enable precise tracking in dynamic maritime environments. We benchmarked the performance of seven distinct trackers, developed using advanced deep learning techniques such as Siamese Networks and Transformers, by evaluating them on both simulated and real-world maritime datasets. In addition, we evaluated the robustness of various control algorithms in conjunction with these tracking systems. The proposed framework was validated through simulations and real-world sea experiments, demonstrating its effectiveness in handling dynamic maritime conditions. The results show that SeqTrack, a Transformer-based tracker, performed best in adverse conditions, such as dust storms. Among the control algorithms evaluated, the linear quadratic regulator controller (LQR) demonstrated the most robust and smooth control, allowing for stable tracking of the USV.
Ontology-driven Prompt Tuning for LLM-based Task and Motion Planning
Dec 10, 2024Performing complex manipulation tasks in dynamic environments requires efficient Task and Motion Planning (TAMP) approaches, which combine high-level symbolic plan with low-level motion planning. Advances in Large Language Models (LLMs), such as GPT-4, are transforming task planning by offering natural language as an intuitive and flexible way to describe tasks, generate symbolic plans, and reason. However, the effectiveness of LLM-based TAMP approaches is limited due to static and template-based prompting, which struggles in adapting to dynamic environments and complex task contexts. To address these limitations, this work proposes a novel ontology-driven prompt-tuning framework that employs knowledge-based reasoning to refine and expand user prompts with task contextual reasoning and knowledge-based environment state descriptions. Integrating domain-specific knowledge into the prompt ensures semantically accurate and context-aware task plans. The proposed framework demonstrates its effectiveness by resolving semantic errors in symbolic plan generation, such as maintaining logical temporal goal ordering in scenarios involving hierarchical object placement. The proposed framework is validated through both simulation and real-world scenarios, demonstrating significant improvements over the baseline approach in terms of adaptability to dynamic environments, and the generation of semantically correct task plans.
An Aerial Transport System in Marine GNSS-Denied Environment
Nov 03, 2024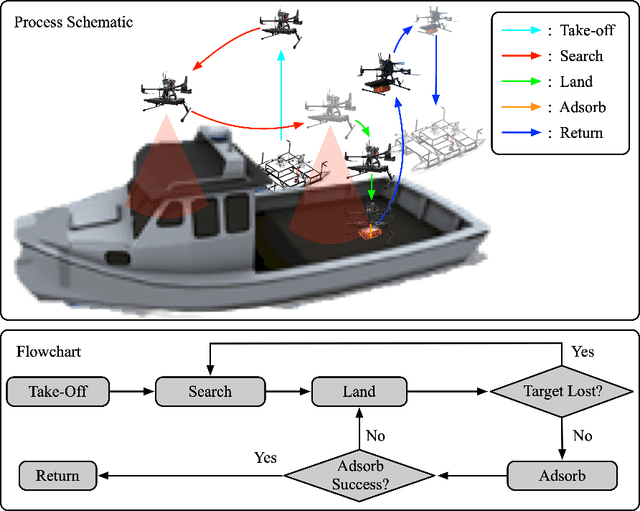
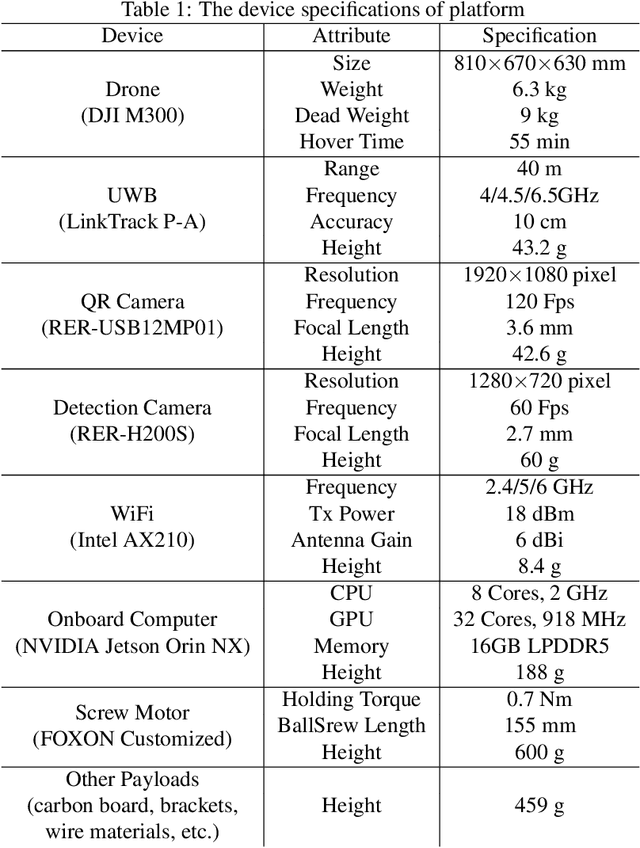
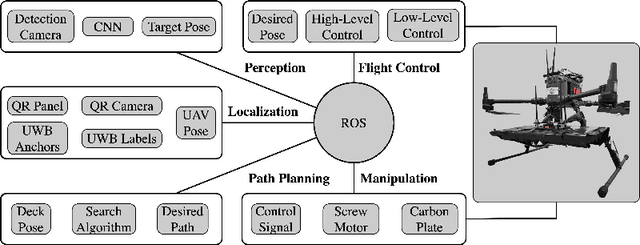

This paper presents an autonomous aerial system specifically engineered for operation in challenging marine GNSS-denied environments, aimed at transporting small cargo from a target vessel. In these environments, characterized by weakly textured sea surfaces with few feature points, chaotic deck oscillations due to waves, and significant wind gusts, conventional navigation methods often prove inadequate. Leveraging the DJI M300 platform, our system is designed to autonomously navigate and transport cargo while overcoming these environmental challenges. In particular, this paper proposes an anchor-based localization method using ultrawideband (UWB) and QR codes facilities, which decouples the UAV's attitude from that of the moving landing platform, thus reducing control oscillations caused by platform movement. Additionally, a motor-driven attachment mechanism for cargo is designed, which enhances the UAV's field of view during descent and ensures a reliable attachment to the cargo upon landing. The system's reliability and effectiveness were progressively enhanced through multiple outdoor experimental iterations and were validated by the successful cargo transport during the 2024 Mohamed BinZayed International Robotics Challenge (MBZIRC2024) competition. Crucially, the system addresses uncertainties and interferences inherent in maritime transportation missions without prior knowledge of cargo locations on the deck and with strict limitations on intervention throughout the transportation.
SlipNet: Slip Cost Map for Autonomous Navigation on Heterogeneous Deformable Terrains
Sep 03, 2024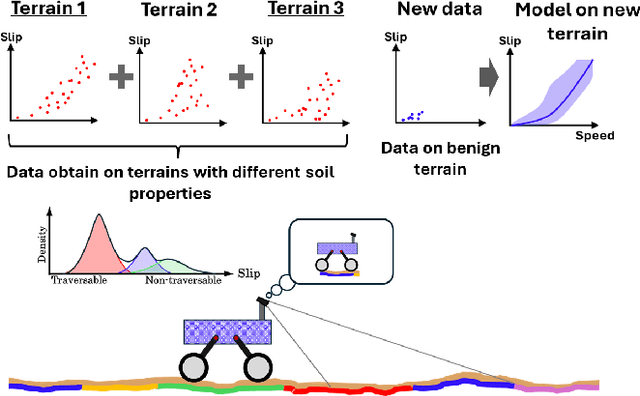
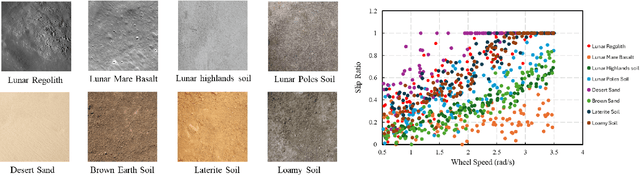
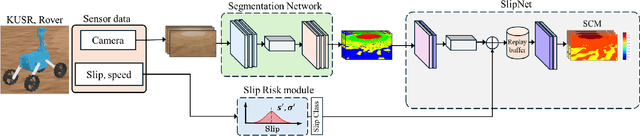
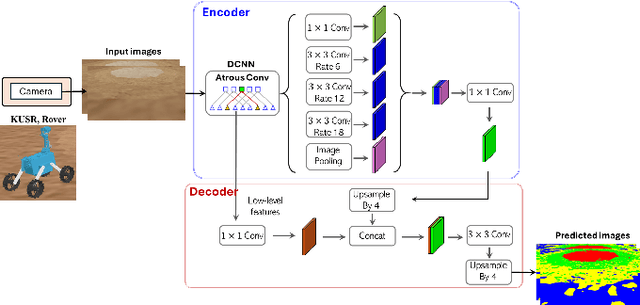
Autonomous space rovers face significant challenges when navigating deformable and heterogeneous terrains during space exploration. The variability in terrain types, influenced by different soil properties, often results in severe wheel slip, compromising navigation efficiency and potentially leading to entrapment. This paper proposes SlipNet, an approach for predicting slip in segmented regions of heterogeneous deformable terrain surfaces to enhance navigation algorithms. Unlike previous methods, SlipNet does not depend on prior terrain classification, reducing prediction errors and misclassifications through dynamic terrain segmentation and slip assignment during deployment while maintaining a history of terrain classes. This adaptive reclassification mechanism has improved prediction performance. Extensive simulation results demonstrate that our model (DeepLab v3+ + SlipNet) achieves better slip prediction performance than the TerrainNet, with a lower mean absolute error (MAE) in five terrain sample tests.
Long-Range Vision-Based UAV-assisted Localization for Unmanned Surface Vehicles
Aug 21, 2024The global positioning system (GPS) has become an indispensable navigation method for field operations with unmanned surface vehicles (USVs) in marine environments. However, GPS may not always be available outdoors because it is vulnerable to natural interference and malicious jamming attacks. Thus, an alternative navigation system is required when the use of GPS is restricted or prohibited. To this end, we present a novel method that utilizes an Unmanned Aerial Vehicle (UAV) to assist in localizing USVs in GNSS-restricted marine environments. In our approach, the UAV flies along the shoreline at a consistent altitude, continuously tracking and detecting the USV using a deep learning-based approach on camera images. Subsequently, triangulation techniques are applied to estimate the USV's position relative to the UAV, utilizing geometric information and datalink range from the UAV. We propose adjusting the UAV's camera angle based on the pixel error between the USV and the image center throughout the localization process to enhance accuracy. Additionally, visual measurements are integrated into an Extended Kalman Filter (EKF) for robust state estimation. To validate our proposed method, we utilize a USV equipped with onboard sensors and a UAV equipped with a camera. A heterogeneous robotic interface is established to facilitate communication between the USV and UAV. We demonstrate the efficacy of our approach through a series of experiments conducted during the ``Muhammad Bin Zayed International Robotic Challenge (MBZIRC-2024)'' in real marine environments, incorporating noisy measurements and ocean disturbances. The successful outcomes indicate the potential of our method to complement GPS for USV navigation.
Neuromorphic Vision-based Motion Segmentation with Graph Transformer Neural Network
Apr 16, 2024



Moving object segmentation is critical to interpret scene dynamics for robotic navigation systems in challenging environments. Neuromorphic vision sensors are tailored for motion perception due to their asynchronous nature, high temporal resolution, and reduced power consumption. However, their unconventional output requires novel perception paradigms to leverage their spatially sparse and temporally dense nature. In this work, we propose a novel event-based motion segmentation algorithm using a Graph Transformer Neural Network, dubbed GTNN. Our proposed algorithm processes event streams as 3D graphs by a series of nonlinear transformations to unveil local and global spatiotemporal correlations between events. Based on these correlations, events belonging to moving objects are segmented from the background without prior knowledge of the dynamic scene geometry. The algorithm is trained on publicly available datasets including MOD, EV-IMO, and \textcolor{black}{EV-IMO2} using the proposed training scheme to facilitate efficient training on extensive datasets. Moreover, we introduce the Dynamic Object Mask-aware Event Labeling (DOMEL) approach for generating approximate ground-truth labels for event-based motion segmentation datasets. We use DOMEL to label our own recorded Event dataset for Motion Segmentation (EMS-DOMEL), which we release to the public for further research and benchmarking. Rigorous experiments are conducted on several unseen publicly-available datasets where the results revealed that GTNN outperforms state-of-the-art methods in the presence of dynamic background variations, motion patterns, and multiple dynamic objects with varying sizes and velocities. GTNN achieves significant performance gains with an average increase of 9.4% and 4.5% in terms of motion segmentation accuracy (IoU%) and detection rate (DR%), respectively.
Early and Accurate Detection of Tomato Leaf Diseases Using TomFormer
Dec 26, 2023Tomato leaf diseases pose a significant challenge for tomato farmers, resulting in substantial reductions in crop productivity. The timely and precise identification of tomato leaf diseases is crucial for successfully implementing disease management strategies. This paper introduces a transformer-based model called TomFormer for the purpose of tomato leaf disease detection. The paper's primary contributions include the following: Firstly, we present a novel approach for detecting tomato leaf diseases by employing a fusion model that combines a visual transformer and a convolutional neural network. Secondly, we aim to apply our proposed methodology to the Hello Stretch robot to achieve real-time diagnosis of tomato leaf diseases. Thirdly, we assessed our method by comparing it to models like YOLOS, DETR, ViT, and Swin, demonstrating its ability to achieve state-of-the-art outcomes. For the purpose of the experiment, we used three datasets of tomato leaf diseases, namely KUTomaDATA, PlantDoc, and PlanVillage, where KUTomaDATA is being collected from a greenhouse in Abu Dhabi, UAE. Finally, we present a comprehensive analysis of the performance of our model and thoroughly discuss the limitations inherent in our approach. TomFormer performed well on the KUTomaDATA, PlantDoc, and PlantVillage datasets, with mean average accuracy (mAP) scores of 87%, 81%, and 83%, respectively. The comparative results in terms of mAP demonstrate that our method exhibits robustness, accuracy, efficiency, and scalability. Furthermore, it can be readily adapted to new datasets. We are confident that our work holds the potential to significantly influence the tomato industry by effectively mitigating crop losses and enhancing crop yields.
MuLA-GAN: Multi-Level Attention GAN for Enhanced Underwater Visibility
Dec 25, 2023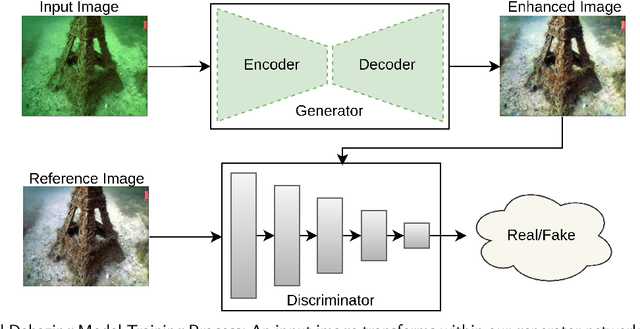

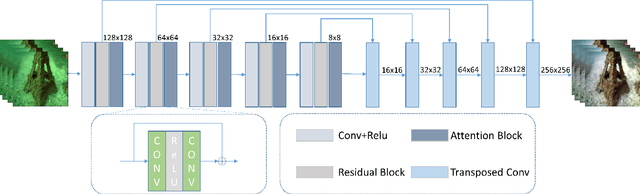

The underwater environment presents unique challenges, including color distortions, reduced contrast, and blurriness, hindering accurate analysis. In this work, we introduce MuLA-GAN, a novel approach that leverages the synergistic power of Generative Adversarial Networks (GANs) and Multi-Level Attention mechanisms for comprehensive underwater image enhancement. The integration of Multi-Level Attention within the GAN architecture significantly enhances the model's capacity to learn discriminative features crucial for precise image restoration. By selectively focusing on relevant spatial and multi-level features, our model excels in capturing and preserving intricate details in underwater imagery, essential for various applications. Extensive qualitative and quantitative analyses on diverse datasets, including UIEB test dataset, UIEB challenge dataset, U45, and UCCS dataset, highlight the superior performance of MuLA-GAN compared to existing state-of-the-art methods. Experimental evaluations on a specialized dataset tailored for bio-fouling and aquaculture applications demonstrate the model's robustness in challenging environmental conditions. On the UIEB test dataset, MuLA-GAN achieves exceptional PSNR (25.59) and SSIM (0.893) scores, surpassing Water-Net, the second-best model, with scores of 24.36 and 0.885, respectively. This work not only addresses a significant research gap in underwater image enhancement but also underscores the pivotal role of Multi-Level Attention in enhancing GANs, providing a novel and comprehensive framework for restoring underwater image quality.