 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Better Deep Learning Models Using Human Saliency
Paper and Code
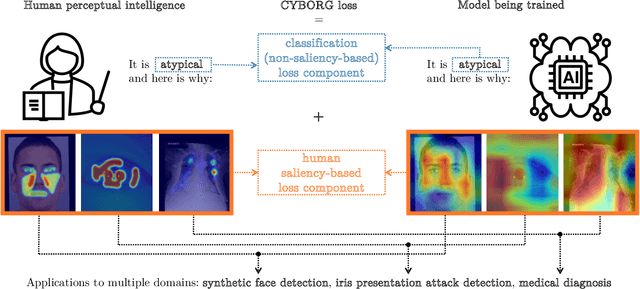
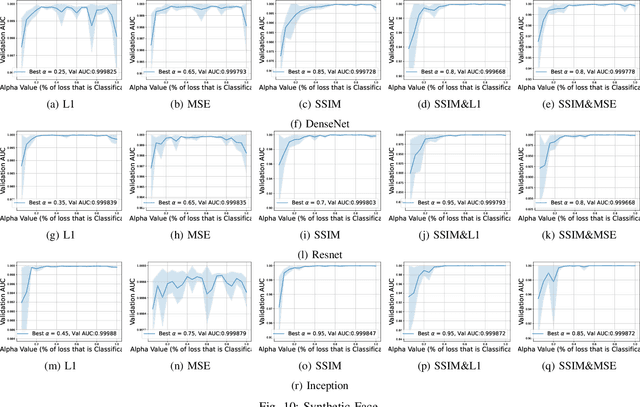
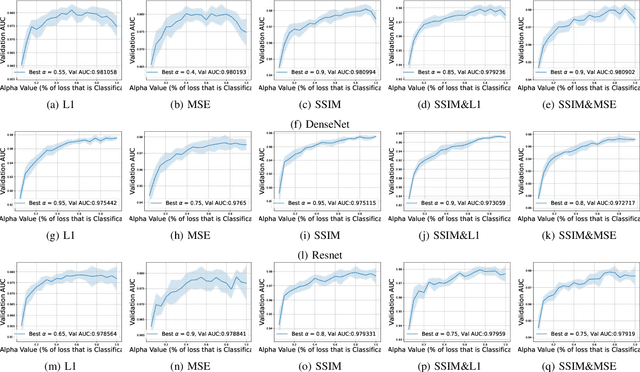
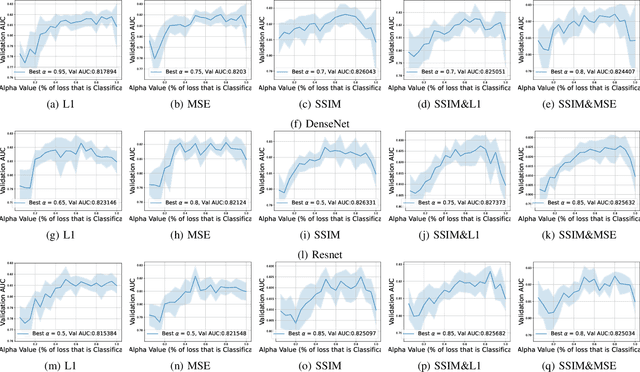
This work explores how human judgement about salient regions of an image can be introduced into deep convolutional neural network (DCNN) training. Traditionally, training of DCNNs is purely data-driven. This often results in learning features of the data that are only coincidentally correlated with class labels. Human saliency can guide network training using our proposed new component of the loss function that ConveYs Brain Oversight to Raise Generalization (CYBORG) and penalizes the model for using non-salient regions. This mechanism produces DCNNs achieving higher accuracy and generalization compared to using the same training data without human salience. Experimental results demonstrate that CYBORG applies across multiple network architectures and problem domains (detection of synthetic faces, iris presentation attacks and anomalies in chest X-rays), while requiring significantly less data than training without human saliency guidance. Visualizations show that CYBORG-trained models' saliency is more consistent across independent training runs than traditionally-trained models, and also in better agreement with humans. To lower the cost of collecting human annotations, we also explore using deep learning to provide automated annotations. CYBORG training of CNNs addresses important issues such as reducing the appetite for large training sets, increasing interpretability, and reducing fragility by generalizing better to new types of data.