 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorDIFF: Recognition Vulnerability and Attack Detectability of Face Morphing Attacks Created by Diffusion Autoencoders
Feb 03, 2023Investigating new methods of creating face morphing attacks is essential to foresee novel attacks and help mitigate them. Creating morphing attacks is commonly either performed on the image-level or on the representation-level. The representation-level morphing has been performed so far based on generative adversarial networks (GAN) where the encoded images are interpolated in the latent space to produce a morphed image based on the interpolated vector. Such a process was constrained by the limited reconstruction fidelity of GAN architectures. Recent advances in the diffusion autoencoder models have overcome the GAN limitations, leading to high reconstruction fidelity. This theoretically makes them a perfect candidate to perform representation-level face morphing. This work investigates using diffusion autoencoders to create face morphing attacks by comparing them to a wide range of image-level and representation-level morphs. Our vulnerability analyses on four state-of-the-art face recognition models have shown that such models are highly vulnerable to the created attacks, the MorDIFF, especially when compared to existing representation-level morphs. Detailed detectability analyses are also performed on the MorDIFF, showing that they are as challenging to detect as other morphing attacks created on the image- or representation-level. Data and morphing script are made public.
SFace: Privacy-friendly and Accurate Face Recognition using Synthetic Data
Jun 21, 2022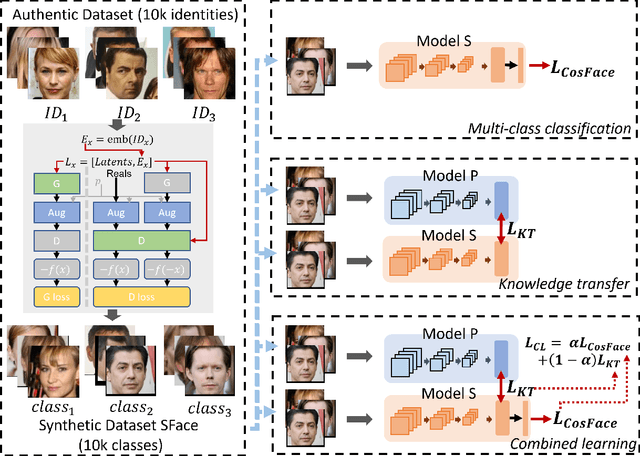

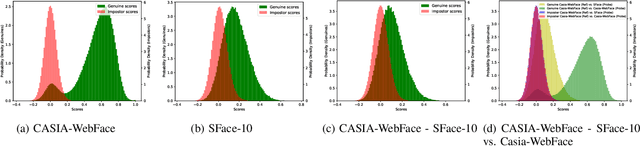

Recent deep face recognition models proposed in the literature utilized large-scale public datasets such as MS-Celeb-1M and VGGFace2 for training very deep neural networks, achieving state-of-the-art performance on mainstream benchmarks. Recently, many of these datasets, e.g., MS-Celeb-1M and VGGFace2, are retracted due to credible privacy and ethical concerns. This motivates this work to propose and investigate the feasibility of using a privacy-friendly synthetically generated face dataset to train face recognition models. Towards this end, we utilize a class-conditional generative adversarial network to generate class-labeled synthetic face images, namely SFace. To address the privacy aspect of using such data to train a face recognition model, we provide extensive evaluation experiments on the identity relation between the synthetic dataset and the original authentic dataset used to train the generative model. Our reported evaluation proved that associating an identity of the authentic dataset to one with the same class label in the synthetic dataset is hardly possible. We also propose to train face recognition on our privacy-friendly dataset, SFace, using three different learning strategies, multi-class classification, label-free knowledge transfer, and combined learning of multi-class classification and knowledge transfer. The reported evaluation results on five authentic face benchmarks demonstrated that the privacy-friendly synthetic dataset has high potential to be used for training face recognition models, achieving, for example, a verification accuracy of 91.87\% on LFW using multi-class classification and 99.13\% using the combined learning strategy.
PocketNet: Extreme Lightweight Face Recognition Network using Neural Architecture Search and Multi-Step Knowledge Distillation
Aug 24, 2021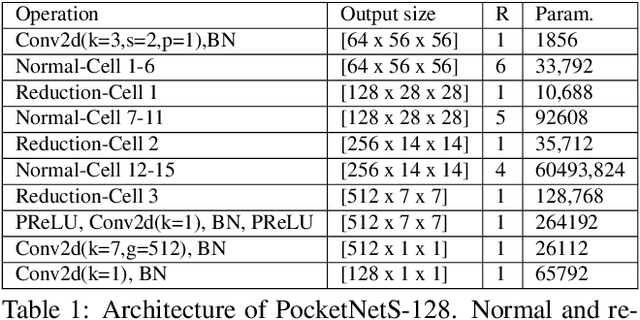
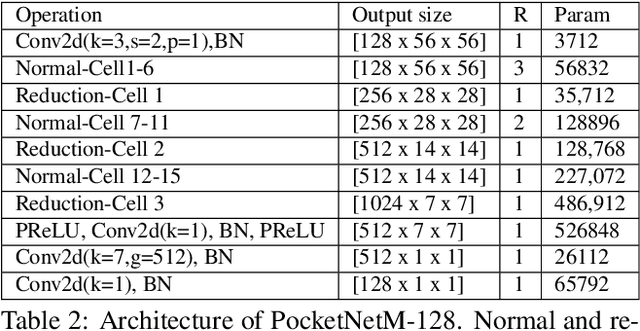
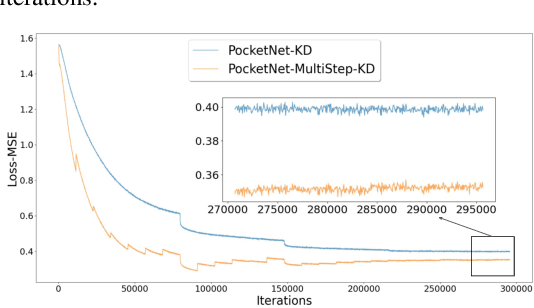
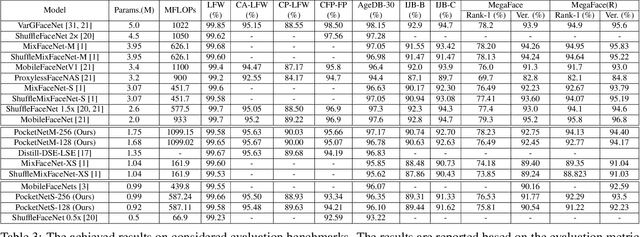
Deep neural networks have rapidly become the mainstream method for face recognition. However, deploying such models that contain an extremely large number of parameters to embedded devices or in application scenarios with limited memory footprint is challenging. In this work, we present an extremely lightweight and accurate face recognition solution. We utilize neural architecture search to develop a new family of face recognition models, namely PocketNet. We also propose to enhance the verification performance of the compact model by presenting a novel training paradigm based on knowledge distillation, namely the multi-step knowledge distillation. We present an extensive experimental evaluation and comparisons with the recent compact face recognition models on nine different benchmarks including large-scale evaluation benchmarks such as IJB-B, IJB-C, and MegaFace. PocketNets have consistently advanced the state-of-the-art (SOTA) face recognition performance on nine mainstream benchmarks when considering the same level of model compactness. With 0.92M parameters, our smallest network PocketNetS-128 achieved very competitive results to recent SOTA compacted models that contain more than 4M parameters. Training codes and pre-trained models are publicly released https://github.com/fdbtrs/PocketNet.