 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLENDER: Blended Text Embeddings and Diffusion Residuals for Intra-Class Image Synthesis in Deep Metric Learning
Jan 28, 2026The rise of Deep Generative Models (DGM) has enabled the generation of high-quality synthetic data. When used to augment authentic data in Deep Metric Learning (DML), these synthetic samples enhance intra-class diversity and improve the performance of downstream DML tasks. We introduce BLenDeR, a diffusion sampling method designed to increase intra-class diversity for DML in a controllable way by leveraging set-theory inspired union and intersection operations on denoising residuals. The union operation encourages any attribute present across multiple prompts, while the intersection extracts the common direction through a principal component surrogate. These operations enable controlled synthesis of diverse attribute combinations within each class, addressing key limitations of existing generative approaches. Experiments on standard DML benchmarks demonstrate that BLenDeR consistently outperforms state-of-the-art baselines across multiple datasets and backbones. Specifically, BLenDeR achieves 3.7% increase in Recall@1 on CUB-200 and a 1.8% increase on Cars-196, compared to state-of-the-art baselines under standard experimental settings.
ViTNT-FIQA: Training-Free Face Image Quality Assessment with Vision Transformers
Jan 09, 2026Face Image Quality Assessment (FIQA) is essential for reliable face recognition systems. Current approaches primarily exploit only final-layer representations, while training-free methods require multiple forward passes or backpropagation. We propose ViTNT-FIQA, a training-free approach that measures the stability of patch embedding evolution across intermediate Vision Transformer (ViT) blocks. We demonstrate that high-quality face images exhibit stable feature refinement trajectories across blocks, while degraded images show erratic transformations. Our method computes Euclidean distances between L2-normalized patch embeddings from consecutive transformer blocks and aggregates them into image-level quality scores. We empirically validate this correlation on a quality-labeled synthetic dataset with controlled degradation levels. Unlike existing training-free approaches, ViTNT-FIQA requires only a single forward pass without backpropagation or architectural modifications. Through extensive evaluation on eight benchmarks (LFW, AgeDB-30, CFP-FP, CALFW, Adience, CPLFW, XQLFW, IJB-C), we show that ViTNT-FIQA achieves competitive performance with state-of-the-art methods while maintaining computational efficiency and immediate applicability to any pre-trained ViT-based face recognition model.
DiffProb: Data Pruning for Face Recognition
May 21, 2025Face recognition models have made substantial progress due to advances in deep learning and the availability of large-scale datasets. However, reliance on massive annotated datasets introduces challenges related to training computational cost and data storage, as well as potential privacy concerns regarding managing large face datasets. This paper presents DiffProb, the first data pruning approach for the application of face recognition. DiffProb assesses the prediction probabilities of training samples within each identity and prunes the ones with identical or close prediction probability values, as they are likely reinforcing the same decision boundaries, and thus contribute minimally with new information. We further enhance this process with an auxiliary cleaning mechanism to eliminate mislabeled and label-flipped samples, boosting data quality with minimal loss. Extensive experiments on CASIA-WebFace with different pruning ratios and multiple benchmarks, including LFW, CFP-FP, and IJB-C, demonstrate that DiffProb can prune up to 50% of the dataset while maintaining or even, in some settings, improving the verification accuracies. Additionally, we demonstrate DiffProb's robustness across different architectures and loss functions. Our method significantly reduces training cost and data volume, enabling efficient face recognition training and reducing the reliance on massive datasets and their demanding management.
Second FRCSyn-onGoing: Winning Solutions and Post-Challenge Analysis to Improve Face Recognition with Synthetic Data
Dec 02, 2024Synthetic data is gaining increasing popularity for face recognition technologies, mainly due to the privacy concerns and challenges associated with obtaining real data, including diverse scenarios, quality, and demographic groups, among others. It also offers some advantages over real data, such as the large amount of data that can be generated or the ability to customize it to adapt to specific problem-solving needs. To effectively use such data, face recognition models should also be specifically designed to exploit synthetic data to its fullest potential. In order to promote the proposal of novel Generative AI methods and synthetic data, and investigate the application of synthetic data to better train face recognition systems, we introduce the 2nd FRCSyn-onGoing challenge, based on the 2nd Face Recognition Challenge in the Era of Synthetic Data (FRCSyn), originally launched at CVPR 2024. This is an ongoing challenge that provides researchers with an accessible platform to benchmark i) the proposal of novel Generative AI methods and synthetic data, and ii) novel face recognition systems that are specifically proposed to take advantage of synthetic data. We focus on exploring the use of synthetic data both individually and in combination with real data to solve current challenges in face recognition such as demographic bias, domain adaptation, and performance constraints in demanding situations, such as age disparities between training and testing, changes in the pose, or occlusions. Very interesting findings are obtained in this second edition, including a direct comparison with the first one, in which synthetic databases were restricted to DCFace and GANDiffFace.
GraFIQs: Face Image Quality Assessment Using Gradient Magnitudes
Apr 18, 2024

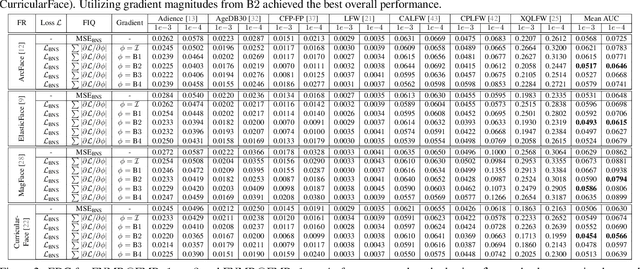
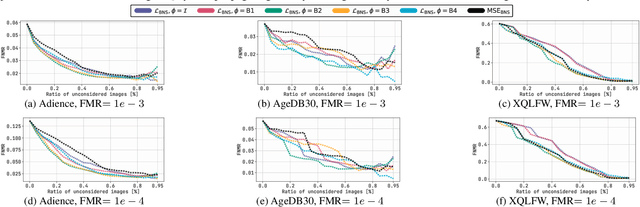
Face Image Quality Assessment (FIQA) estimates the utility of face images for automated face recognition (FR) systems. We propose in this work a novel approach to assess the quality of face images based on inspecting the required changes in the pre-trained FR model weights to minimize differences between testing samples and the distribution of the FR training dataset. To achieve that, we propose quantifying the discrepancy in Batch Normalization statistics (BNS), including mean and variance, between those recorded during FR training and those obtained by processing testing samples through the pretrained FR model. We then generate gradient magnitudes of pretrained FR weights by backpropagating the BNS through the pretrained model. The cumulative absolute sum of these gradient magnitudes serves as the FIQ for our approach. Through comprehensive experimentation, we demonstrate the effectiveness of our training-free and quality labeling-free approach, achieving competitive performance to recent state-of-theart FIQA approaches without relying on quality labeling, the need to train regression networks, specialized architectures, or designing and optimizing specific loss functions.
Second Edition FRCSyn Challenge at CVPR 2024: Face Recognition Challenge in the Era of Synthetic Data
Apr 16, 2024



Synthetic data is gaining increasing relevance for training machine learning models. This is mainly motivated due to several factors such as the lack of real data and intra-class variability, time and errors produced in manual labeling, and in some cases privacy concerns, among others. This paper presents an overview of the 2nd edition of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at CVPR 2024. FRCSyn aims to investigate the use of synthetic data in face recognition to address current technological limitations, including data privacy concerns, demographic biases, generalization to novel scenarios, and performance constraints in challenging situations such as aging, pose variations, and occlusions. Unlike the 1st edition, in which synthetic data from DCFace and GANDiffFace methods was only allowed to train face recognition systems, in this 2nd edition we propose new sub-tasks that allow participants to explore novel face generative methods. The outcomes of the 2nd FRCSyn Challenge, along with the proposed experimental protocol and benchmarking contribute significantly to the application of synthetic data to face recognition.
* arXiv admin note: text overlap with arXiv:2311.10476
Liveness Detection Competition -- Noncontact-based Fingerprint Algorithms and Systems (LivDet-2023 Noncontact Fingerprint)
Oct 01, 2023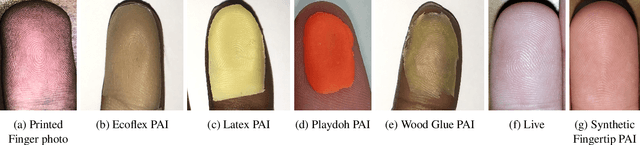


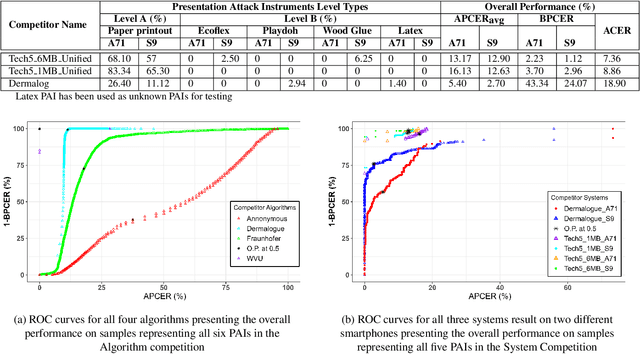
Liveness Detection (LivDet) is an international competition series open to academia and industry with the objec-tive to assess and report state-of-the-art in Presentation Attack Detection (PAD). LivDet-2023 Noncontact Fingerprint is the first edition of the noncontact fingerprint-based PAD competition for algorithms and systems. The competition serves as an important benchmark in noncontact-based fingerprint PAD, offering (a) independent assessment of the state-of-the-art in noncontact-based fingerprint PAD for algorithms and systems, and (b) common evaluation protocol, which includes finger photos of a variety of Presentation Attack Instruments (PAIs) and live fingers to the biometric research community (c) provides standard algorithm and system evaluation protocols, along with the comparative analysis of state-of-the-art algorithms from academia and industry with both old and new android smartphones. The winning algorithm achieved an APCER of 11.35% averaged overall PAIs and a BPCER of 0.62%. The winning system achieved an APCER of 13.0.4%, averaged over all PAIs tested over all the smartphones, and a BPCER of 1.68% over all smartphones tested. Four-finger systems that make individual finger-based PAD decisions were also tested. The dataset used for competition will be available 1 to all researchers as per data share protocol
EFaR 2023: Efficient Face Recognition Competition
Aug 08, 2023



This paper presents the summary of the Efficient Face Recognition Competition (EFaR) held at the 2023 International Joint Conference on Biometrics (IJCB 2023). The competition received 17 submissions from 6 different teams. To drive further development of efficient face recognition models, the submitted solutions are ranked based on a weighted score of the achieved verification accuracies on a diverse set of benchmarks, as well as the deployability given by the number of floating-point operations and model size. The evaluation of submissions is extended to bias, cross-quality, and large-scale recognition benchmarks. Overall, the paper gives an overview of the achieved performance values of the submitted solutions as well as a diverse set of baselines. The submitted solutions use small, efficient network architectures to reduce the computational cost, some solutions apply model quantization. An outlook on possible techniques that are underrepresented in current solutions is given as well.
Identity-driven Three-Player Generative Adversarial Network for Synthetic-based Face Recognition
Apr 30, 2023Many of the commonly used datasets for face recognition development are collected from the internet without proper user consent. Due to the increasing focus on privacy in the social and legal frameworks, the use and distribution of these datasets are being restricted and strongly questioned. These databases, which have a realistically high variability of data per identity, have enabled the success of face recognition models. To build on this success and to align with privacy concerns, synthetic databases, consisting purely of synthetic persons, are increasingly being created and used in the development of face recognition solutions. In this work, we present a three-player generative adversarial network (GAN) framework, namely IDnet, that enables the integration of identity information into the generation process. The third player in our IDnet aims at forcing the generator to learn to generate identity-separable face images. We empirically proved that our IDnet synthetic images are of higher identity discrimination in comparison to the conventional two-player GAN, while maintaining a realistic intra-identity variation. We further studied the identity link between the authentic identities used to train the generator and the generated synthetic identities, showing very low similarities between these identities. We demonstrated the applicability of our IDnet data in training face recognition models by evaluating these models on a wide set of face recognition benchmarks. In comparison to the state-of-the-art works in synthetic-based face recognition, our solution achieved comparable results to a recent rendering-based approach and outperformed all existing GAN-based approaches. The training code and the synthetic face image dataset are publicly available ( https://github.com/fdbtrs/Synthetic-Face-Recognition ).
MorDIFF: Recognition Vulnerability and Attack Detectability of Face Morphing Attacks Created by Diffusion Autoencoders
Feb 03, 2023Investigating new methods of creating face morphing attacks is essential to foresee novel attacks and help mitigate them. Creating morphing attacks is commonly either performed on the image-level or on the representation-level. The representation-level morphing has been performed so far based on generative adversarial networks (GAN) where the encoded images are interpolated in the latent space to produce a morphed image based on the interpolated vector. Such a process was constrained by the limited reconstruction fidelity of GAN architectures. Recent advances in the diffusion autoencoder models have overcome the GAN limitations, leading to high reconstruction fidelity. This theoretically makes them a perfect candidate to perform representation-level face morphing. This work investigates using diffusion autoencoders to create face morphing attacks by comparing them to a wide range of image-level and representation-level morphs. Our vulnerability analyses on four state-of-the-art face recognition models have shown that such models are highly vulnerable to the created attacks, the MorDIFF, especially when compared to existing representation-level morphs. Detailed detectability analyses are also performed on the MorDIFF, showing that they are as challenging to detect as other morphing attacks created on the image- or representation-level. Data and morphing script are made public.