 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViTNT-FIQA: Training-Free Face Image Quality Assessment with Vision Transformers
Jan 09, 2026Face Image Quality Assessment (FIQA) is essential for reliable face recognition systems. Current approaches primarily exploit only final-layer representations, while training-free methods require multiple forward passes or backpropagation. We propose ViTNT-FIQA, a training-free approach that measures the stability of patch embedding evolution across intermediate Vision Transformer (ViT) blocks. We demonstrate that high-quality face images exhibit stable feature refinement trajectories across blocks, while degraded images show erratic transformations. Our method computes Euclidean distances between L2-normalized patch embeddings from consecutive transformer blocks and aggregates them into image-level quality scores. We empirically validate this correlation on a quality-labeled synthetic dataset with controlled degradation levels. Unlike existing training-free approaches, ViTNT-FIQA requires only a single forward pass without backpropagation or architectural modifications. Through extensive evaluation on eight benchmarks (LFW, AgeDB-30, CFP-FP, CALFW, Adience, CPLFW, XQLFW, IJB-C), we show that ViTNT-FIQA achieves competitive performance with state-of-the-art methods while maintaining computational efficiency and immediate applicability to any pre-trained ViT-based face recognition model.
MADPromptS: Unlocking Zero-Shot Morphing Attack Detection with Multiple Prompt Aggregation
Aug 12, 2025Face Morphing Attack Detection (MAD) is a critical challenge in face recognition security, where attackers can fool systems by interpolating the identity information of two or more individuals into a single face image, resulting in samples that can be verified as belonging to multiple identities by face recognition systems. While multimodal foundation models (FMs) like CLIP offer strong zero-shot capabilities by jointly modeling images and text, most prior works on FMs for biometric recognition have relied on fine-tuning for specific downstream tasks, neglecting their potential for direct, generalizable deployment. This work explores a pure zero-shot approach to MAD by leveraging CLIP without any additional training or fine-tuning, focusing instead on the design and aggregation of multiple textual prompts per class. By aggregating the embeddings of diverse prompts, we better align the model's internal representations with the MAD task, capturing richer and more varied cues indicative of bona-fide or attack samples. Our results show that prompt aggregation substantially improves zero-shot detection performance, demonstrating the effectiveness of exploiting foundation models' built-in multimodal knowledge through efficient prompt engineering.
DiffProb: Data Pruning for Face Recognition
May 21, 2025Face recognition models have made substantial progress due to advances in deep learning and the availability of large-scale datasets. However, reliance on massive annotated datasets introduces challenges related to training computational cost and data storage, as well as potential privacy concerns regarding managing large face datasets. This paper presents DiffProb, the first data pruning approach for the application of face recognition. DiffProb assesses the prediction probabilities of training samples within each identity and prunes the ones with identical or close prediction probability values, as they are likely reinforcing the same decision boundaries, and thus contribute minimally with new information. We further enhance this process with an auxiliary cleaning mechanism to eliminate mislabeled and label-flipped samples, boosting data quality with minimal loss. Extensive experiments on CASIA-WebFace with different pruning ratios and multiple benchmarks, including LFW, CFP-FP, and IJB-C, demonstrate that DiffProb can prune up to 50% of the dataset while maintaining or even, in some settings, improving the verification accuracies. Additionally, we demonstrate DiffProb's robustness across different architectures and loss functions. Our method significantly reduces training cost and data volume, enabling efficient face recognition training and reducing the reliance on massive datasets and their demanding management.
MADation: Face Morphing Attack Detection with Foundation Models
Jan 08, 2025Despite the considerable performance improvements of face recognition algorithms in recent years, the same scientific advances responsible for this progress can also be used to create efficient ways to attack them, posing a threat to their secure deployment. Morphing attack detection (MAD) systems aim to detect a specific type of threat, morphing attacks, at an early stage, preventing them from being considered for verification in critical processes. Foundation models (FM) learn from extensive amounts of unlabeled data, achieving remarkable zero-shot generalization to unseen domains. Although this generalization capacity might be weak when dealing with domain-specific downstream tasks such as MAD, FMs can easily adapt to these settings while retaining the built-in knowledge acquired during pre-training. In this work, we recognize the potential of FMs to perform well in the MAD task when properly adapted to its specificities. To this end, we adapt FM CLIP architectures with LoRA weights while simultaneously training a classification header. The proposed framework, MADation surpasses our alternative FM and transformer-based frameworks and constitutes the first adaption of FMs to the MAD task. MADation presents competitive results with current MAD solutions in the literature and even surpasses them in several evaluation scenarios. To encourage reproducibility and facilitate further research in MAD, we publicly release the implementation of MADation at https: //github.com/gurayozgur/MADation
FoundPAD: Foundation Models Reloaded for Face Presentation Attack Detection
Jan 06, 2025
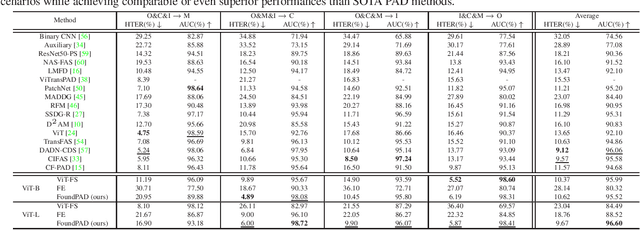
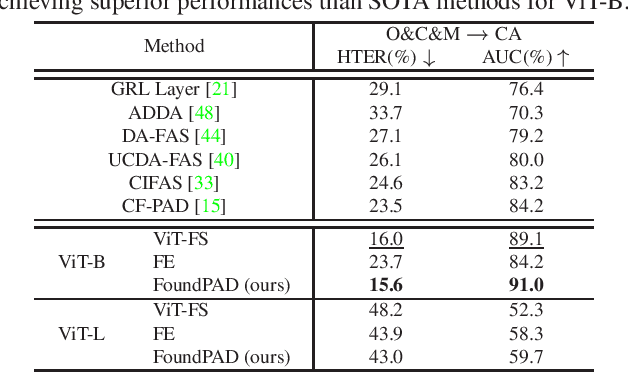
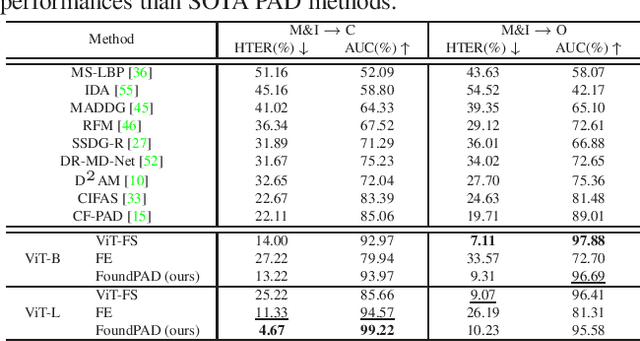
Although face recognition systems have seen a massive performance enhancement in recent years, they are still targeted by threats such as presentation attacks, leading to the need for generalizable presentation attack detection (PAD) algorithms. Current PAD solutions suffer from two main problems: low generalization to unknown cenarios and large training data requirements. Foundation models (FM) are pre-trained on extensive datasets, achieving remarkable results when generalizing to unseen domains and allowing for efficient task-specific adaption even when little training data are available. In this work, we recognize the potential of FMs to address common PAD problems and tackle the PAD task with an adapted FM for the first time. The FM under consideration is adapted with LoRA weights while simultaneously training a classification header. The resultant architecture, FoundPAD, is highly generalizable to unseen domains, achieving competitive results in several settings under different data availability scenarios and even when using synthetic training data. To encourage reproducibility and facilitate further research in PAD, we publicly release the implementation of FoundPAD at https://github.com/gurayozgur/FoundPAD .
MST-KD: Multiple Specialized Teachers Knowledge Distillation for Fair Face Recognition
Aug 29, 2024



As in school, one teacher to cover all subjects is insufficient to distill equally robust information to a student. Hence, each subject is taught by a highly specialised teacher. Following a similar philosophy, we propose a multiple specialized teacher framework to distill knowledge to a student network. In our approach, directed at face recognition use cases, we train four teachers on one specific ethnicity, leading to four highly specialized and biased teachers. Our strategy learns a project of these four teachers into a common space and distill that information to a student network. Our results highlighted increased performance and reduced bias for all our experiments. In addition, we further show that having biased/specialized teachers is crucial by showing that our approach achieves better results than when knowledge is distilled from four teachers trained on balanced datasets. Our approach represents a step forward to the understanding of the importance of ethnicity-specific features.
Model Compression Techniques in Biometrics Applications: A Survey
Jan 18, 2024
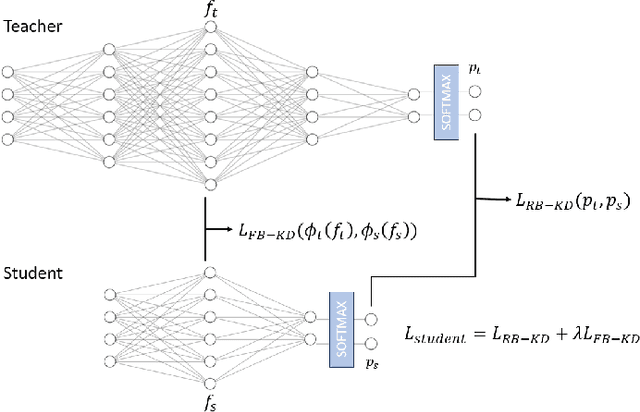
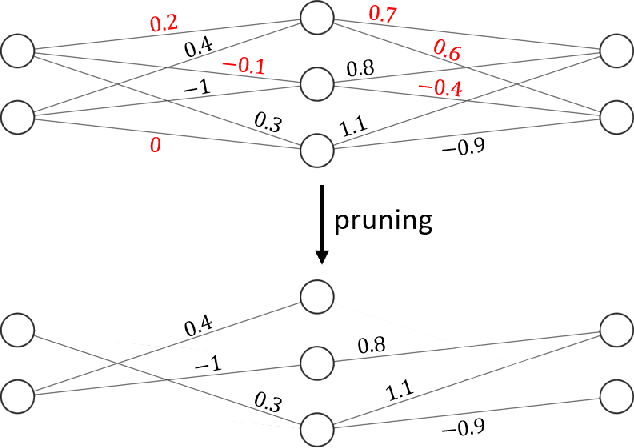
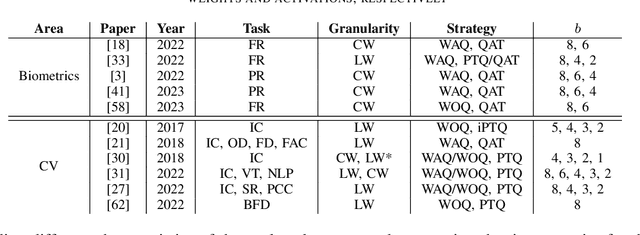
The development of deep learning algorithms has extensively empowered humanity's task automatization capacity. However, the huge improvement in the performance of these models is highly correlated with their increasing level of complexity, limiting their usefulness in human-oriented applications, which are usually deployed in resource-constrained devices. This led to the development of compression techniques that drastically reduce the computational and memory costs of deep learning models without significant performance degradation. This paper aims to systematize the current literature on this topic by presenting a comprehensive survey of model compression techniques in biometrics applications, namely quantization, knowledge distillation and pruning. We conduct a critical analysis of the comparative value of these techniques, focusing on their advantages and disadvantages and presenting suggestions for future work directions that can potentially improve the current methods. Additionally, we discuss and analyze the link between model bias and model compression, highlighting the need to direct compression research toward model fairness in future works.
Compressed Models Decompress Race Biases: What Quantized Models Forget for Fair Face Recognition
Aug 23, 2023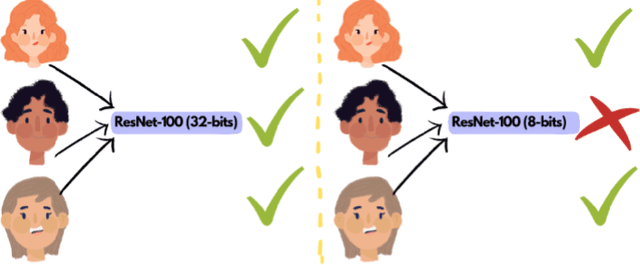
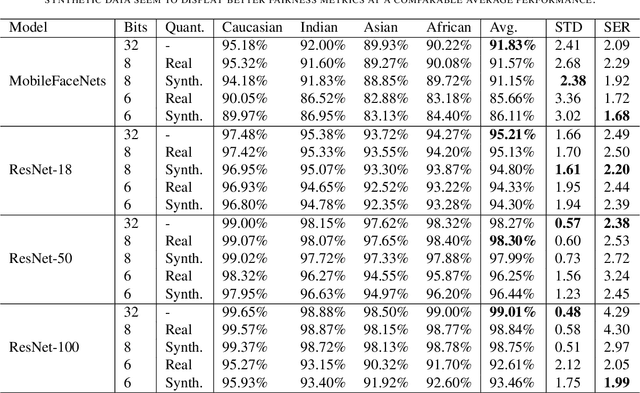
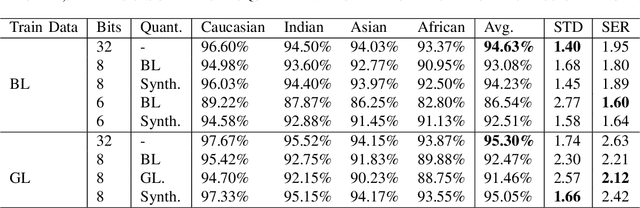
With the ever-growing complexity of deep learning models for face recognition, it becomes hard to deploy these systems in real life. Researchers have two options: 1) use smaller models; 2) compress their current models. Since the usage of smaller models might lead to concerning biases, compression gains relevance. However, compressing might be also responsible for an increase in the bias of the final model. We investigate the overall performance, the performance on each ethnicity subgroup and the racial bias of a State-of-the-Art quantization approach when used with synthetic and real data. This analysis provides a few more details on potential benefits of performing quantization with synthetic data, for instance, the reduction of biases on the majority of test scenarios. We tested five distinct architectures and three different training datasets. The models were evaluated on a fourth dataset which was collected to infer and compare the performance of face recognition models on different ethnicity.
Unveiling the Two-Faced Truth: Disentangling Morphed Identities for Face Morphing Detection
Jun 05, 2023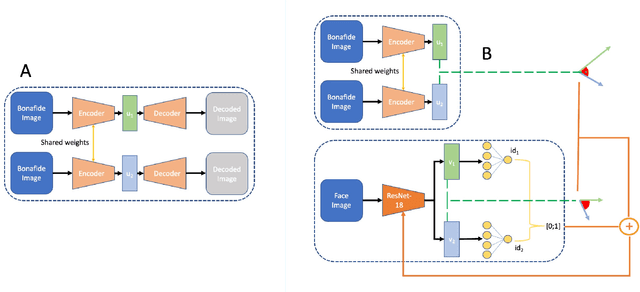

Morphing attacks keep threatening biometric systems, especially face recognition systems. Over time they have become simpler to perform and more realistic, as such, the usage of deep learning systems to detect these attacks has grown. At the same time, there is a constant concern regarding the lack of interpretability of deep learning models. Balancing performance and interpretability has been a difficult task for scientists. However, by leveraging domain information and proving some constraints, we have been able to develop IDistill, an interpretable method with state-of-the-art performance that provides information on both the identity separation on morph samples and their contribution to the final prediction. The domain information is learnt by an autoencoder and distilled to a classifier system in order to teach it to separate identity information. When compared to other methods in the literature it outperforms them in three out of five databases and is competitive in the remaining.