 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion for De-Occlusion: Accessory-Aware Diffusion Inpainting for Robust Ear Biometric Recognition
Jan 27, 2026Ear occlusions (arising from the presence of ear accessories such as earrings and earphones) can negatively impact performance in ear-based biometric recognition systems, especially in unconstrained imaging circumstances. In this study, we assess the effectiveness of a diffusion-based ear inpainting technique as a pre-processing aid to mitigate the issues of ear accessory occlusions in transformer-based ear recognition systems. Given an input ear image and an automatically derived accessory mask, the inpainting model reconstructs clean and anatomically plausible ear regions by synthesizing missing pixels while preserving local geometric coherence along key ear structures, including the helix, antihelix, concha, and lobule. We evaluate the effectiveness of this pre-processing aid in transformer-based recognition systems for several vision transformer models and different patch sizes for a range of benchmark datasets. Experiments show that diffusion-based inpainting can be a useful pre-processing aid to alleviate ear accessory occlusions to improve overall recognition performance.
PaW-ViT: A Patch-based Warping Vision Transformer for Robust Ear Verification
Jan 27, 2026The rectangular tokens common to vision transformer methods for visual recognition can strongly affect performance of these methods due to incorporation of information outside the objects to be recognized. This paper introduces PaW-ViT, Patch-based Warping Vision Transformer, a preprocessing approach rooted in anatomical knowledge that normalizes ear images to enhance the efficacy of ViT. By accurately aligning token boundaries to detected ear feature boundaries, PaW-ViT obtains greater robustness to shape, size, and pose variation. By aligning feature boundaries to natural ear curvature, it produces more consistent token representations for various morphologies. Experiments confirm the effectiveness of PaW-ViT on various ViT models (ViT-T, ViT-S, ViT-B, ViT-L) and yield reasonable alignment robustness to variation in shape, size, and pose. Our work aims to solve the disconnect between ear biometric morphological variation and transformer architecture positional sensitivity, presenting a possible avenue for authentication schemes.
Are you In or Out (of gallery)? Wisdom from the Same-Identity Crowd
Aug 08, 2025A central problem in one-to-many facial identification is that the person in the probe image may or may not have enrolled image(s) in the gallery; that is, may be In-gallery or Out-of-gallery. Past approaches to detect when a rank-one result is Out-of-gallery have mostly focused on finding a suitable threshold on the similarity score. We take a new approach, using the additional enrolled images of the identity with the rank-one result to predict if the rank-one result is In-gallery / Out-of-gallery. Given a gallery of identities and images, we generate In-gallery and Out-of-gallery training data by extracting the ranks of additional enrolled images corresponding to the rank-one identity. We then train a classifier to utilize this feature vector to predict whether a rank-one result is In-gallery or Out-of-gallery. Using two different datasets and four different matchers, we present experimental results showing that our approach is viable for mugshot quality probe images, and also, importantly, for probes degraded by blur, reduced resolution, atmospheric turbulence and sunglasses. We also analyze results across demographic groups, and show that In-gallery / Out-of-gallery classification accuracy is similar across demographics. Our approach has the potential to provide an objective estimate of whether a one-to-many facial identification is Out-of-gallery, and thereby to reduce false positive identifications, wrongful arrests, and wasted investigative time. Interestingly, comparing the results of older deep CNN-based face matchers with newer ones suggests that the effectiveness of our Out-of-gallery detection approach emerges only with matchers trained using advanced margin-based loss functions.
How Does Bilateral Ear Symmetry Affect Deep Ear Features?
Aug 06, 2025Ear recognition has gained attention as a reliable biometric technique due to the distinctive characteristics of human ears. With the increasing availability of large-scale datasets, convolutional neural networks (CNNs) have been widely adopted to learn features directly from raw ear images, outperforming traditional hand-crafted methods. However, the effect of bilateral ear symmetry on the features learned by CNNs has received little attention in recent studies. In this paper, we investigate how bilateral ear symmetry influences the effectiveness of CNN-based ear recognition. To this end, we first develop an ear side classifier to automatically categorize ear images as either left or right. We then explore the impact of incorporating this side information during both training and test. Cross-dataset evaluations are conducted on five datasets. Our results suggest that treating left and right ears separately during training and testing can lead to notable performance improvements. Furthermore, our ablation studies on alignment strategies, input sizes, and various hyperparameter settings provide practical insights into training CNN-based ear recognition systems on large-scale datasets to achieve higher verification rates.
Vec2Face+ for Face Dataset Generation
Jul 23, 2025When synthesizing identities as face recognition training data, it is generally believed that large inter-class separability and intra-class attribute variation are essential for synthesizing a quality dataset. % This belief is generally correct, and this is what we aim for. However, when increasing intra-class variation, existing methods overlook the necessity of maintaining intra-class identity consistency. % To address this and generate high-quality face training data, we propose Vec2Face+, a generative model that creates images directly from image features and allows for continuous and easy control of face identities and attributes. Using Vec2Face+, we obtain datasets with proper inter-class separability and intra-class variation and identity consistency using three strategies: 1) we sample vectors sufficiently different from others to generate well-separated identities; 2) we propose an AttrOP algorithm for increasing general attribute variations; 3) we propose LoRA-based pose control for generating images with profile head poses, which is more efficient and identity-preserving than AttrOP. % Our system generates VFace10K, a synthetic face dataset with 10K identities, which allows an FR model to achieve state-of-the-art accuracy on seven real-world test sets. Scaling the size to 4M and 12M images, the corresponding VFace100K and VFace300K datasets yield higher accuracy than the real-world training dataset, CASIA-WebFace, on five real-world test sets. This is the first time a synthetic dataset beats the CASIA-WebFace in average accuracy. In addition, we find that only 1 out of 11 synthetic datasets outperforms random guessing (\emph{i.e., 50\%}) in twin verification and that models trained with synthetic identities are more biased than those trained with real identities. Both are important aspects for future investigation.
Improved Ear Verification with Vision Transformers and Overlapping Patches
Mar 30, 2025Ear recognition has emerged as a promising biometric modality due to the relative stability in appearance during adulthood. Although Vision Transformers (ViTs) have been widely used in image recognition tasks, their efficiency in ear recognition has been hampered by a lack of attention to overlapping patches, which is crucial for capturing intricate ear features. In this study, we evaluate ViT-Tiny (ViT-T), ViT-Small (ViT-S), ViT-Base (ViT-B) and ViT-Large (ViT-L) configurations on a diverse set of datasets (OPIB, AWE, WPUT, and EarVN1.0), using an overlapping patch selection strategy. Results demonstrate the critical importance of overlapping patches, yielding superior performance in 44 of 48 experiments in a structured study. Moreover, upon comparing the results of the overlapping patches with the non-overlapping configurations, the increase is significant, reaching up to 10% for the EarVN1.0 dataset. In terms of model performance, the ViT-T model consistently outperformed the ViT-S, ViT-B, and ViT-L models on the AWE, WPUT, and EarVN1.0 datasets. The highest scores were achieved in a configuration with a patch size of 28x28 and a stride of 14 pixels. This patch-stride configuration represents 25% of the normalized image area (112x112 pixels) for the patch size and 12.5% of the row or column size for the stride. This study confirms that transformer architectures with overlapping patch selection can serve as an efficient and high-performing option for ear-based biometric recognition tasks in verification scenarios.
Peepers & Pixels: Human Recognition Accuracy on Low Resolution Faces
Mar 25, 2025

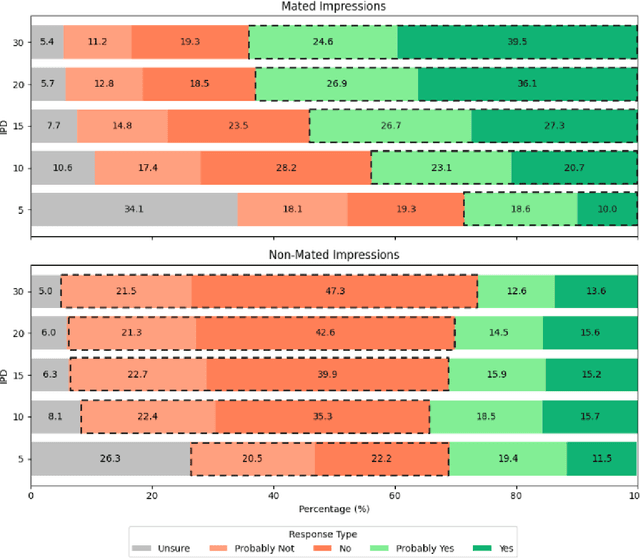
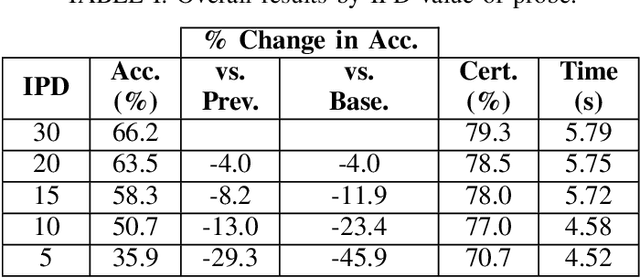
Automated one-to-many (1:N) face recognition is a powerful investigative tool commonly used by law enforcement agencies. In this context, potential matches resulting from automated 1:N recognition are reviewed by human examiners prior to possible use as investigative leads. While automated 1:N recognition can achieve near-perfect accuracy under ideal imaging conditions, operational scenarios may necessitate the use of surveillance imagery, which is often degraded in various quality dimensions. One important quality dimension is image resolution, typically quantified by the number of pixels on the face. The common metric for this is inter-pupillary distance (IPD), which measures the number of pixels between the pupils. Low IPD is known to degrade the accuracy of automated face recognition. However, the threshold IPD for reliability in human face recognition remains undefined. This study aims to explore the boundaries of human recognition accuracy by systematically testing accuracy across a range of IPD values. We find that at low IPDs (10px, 5px), human accuracy is at or below chance levels (50.7%, 35.9%), even as confidence in decision-making remains relatively high (77%, 70.7%). Our findings indicate that, for low IPD images, human recognition ability could be a limiting factor to overall system accuracy.
A Siamese Network to Detect If Two Iris Images Are Monozygotic
Mar 12, 2025In Daugman-style iris recognition, the textures of the left and right irises of the same person are traditionally considered as being as different as the irises of two unrelated persons. However, previous research indicates that humans can detect that two iris images are from different eyes of the same person, or eyes of monozygotic twins, with an accuracy of about 80%. In this work, we employ a Siamese network architecture and contrastive learning to categorize a pair of iris images as coming from monozygotic or non-monozygotic irises. This could potentially be applied, for example, as a fast, noninvasive test to determine if twins are monozygotic or non-monozygotic. We construct a dataset comprising both synthetic monozygotic pairs (images of different irises of the same individual) and natural monozygotic pairs (images of different images from persons who are identical twins), in addition to non-monozygotic pairs from unrelated individuals, ensuring a comprehensive evaluation of the model's capabilities. To gain deeper insights into the learned representations, we train and analyze three variants of the model using (1) the original input images, (2) iris-only images, and (3) non-iris-only images. This comparison reveals the critical importance of iris-specific textural details and contextual ocular cues in identifying monozygotic iris patterns. The results demonstrate that models leveraging full eye-region information outperform those trained solely on iris-only data, emphasizing the nuanced interplay between iris and ocular characteristics. Our approach achieves accuracy levels using the full iris image that exceed those previously reported for human classification of monozygotic iris pairs. This study presents the first classifier designed to determine whether a pair of iris images originates from monozygotic individuals.
On the "Illusion" of Gender Bias in Face Recognition: Explaining the Fairness Issue Through Non-demographic Attributes
Jan 21, 2025Face recognition systems (FRS) exhibit significant accuracy differences based on the user's gender. Since such a gender gap reduces the trustworthiness of FRS, more recent efforts have tried to find the causes. However, these studies make use of manually selected, correlated, and small-sized sets of facial features to support their claims. In this work, we analyse gender bias in face recognition by successfully extending the search domain to decorrelated combinations of 40 non-demographic facial characteristics. First, we propose a toolchain to effectively decorrelate and aggregate facial attributes to enable a less-biased gender analysis on large-scale data. Second, we introduce two new fairness metrics to measure fairness with and without context. Based on these grounds, we thirdly present a novel unsupervised algorithm able to reliably identify attribute combinations that lead to vanishing bias when used as filter predicates for balanced testing datasets. The experiments show that the gender gap vanishes when images of male and female subjects share specific attributes, clearly indicating that the issue is not a question of biology but of the social definition of appearance. These findings could reshape our understanding of fairness in face biometrics and provide insights into FRS, helping to address gender bias issues.
Lights, Camera, Matching: The Role of Image Illumination in Fair Face Recognition
Jan 15, 2025



Facial brightness is a key image quality factor impacting face recognition accuracy differentials across demographic groups. In this work, we aim to decrease the accuracy gap between the similarity score distributions for Caucasian and African American female mated image pairs, as measured by d' between distributions. To balance brightness across demographic groups, we conduct three experiments, interpreting brightness in the face skin region either as median pixel value or as the distribution of pixel values. Balancing based on median brightness alone yields up to a 46.8% decrease in d', while balancing based on brightness distribution yields up to a 57.6% decrease. In all three cases, the similarity scores of the individual distributions improve, with mean scores maximally improving 5.9% for Caucasian females and 3.7% for African American females.