 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMADation: Face Morphing Attack Detection with Foundation Models
Jan 08, 2025Despite the considerable performance improvements of face recognition algorithms in recent years, the same scientific advances responsible for this progress can also be used to create efficient ways to attack them, posing a threat to their secure deployment. Morphing attack detection (MAD) systems aim to detect a specific type of threat, morphing attacks, at an early stage, preventing them from being considered for verification in critical processes. Foundation models (FM) learn from extensive amounts of unlabeled data, achieving remarkable zero-shot generalization to unseen domains. Although this generalization capacity might be weak when dealing with domain-specific downstream tasks such as MAD, FMs can easily adapt to these settings while retaining the built-in knowledge acquired during pre-training. In this work, we recognize the potential of FMs to perform well in the MAD task when properly adapted to its specificities. To this end, we adapt FM CLIP architectures with LoRA weights while simultaneously training a classification header. The proposed framework, MADation surpasses our alternative FM and transformer-based frameworks and constitutes the first adaption of FMs to the MAD task. MADation presents competitive results with current MAD solutions in the literature and even surpasses them in several evaluation scenarios. To encourage reproducibility and facilitate further research in MAD, we publicly release the implementation of MADation at https: //github.com/gurayozgur/MADation
TomatoDIFF: On-plant Tomato Segmentation with Denoising Diffusion Models
Jul 03, 2023Artificial intelligence applications enable farmers to optimize crop growth and production while reducing costs and environmental impact. Computer vision-based algorithms in particular, are commonly used for fruit segmentation, enabling in-depth analysis of the harvest quality and accurate yield estimation. In this paper, we propose TomatoDIFF, a novel diffusion-based model for semantic segmentation of on-plant tomatoes. When evaluated against other competitive methods, our model demonstrates state-of-the-art (SOTA) performance, even in challenging environments with highly occluded fruits. Additionally, we introduce Tomatopia, a new, large and challenging dataset of greenhouse tomatoes. The dataset comprises high-resolution RGB-D images and pixel-level annotations of the fruits.
Synthetic Data for Face Recognition: Current State and Future Prospects
May 01, 2023Over the past years, deep learning capabilities and the availability of large-scale training datasets advanced rapidly, leading to breakthroughs in face recognition accuracy. However, these technologies are foreseen to face a major challenge in the next years due to the legal and ethical concerns about using authentic biometric data in AI model training and evaluation along with increasingly utilizing data-hungry state-of-the-art deep learning models. With the recent advances in deep generative models and their success in generating realistic and high-resolution synthetic image data, privacy-friendly synthetic data has been recently proposed as an alternative to privacy-sensitive authentic data to overcome the challenges of using authentic data in face recognition development. This work aims at providing a clear and structured picture of the use-cases taxonomy of synthetic face data in face recognition along with the recent emerging advances of face recognition models developed on the bases of synthetic data. We also discuss the challenges facing the use of synthetic data in face recognition development and several future prospects of synthetic data in the domain of face recognition.
SeeABLE: Soft Discrepancies and Bounded Contrastive Learning for Exposing Deepfakes
Nov 21, 2022Modern deepfake detectors have achieved encouraging results, when training and test images are drawn from the same collection. However, when applying these detectors to faces manipulated using an unknown technique, considerable performance drops are typically observed. In this work, we propose a novel deepfake detector, called SeeABLE, that formalizes the detection problem as a (one-class) out-of-distribution detection task and generalizes better to unseen deepfakes. Specifically, SeeABLE uses a novel data augmentation strategy to synthesize fine-grained local image anomalies (referred to as soft-discrepancies) and pushes those pristine disrupted faces towards predefined prototypes using a novel regression-based bounded contrastive loss. To strengthen the generalization performance of SeeABLE to unknown deepfake types, we generate a rich set of soft discrepancies and train the detector: (i) to localize, which part of the face was modified, and (ii) to identify the alteration type. Using extensive experiments on widely used datasets, SeeABLE considerably outperforms existing detectors, with gains of up to +10\% on the DFDC-preview dataset in term of detection accuracy over SoTA methods while using a simpler model. Code will be made publicly available.
Fairness in Face Presentation Attack Detection
Sep 19, 2022
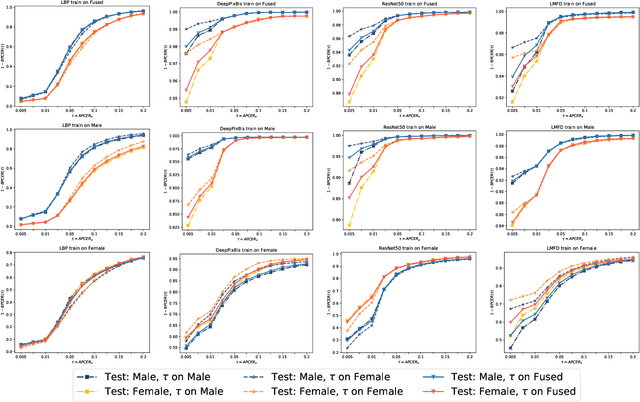
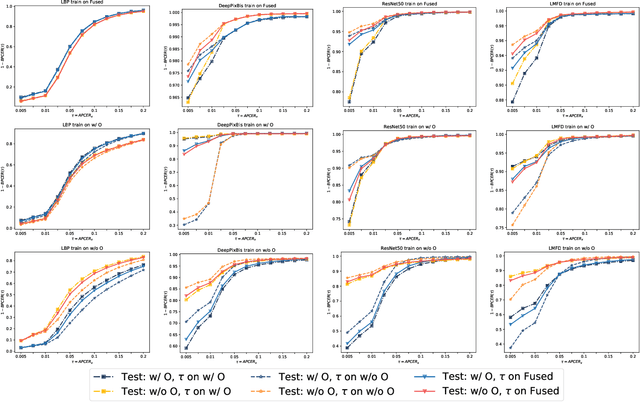

Face presentation attack detection (PAD) is critical to secure face recognition (FR) applications from presentation attacks. FR performance has been shown to be unfair to certain demographic and non-demographic groups. However, the fairness of face PAD is an understudied issue, mainly due to the lack of appropriately annotated data. To address this issue, this work first presents a Combined Attribute Annotated PAD Dataset (CAAD-PAD) by combining several well-known PAD datasets where we provide seven human-annotated attribute labels. This work then comprehensively analyses the fairness of a set of face PADs and its relation to the nature of training data and the Operational Decision Threshold Assignment (ODTA) on different data groups by studying four face PAD approaches on our CAAD-PAD. To simultaneously represent both the PAD fairness and the absolute PAD performance, we introduce a novel metric, namely the Accuracy Balanced Fairness (ABF). Extensive experiments on CAAD-PAD show that the training data and ODTA induce unfairness on gender, occlusion, and other attribute groups. Based on these analyses, we propose a data augmentation method, FairSWAP, which aims to disrupt the identity/semantic information and guide models to mine attack cues rather than attribute-related information. Detailed experimental results demonstrate that FairSWAP generally enhances both the PAD performance and the fairness of face PAD.
To Frontalize or Not To Frontalize: Do We Really Need Elaborate Pre-processing To Improve Face Recognition?
Mar 27, 2018

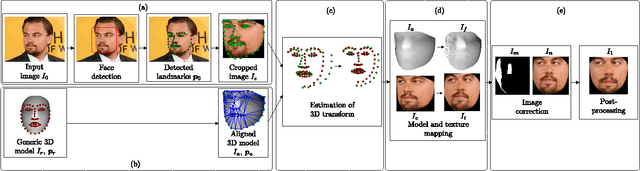
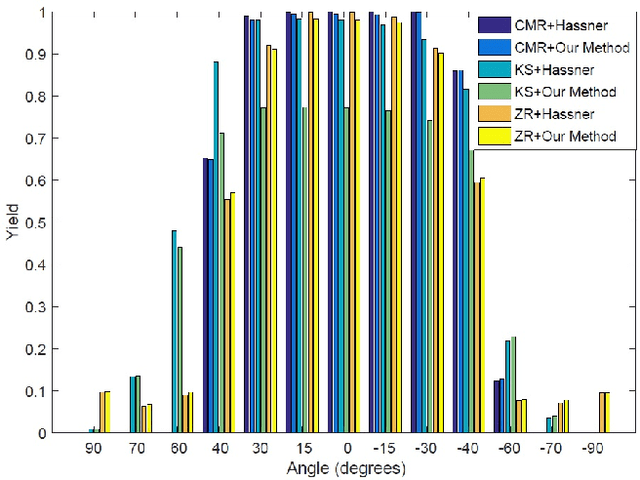
Face recognition performance has improved remarkably in the last decade. Much of this success can be attributed to the development of deep learning techniques such as convolutional neural networks (CNNs). While CNNs have pushed the state-of-the-art forward, their training process requires a large amount of clean and correctly labelled training data. If a CNN is intended to tolerate facial pose, then we face an important question: should this training data be diverse in its pose distribution, or should face images be normalized to a single pose in a pre-processing step? To address this question, we evaluate a number of popular facial landmarking and pose correction algorithms to understand their effect on facial recognition performance. Additionally, we introduce a new, automatic, single-image frontalization scheme that exceeds the performance of current algorithms. CNNs trained using sets of different pre-processing methods are used to extract features from the Point and Shoot Challenge (PaSC) and CMU Multi-PIE datasets. We assert that the subsequent verification and recognition performance serves to quantify the effectiveness of each pose correction scheme.
UG^2: a Video Benchmark for Assessing the Impact of Image Restoration and Enhancement on Automatic Visual Recognition
Feb 07, 2018
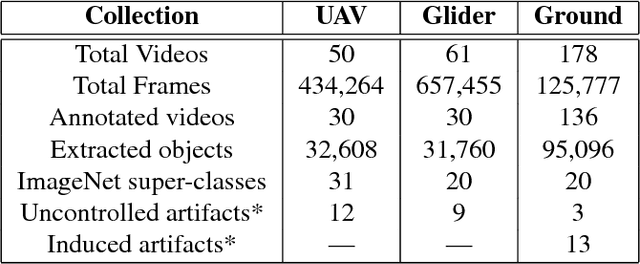


Advances in image restoration and enhancement techniques have led to discussion about how such algorithmscan be applied as a pre-processing step to improve automatic visual recognition. In principle, techniques like deblurring and super-resolution should yield improvements by de-emphasizing noise and increasing signal in an input image. But the historically divergent goals of the computational photography and visual recognition communities have created a significant need for more work in this direction. To facilitate new research, we introduce a new benchmark dataset called UG^2, which contains three difficult real-world scenarios: uncontrolled videos taken by UAVs and manned gliders, as well as controlled videos taken on the ground. Over 160,000 annotated frames forhundreds of ImageNet classes are available, which are used for baseline experiments that assess the impact of known and unknown image artifacts and other conditions on common deep learning-based object classification approaches. Further, current image restoration and enhancement techniques are evaluated by determining whether or not theyimprove baseline classification performance. Results showthat there is plenty of room for algorithmic innovation, making this dataset a useful tool going forward.