 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViTNT-FIQA: Training-Free Face Image Quality Assessment with Vision Transformers
Jan 09, 2026Face Image Quality Assessment (FIQA) is essential for reliable face recognition systems. Current approaches primarily exploit only final-layer representations, while training-free methods require multiple forward passes or backpropagation. We propose ViTNT-FIQA, a training-free approach that measures the stability of patch embedding evolution across intermediate Vision Transformer (ViT) blocks. We demonstrate that high-quality face images exhibit stable feature refinement trajectories across blocks, while degraded images show erratic transformations. Our method computes Euclidean distances between L2-normalized patch embeddings from consecutive transformer blocks and aggregates them into image-level quality scores. We empirically validate this correlation on a quality-labeled synthetic dataset with controlled degradation levels. Unlike existing training-free approaches, ViTNT-FIQA requires only a single forward pass without backpropagation or architectural modifications. Through extensive evaluation on eight benchmarks (LFW, AgeDB-30, CFP-FP, CALFW, Adience, CPLFW, XQLFW, IJB-C), we show that ViTNT-FIQA achieves competitive performance with state-of-the-art methods while maintaining computational efficiency and immediate applicability to any pre-trained ViT-based face recognition model.
Trade-offs in Cross-Domain Generalization of Foundation Model Fine-Tuned for Biometric Applications
Sep 18, 2025Foundation models such as CLIP have demonstrated exceptional zero- and few-shot transfer capabilities across diverse vision tasks. However, when fine-tuned for highly specialized biometric tasks, face recognition (FR), morphing attack detection (MAD), and presentation attack detection (PAD), these models may suffer from over-specialization. Thus, they may lose one of their foundational strengths, cross-domain generalization. In this work, we systematically quantify these trade-offs by evaluating three instances of CLIP fine-tuned for FR, MAD, and PAD. We evaluate each adapted model as well as the original CLIP baseline on 14 general vision datasets under zero-shot and linear-probe protocols, alongside common FR, MAD, and PAD benchmarks. Our results indicate that fine-tuned models suffer from over-specialization, especially when fine-tuned for complex tasks of FR. Also, our results pointed out that task complexity and classification head design, multi-class (FR) vs. binary (MAD and PAD), correlate with the degree of catastrophic forgetting. The FRoundation model with the ViT-L backbone outperforms other approaches on the large-scale FR benchmark IJB-C, achieving an improvement of up to 58.52%. However, it experiences a substantial performance drop on ImageNetV2, reaching only 51.63% compared to 69.84% achieved by the baseline CLIP model. Moreover, the larger CLIP architecture consistently preserves more of the model's original generalization ability than the smaller variant, indicating that increased model capacity may help mitigate over-specialization.
MADation: Face Morphing Attack Detection with Foundation Models
Jan 08, 2025Despite the considerable performance improvements of face recognition algorithms in recent years, the same scientific advances responsible for this progress can also be used to create efficient ways to attack them, posing a threat to their secure deployment. Morphing attack detection (MAD) systems aim to detect a specific type of threat, morphing attacks, at an early stage, preventing them from being considered for verification in critical processes. Foundation models (FM) learn from extensive amounts of unlabeled data, achieving remarkable zero-shot generalization to unseen domains. Although this generalization capacity might be weak when dealing with domain-specific downstream tasks such as MAD, FMs can easily adapt to these settings while retaining the built-in knowledge acquired during pre-training. In this work, we recognize the potential of FMs to perform well in the MAD task when properly adapted to its specificities. To this end, we adapt FM CLIP architectures with LoRA weights while simultaneously training a classification header. The proposed framework, MADation surpasses our alternative FM and transformer-based frameworks and constitutes the first adaption of FMs to the MAD task. MADation presents competitive results with current MAD solutions in the literature and even surpasses them in several evaluation scenarios. To encourage reproducibility and facilitate further research in MAD, we publicly release the implementation of MADation at https: //github.com/gurayozgur/MADation
FoundPAD: Foundation Models Reloaded for Face Presentation Attack Detection
Jan 06, 2025
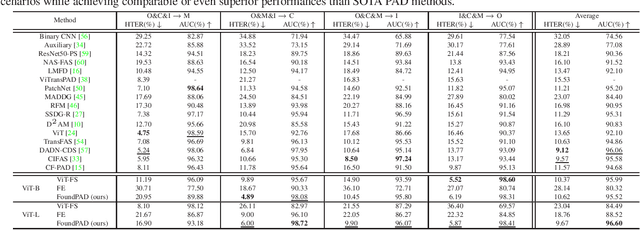
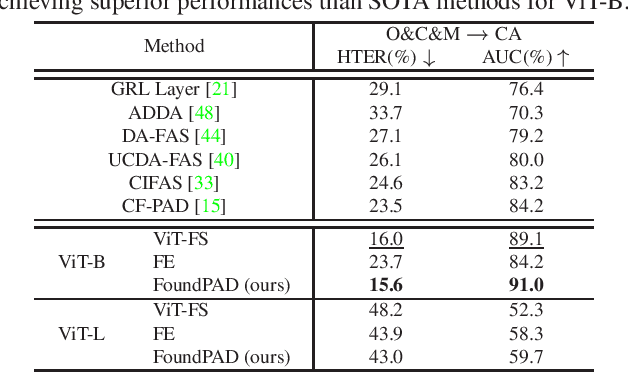
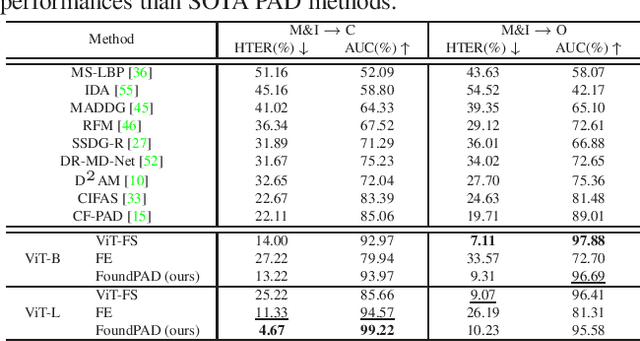
Although face recognition systems have seen a massive performance enhancement in recent years, they are still targeted by threats such as presentation attacks, leading to the need for generalizable presentation attack detection (PAD) algorithms. Current PAD solutions suffer from two main problems: low generalization to unknown cenarios and large training data requirements. Foundation models (FM) are pre-trained on extensive datasets, achieving remarkable results when generalizing to unseen domains and allowing for efficient task-specific adaption even when little training data are available. In this work, we recognize the potential of FMs to address common PAD problems and tackle the PAD task with an adapted FM for the first time. The FM under consideration is adapted with LoRA weights while simultaneously training a classification header. The resultant architecture, FoundPAD, is highly generalizable to unseen domains, achieving competitive results in several settings under different data availability scenarios and even when using synthetic training data. To encourage reproducibility and facilitate further research in PAD, we publicly release the implementation of FoundPAD at https://github.com/gurayozgur/FoundPAD .
FRoundation: Are Foundation Models Ready for Face Recognition?
Oct 31, 2024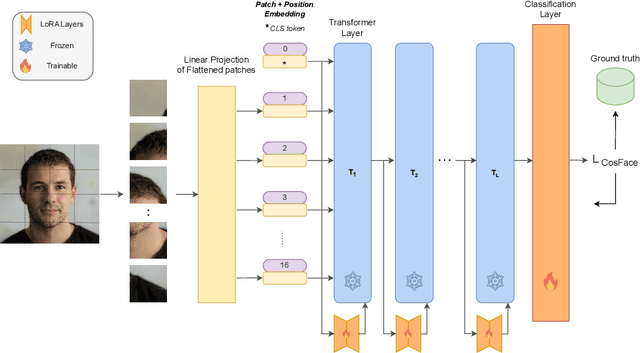
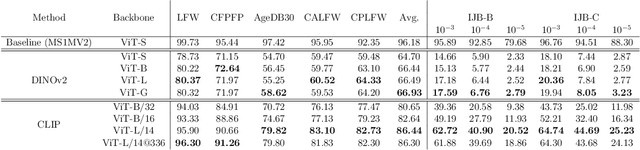
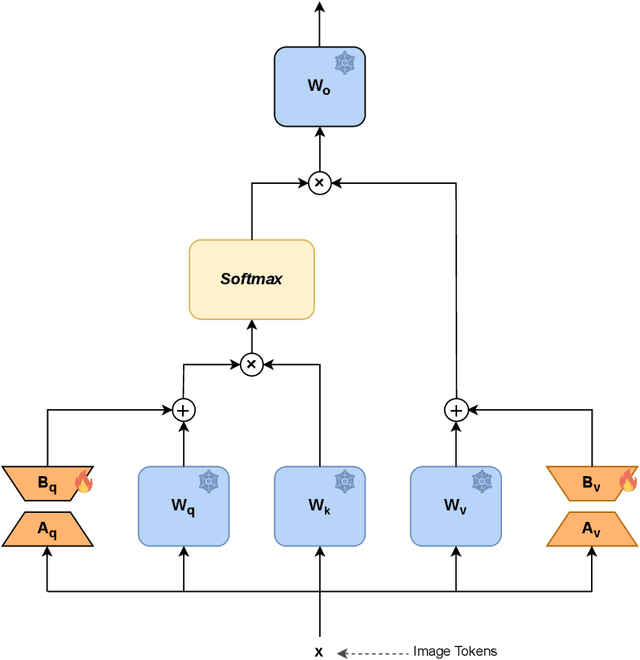
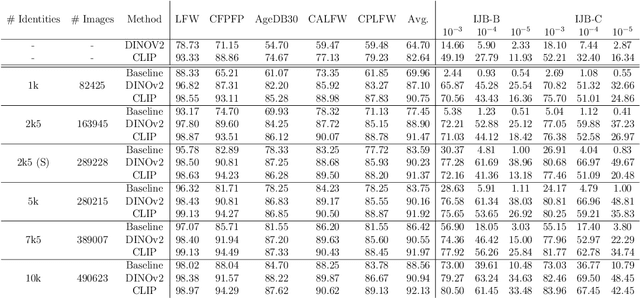
Foundation models are predominantly trained in an unsupervised or self-supervised manner on highly diverse and large-scale datasets, making them broadly applicable to various downstream tasks. In this work, we investigate for the first time whether such models are suitable for the specific domain of face recognition. We further propose and demonstrate the adaptation of these models for face recognition across different levels of data availability. Extensive experiments are conducted on multiple foundation models and datasets of varying scales for training and fine-tuning, with evaluation on a wide range of benchmarks. Our results indicate that, despite their versatility, pre-trained foundation models underperform in face recognition compared to similar architectures trained specifically for this task. However, fine-tuning foundation models yields promising results, often surpassing models trained from scratch when training data is limited. Even with access to large-scale face recognition training datasets, fine-tuned foundation models perform comparably to models trained from scratch, but with lower training computational costs and without relying on the assumption of extensive data availability. Our analysis also explores bias in face recognition, with slightly higher bias observed in some settings when using foundation models.