 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRight Looks, Wrong Reasons: Compositional Fidelity in Text-to-Image Generation
Nov 13, 2025The architectural blueprint of today's leading text-to-image models contains a fundamental flaw: an inability to handle logical composition. This survey investigates this breakdown across three core primitives-negation, counting, and spatial relations. Our analysis reveals a dramatic performance collapse: models that are accurate on single primitives fail precipitously when these are combined, exposing severe interference. We trace this failure to three key factors. First, training data show a near-total absence of explicit negations. Second, continuous attention architectures are fundamentally unsuitable for discrete logic. Third, evaluation metrics reward visual plausibility over constraint satisfaction. By analyzing recent benchmarks and methods, we show that current solutions and simple scaling cannot bridge this gap. Achieving genuine compositionality, we conclude, will require fundamental advances in representation and reasoning rather than incremental adjustments to existing architectures.
Is Perturbation-Based Image Protection Disruptive to Image Editing?
Jun 04, 2025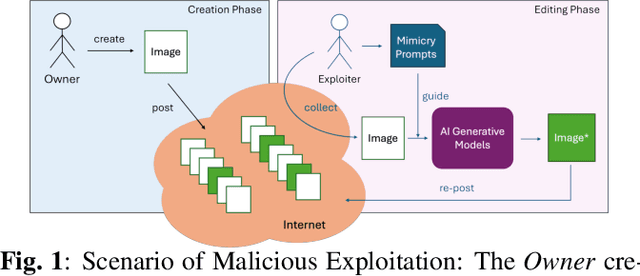



The remarkable image generation capabilities of state-of-the-art diffusion models, such as Stable Diffusion, can also be misused to spread misinformation and plagiarize copyrighted materials. To mitigate the potential risks associated with image editing, current image protection methods rely on adding imperceptible perturbations to images to obstruct diffusion-based editing. A fully successful protection for an image implies that the output of editing attempts is an undesirable, noisy image which is completely unrelated to the reference image. In our experiments with various perturbation-based image protection methods across multiple domains (natural scene images and artworks) and editing tasks (image-to-image generation and style editing), we discover that such protection does not achieve this goal completely. In most scenarios, diffusion-based editing of protected images generates a desirable output image which adheres precisely to the guidance prompt. Our findings suggest that adding noise to images may paradoxically increase their association with given text prompts during the generation process, leading to unintended consequences such as better resultant edits. Hence, we argue that perturbation-based methods may not provide a sufficient solution for robust image protection against diffusion-based editing.
Learn "No" to Say "Yes" Better: Improving Vision-Language Models via Negations
Mar 29, 2024



Existing vision-language models (VLMs) treat text descriptions as a unit, confusing individual concepts in a prompt and impairing visual semantic matching and reasoning. An important aspect of reasoning in logic and language is negations. This paper highlights the limitations of popular VLMs such as CLIP, at understanding the implications of negations, i.e., the effect of the word "not" in a given prompt. To enable evaluation of VLMs on fluent prompts with negations, we present CC-Neg, a dataset containing 228,246 images, true captions and their corresponding negated captions. Using CC-Neg along with modifications to the contrastive loss of CLIP, our proposed CoN-CLIP framework, has an improved understanding of negations. This training paradigm improves CoN-CLIP's ability to encode semantics reliably, resulting in 3.85% average gain in top-1 accuracy for zero-shot image classification across 8 datasets. Further, CoN-CLIP outperforms CLIP on challenging compositionality benchmarks such as SugarCREPE by 4.4%, showcasing emergent compositional understanding of objects, relations, and attributes in text. Overall, our work addresses a crucial limitation of VLMs by introducing a dataset and framework that strengthens semantic associations between images and text, demonstrating improved large-scale foundation models with significantly reduced computational cost, promoting efficiency and accessibility.
Exploring Saliency Bias in Manipulation Detection
Feb 15, 2024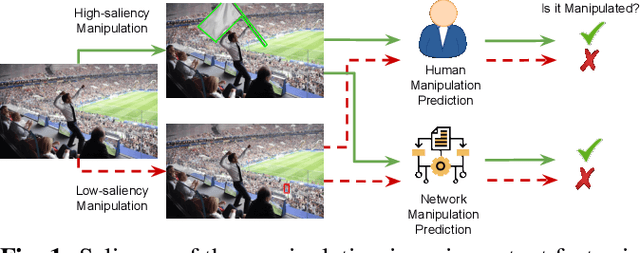
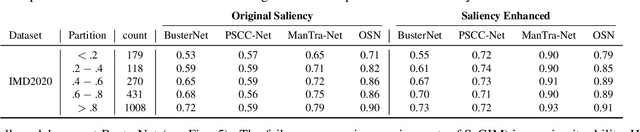

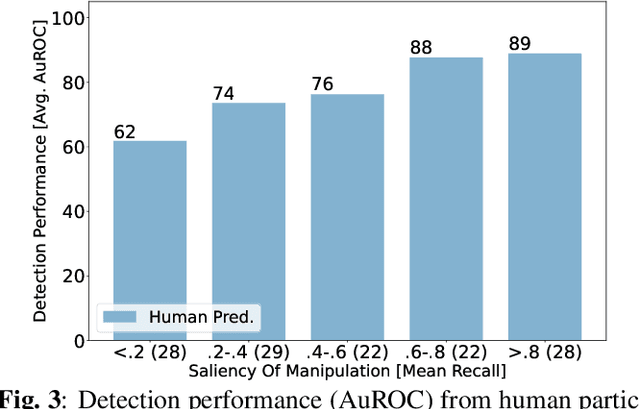
The social media-fuelled explosion of fake news and misinformation supported by tampered images has led to growth in the development of models and datasets for image manipulation detection. However, existing detection methods mostly treat media objects in isolation, without considering the impact of specific manipulations on viewer perception. Forensic datasets are usually analyzed based on the manipulation operations and corresponding pixel-based masks, but not on the semantics of the manipulation, i.e., type of scene, objects, and viewers' attention to scene content. The semantics of the manipulation play an important role in spreading misinformation through manipulated images. In an attempt to encourage further development of semantic-aware forensic approaches to understand visual misinformation, we propose a framework to analyze the trends of visual and semantic saliency in popular image manipulation datasets and their impact on detection.
Subjective Face Transform using Human First Impressions
Sep 27, 2023



Humans tend to form quick subjective first impressions of non-physical attributes when seeing someone's face, such as perceived trustworthiness or attractiveness. To understand what variations in a face lead to different subjective impressions, this work uses generative models to find semantically meaningful edits to a face image that change perceived attributes. Unlike prior work that relied on statistical manipulation in feature space, our end-to-end framework considers trade-offs between preserving identity and changing perceptual attributes. It maps identity-preserving latent space directions to changes in attribute scores, enabling transformation of any input face along an attribute axis according to a target change. We train on real and synthetic faces, evaluate for in-domain and out-of-domain images using predictive models and human ratings, demonstrating the generalizability of our approach. Ultimately, such a framework can be used to understand and explain biases in subjective interpretation of faces that are not dependent on the identity.
A Computer Vision Method for Estimating Velocity from Jumps
Dec 09, 2022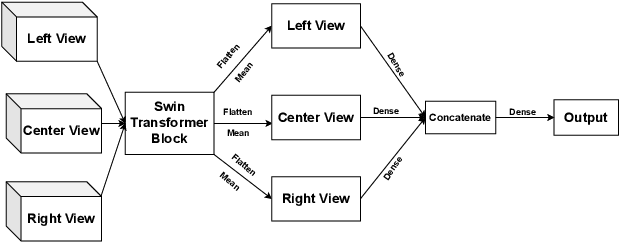
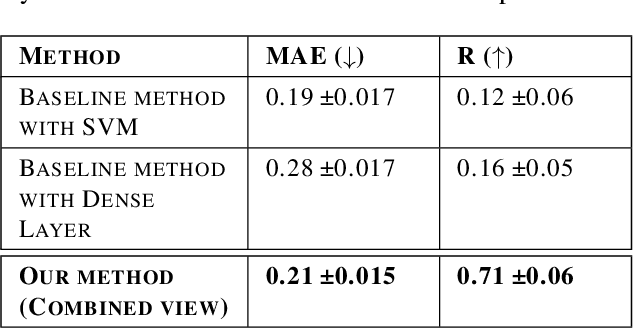
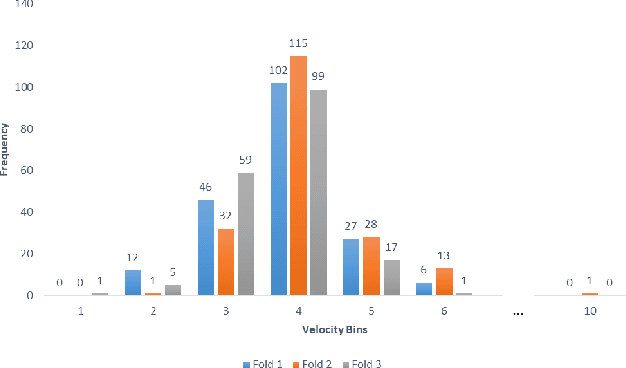
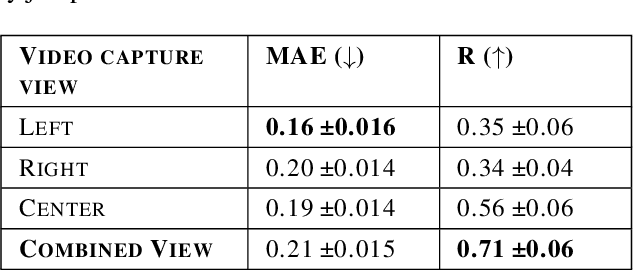
Athletes routinely undergo fitness evaluations to evaluate their training progress. Typically, these evaluations require a trained professional who utilizes specialized equipment like force plates. For the assessment, athletes perform drop and squat jumps, and key variables are measured, e.g. velocity, flight time, and time to stabilization, to name a few. However, amateur athletes may not have access to professionals or equipment that can provide these assessments. Here, we investigate the feasibility of estimating key variables using video recordings. We focus on jump velocity as a starting point because it is highly correlated with other key variables and is important for determining posture and lower-limb capacity. We find that velocity can be estimated with a high degree of precision across a range of athletes, with an average R-value of 0.71 (SD = 0.06).
Learning Transformation-Aware Embeddings for Image Forensics
Jan 13, 2020
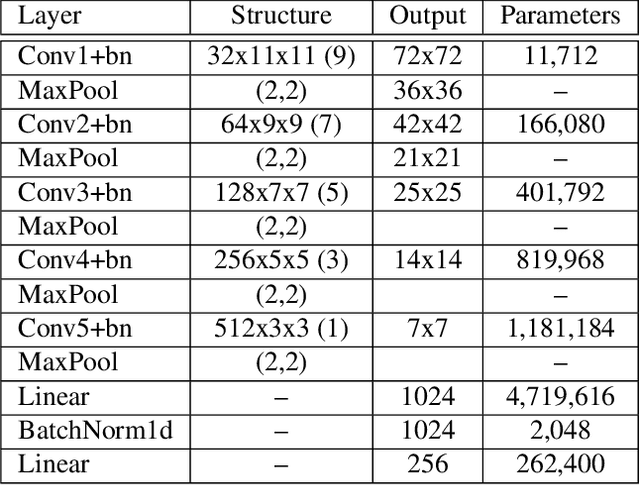
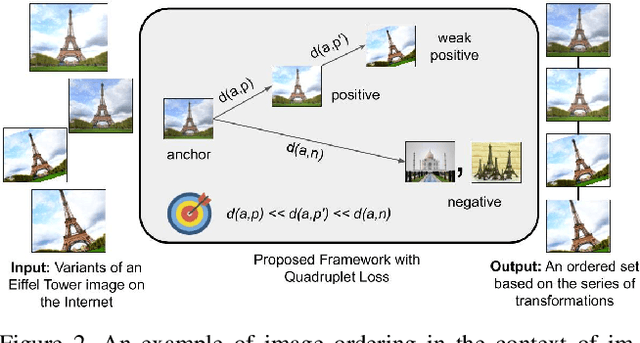
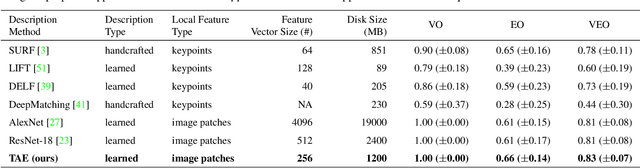
A dramatic rise in the flow of manipulated image content on the Internet has led to an aggressive response from the media forensics research community. New efforts have incorporated increased usage of techniques from computer vision and machine learning to detect and profile the space of image manipulations. This paper addresses Image Provenance Analysis, which aims at discovering relationships among different manipulated image versions that share content. One of the main sub-problems for provenance analysis that has not yet been addressed directly is the edit ordering of images that share full content or are near-duplicates. The existing large networks that generate image descriptors for tasks such as object recognition may not encode the subtle differences between these image covariates. This paper introduces a novel deep learning-based approach to provide a plausible ordering to images that have been generated from a single image through transformations. Our approach learns transformation-aware descriptors using weak supervision via composited transformations and a rank-based quadruplet loss. To establish the efficacy of the proposed approach, comparisons with state-of-the-art handcrafted and deep learning-based descriptors, and image matching approaches are made. Further experimentation validates the proposed approach in the context of image provenance analysis.
Needle in a Haystack: A Framework for Seeking Small Objects in Big Datasets
Apr 10, 2019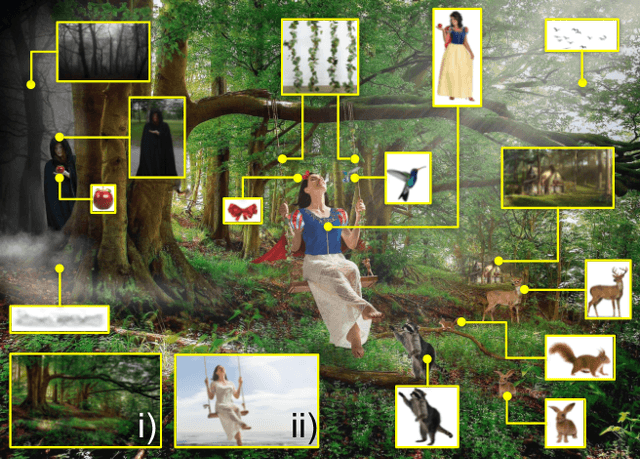
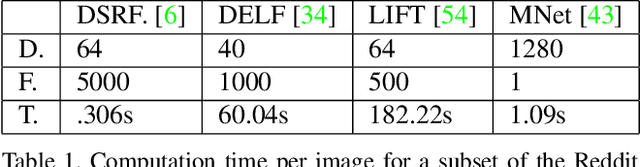
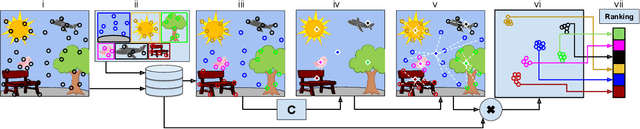
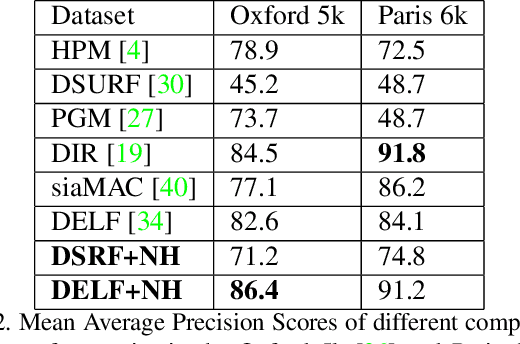
Images from social media can reflect diverse viewpoints, heated arguments, and expressions of creativity --- adding new complexity to search tasks. Researchers working on Content-Based Image Retrieval (CBIR) have traditionally tuned their search algorithms to match filtered results with user search intent. However, we are now bombarded with composite images of unknown origin, authenticity, and even meaning. With such uncertainty, users may not have an initial idea of what the results of a search query should look like. For instance, hidden people, spliced objects, and subtly altered scenes can be difficult for a user to detect initially in a meme image, but may contribute significantly to its composition. We propose a new framework for image retrieval that models object-level regions using image keypoints retrieved from an image index, which are then used to accurately weight small contributing objects within the results, without the need for costly object detection steps. We call this method Needle-Haystack (NH) scoring, and it is optimized for fast matrix operations on CPUs. We show that this method not only performs comparably to state-of-the-art methods in classic CBIR problems, but also outperforms them in fine-grained object- and instance-level retrieval on the Oxford 5K, Paris 6K, Google-Landmarks, and NIST MFC2018 datasets, as well as meme-style imagery from Reddit.
Beyond Pixels: Image Provenance Analysis Leveraging Metadata
Jul 15, 2018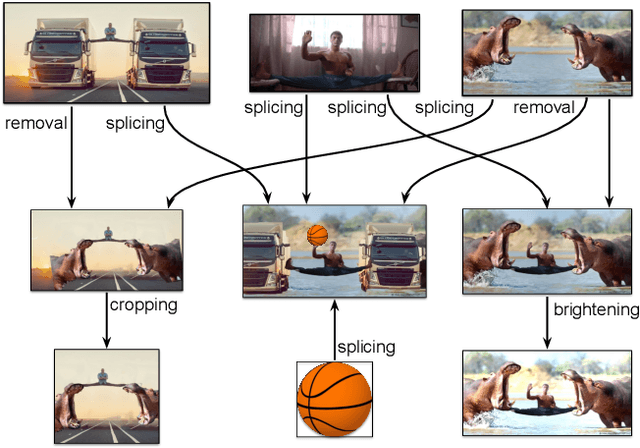
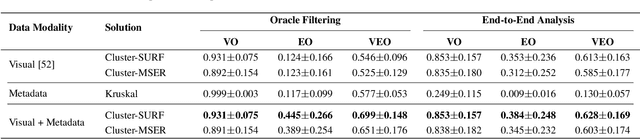
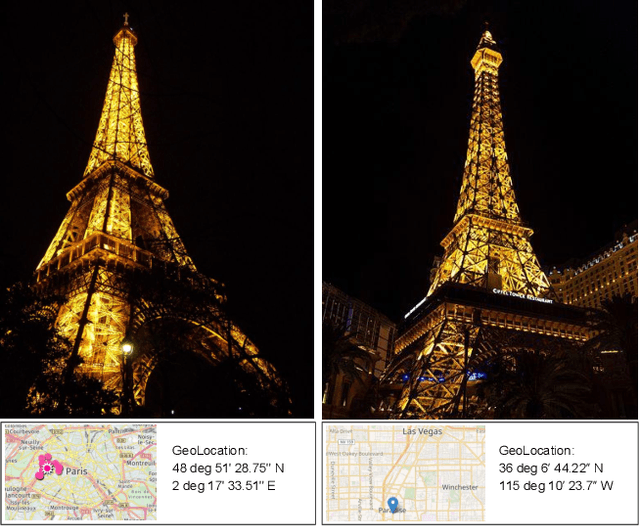
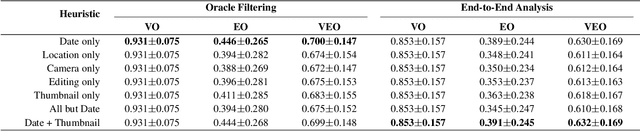
Creative works, whether paintings or memes, follow unique journeys that result in their final form. Understanding these journeys, a process known as "provenance analysis", provides rich insights into the use, motivation, and authenticity underlying any given work. The application of this type of study to the expanse of unregulated content on the Internet is what we consider in this paper. Provenance analysis provides a snapshot of the chronology and validity of content as it is uploaded, re-uploaded, and modified over time. Although still in its infancy, automated provenance analysis for online multimedia is already being applied to different types of content. Most current works seek to build provenance graphs based on the shared content between images or videos. This can be a computationally expensive task, especially when considering the vast influx of content that the Internet sees every day. Utilizing non-content-based information, such as timestamps, geotags, and camera IDs can help provide important insights into the path a particular image or video has traveled during its time on the Internet without large computational overhead. This paper tests the scope and applicability of metadata-based inferences for provenance graph construction in two different scenarios: digital image forensics and cultural analytics.
Getting the subtext without the text: Scalable multimodal sentiment classification from visual and acoustic modalities
Jul 03, 2018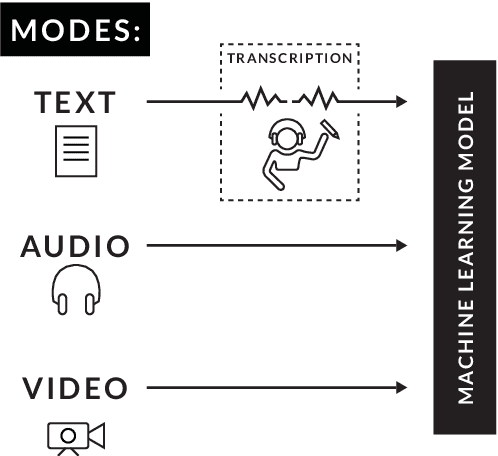
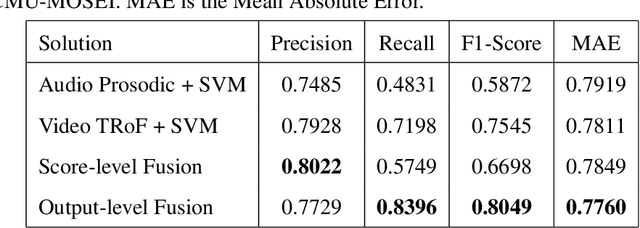
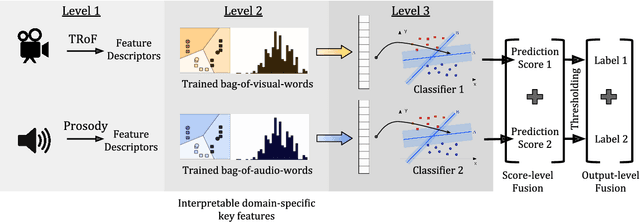
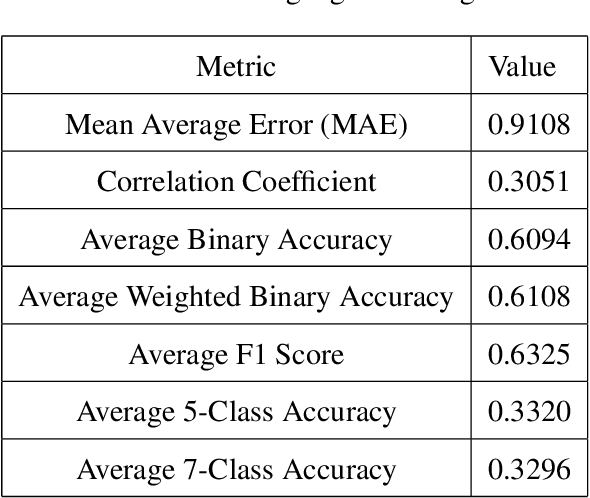
In the last decade, video blogs (vlogs) have become an extremely popular method through which people express sentiment. The ubiquitousness of these videos has increased the importance of multimodal fusion models, which incorporate video and audio features with traditional text features for automatic sentiment detection. Multimodal fusion offers a unique opportunity to build models that learn from the full depth of expression available to human viewers. In the detection of sentiment in these videos, acoustic and video features provide clarity to otherwise ambiguous transcripts. In this paper, we present a multimodal fusion model that exclusively uses high-level video and audio features to analyze spoken sentences for sentiment. We discard traditional transcription features in order to minimize human intervention and to maximize the deployability of our model on at-scale real-world data. We select high-level features for our model that have been successful in nonaffect domains in order to test their generalizability in the sentiment detection domain. We train and test our model on the newly released CMU Multimodal Opinion Sentiment and Emotion Intensity (CMUMOSEI) dataset, obtaining an F1 score of 0.8049 on the validation set and an F1 score of 0.6325 on the held-out challenge test set.