 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSFace: Privacy-friendly and Accurate Face Recognition using Synthetic Data
Paper and Code
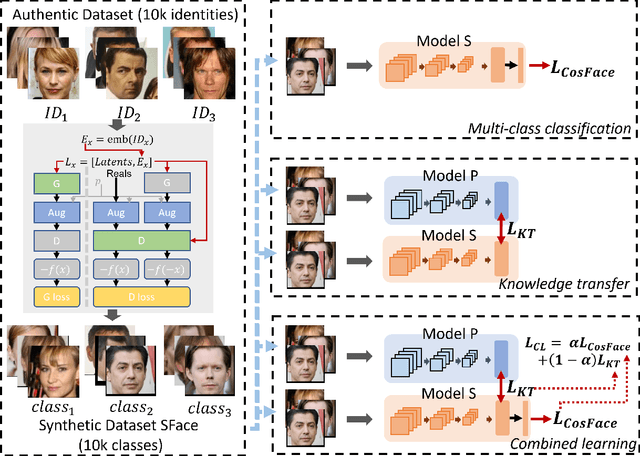

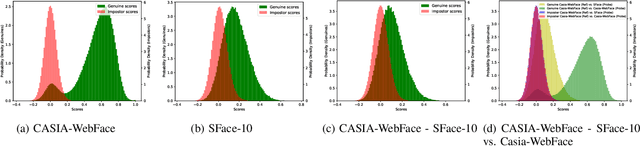

Recent deep face recognition models proposed in the literature utilized large-scale public datasets such as MS-Celeb-1M and VGGFace2 for training very deep neural networks, achieving state-of-the-art performance on mainstream benchmarks. Recently, many of these datasets, e.g., MS-Celeb-1M and VGGFace2, are retracted due to credible privacy and ethical concerns. This motivates this work to propose and investigate the feasibility of using a privacy-friendly synthetically generated face dataset to train face recognition models. Towards this end, we utilize a class-conditional generative adversarial network to generate class-labeled synthetic face images, namely SFace. To address the privacy aspect of using such data to train a face recognition model, we provide extensive evaluation experiments on the identity relation between the synthetic dataset and the original authentic dataset used to train the generative model. Our reported evaluation proved that associating an identity of the authentic dataset to one with the same class label in the synthetic dataset is hardly possible. We also propose to train face recognition on our privacy-friendly dataset, SFace, using three different learning strategies, multi-class classification, label-free knowledge transfer, and combined learning of multi-class classification and knowledge transfer. The reported evaluation results on five authentic face benchmarks demonstrated that the privacy-friendly synthetic dataset has high potential to be used for training face recognition models, achieving, for example, a verification accuracy of 91.87\% on LFW using multi-class classification and 99.13\% using the combined learning strategy.