 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentity-driven Three-Player Generative Adversarial Network for Synthetic-based Face Recognition
Apr 30, 2023Many of the commonly used datasets for face recognition development are collected from the internet without proper user consent. Due to the increasing focus on privacy in the social and legal frameworks, the use and distribution of these datasets are being restricted and strongly questioned. These databases, which have a realistically high variability of data per identity, have enabled the success of face recognition models. To build on this success and to align with privacy concerns, synthetic databases, consisting purely of synthetic persons, are increasingly being created and used in the development of face recognition solutions. In this work, we present a three-player generative adversarial network (GAN) framework, namely IDnet, that enables the integration of identity information into the generation process. The third player in our IDnet aims at forcing the generator to learn to generate identity-separable face images. We empirically proved that our IDnet synthetic images are of higher identity discrimination in comparison to the conventional two-player GAN, while maintaining a realistic intra-identity variation. We further studied the identity link between the authentic identities used to train the generator and the generated synthetic identities, showing very low similarities between these identities. We demonstrated the applicability of our IDnet data in training face recognition models by evaluating these models on a wide set of face recognition benchmarks. In comparison to the state-of-the-art works in synthetic-based face recognition, our solution achieved comparable results to a recent rendering-based approach and outperformed all existing GAN-based approaches. The training code and the synthetic face image dataset are publicly available ( https://github.com/fdbtrs/Synthetic-Face-Recognition ).
SFace: Privacy-friendly and Accurate Face Recognition using Synthetic Data
Jun 21, 2022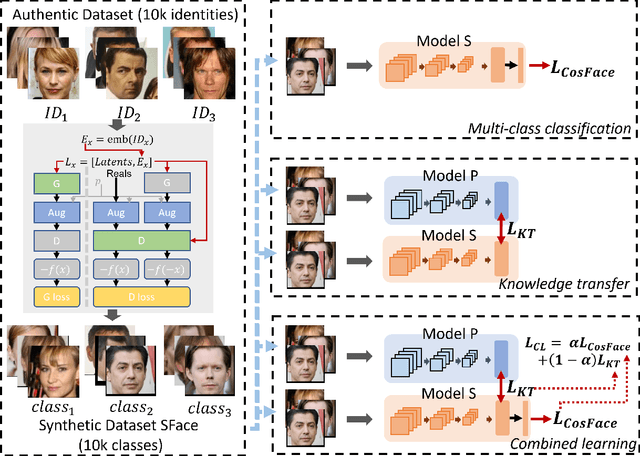

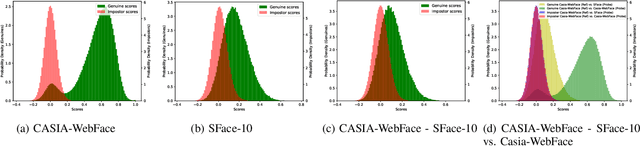

Recent deep face recognition models proposed in the literature utilized large-scale public datasets such as MS-Celeb-1M and VGGFace2 for training very deep neural networks, achieving state-of-the-art performance on mainstream benchmarks. Recently, many of these datasets, e.g., MS-Celeb-1M and VGGFace2, are retracted due to credible privacy and ethical concerns. This motivates this work to propose and investigate the feasibility of using a privacy-friendly synthetically generated face dataset to train face recognition models. Towards this end, we utilize a class-conditional generative adversarial network to generate class-labeled synthetic face images, namely SFace. To address the privacy aspect of using such data to train a face recognition model, we provide extensive evaluation experiments on the identity relation between the synthetic dataset and the original authentic dataset used to train the generative model. Our reported evaluation proved that associating an identity of the authentic dataset to one with the same class label in the synthetic dataset is hardly possible. We also propose to train face recognition on our privacy-friendly dataset, SFace, using three different learning strategies, multi-class classification, label-free knowledge transfer, and combined learning of multi-class classification and knowledge transfer. The reported evaluation results on five authentic face benchmarks demonstrated that the privacy-friendly synthetic dataset has high potential to be used for training face recognition models, achieving, for example, a verification accuracy of 91.87\% on LFW using multi-class classification and 99.13\% using the combined learning strategy.