 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Better Deep Learning Models Using Human Saliency
Oct 21, 2024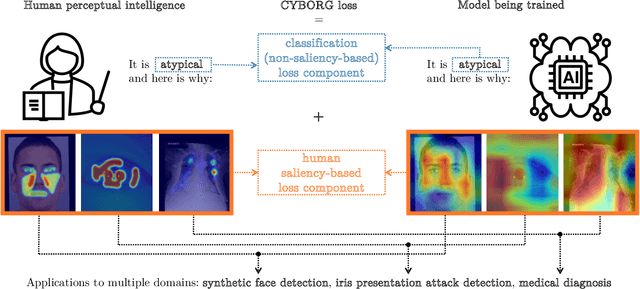
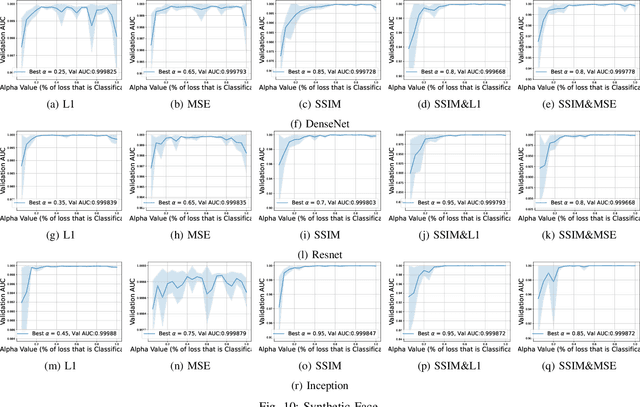
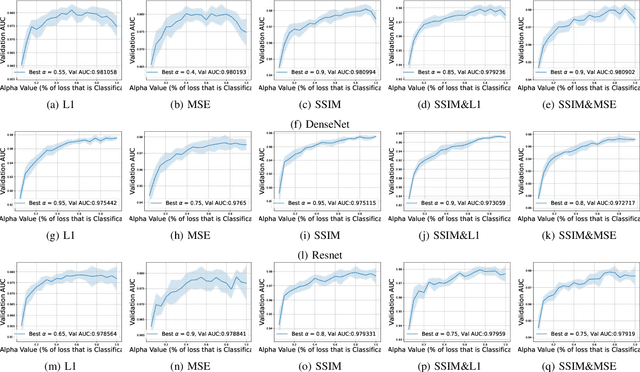
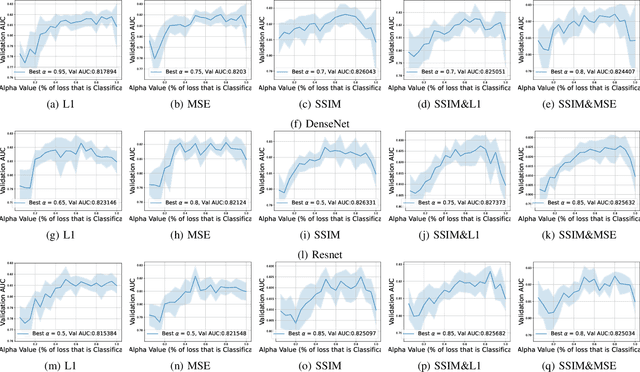
This work explores how human judgement about salient regions of an image can be introduced into deep convolutional neural network (DCNN) training. Traditionally, training of DCNNs is purely data-driven. This often results in learning features of the data that are only coincidentally correlated with class labels. Human saliency can guide network training using our proposed new component of the loss function that ConveYs Brain Oversight to Raise Generalization (CYBORG) and penalizes the model for using non-salient regions. This mechanism produces DCNNs achieving higher accuracy and generalization compared to using the same training data without human salience. Experimental results demonstrate that CYBORG applies across multiple network architectures and problem domains (detection of synthetic faces, iris presentation attacks and anomalies in chest X-rays), while requiring significantly less data than training without human saliency guidance. Visualizations show that CYBORG-trained models' saliency is more consistent across independent training runs than traditionally-trained models, and also in better agreement with humans. To lower the cost of collecting human annotations, we also explore using deep learning to provide automated annotations. CYBORG training of CNNs addresses important issues such as reducing the appetite for large training sets, increasing interpretability, and reducing fragility by generalizing better to new types of data.
Privacy-Safe Iris Presentation Attack Detection
Aug 05, 2024



This paper proposes a framework for a privacy-safe iris presentation attack detection (PAD) method, designed solely with synthetically-generated, identity-leakage-free iris images. Once trained, the method is evaluated in a classical way using state-of-the-art iris PAD benchmarks. We designed two generative models for the synthesis of ISO/IEC 19794-6-compliant iris images. The first model synthesizes bona fide-looking samples. To avoid ``identity leakage,'' the generated samples that accidentally matched those used in the model's training were excluded. The second model synthesizes images of irises with textured contact lenses and is conditioned by a given contact lens brand to have better control over textured contact lens appearance when forming the training set. Our experiments demonstrate that models trained solely on synthetic data achieve a lower but still reasonable performance when compared to solutions trained with iris images collected from human subjects. This is the first-of-its-kind attempt to use solely synthetic data to train a fully-functional iris PAD solution, and despite the performance gap between regular and the proposed methods, this study demonstrates that with the increasing fidelity of generative models, creating such privacy-safe iris PAD methods may be possible. The source codes and generative models trained for this work are offered along with the paper.
EyePreserve: Identity-Preserving Iris Synthesis
Dec 30, 2023



Synthesis of same-identity biometric iris images, both for existing and non-existing identities while preserving the identity across a wide range of pupil sizes, is complex due to intricate iris muscle constriction mechanism, requiring a precise model of iris non-linear texture deformations to be embedded into the synthesis pipeline. This paper presents the first method of fully data-driven, identity-preserving, pupil size-varying s ynthesis of iris images. This approach is capable of synthesizing images of irises with different pupil sizes representing non-existing identities as well as non-linearly deforming the texture of iris images of existing subjects given the segmentation mask of the target iris image. Iris recognition experiments suggest that the proposed deformation model not only preserves the identity when changing the pupil size but offers better similarity between same-identity iris samples with significant differences in pupil size, compared to state-of-the-art linear and non-linear (bio-mechanical-based) iris deformation models. Two immediate applications of the proposed approach are: (a) synthesis of, or enhancement of the existing biometric datasets for iris recognition, mimicking those acquired with iris sensors, and (b) helping forensic human experts in examining iris image pairs with significant differences in pupil dilation. Source codes and weights of the models are made available with the paper.
Iris Liveness Detection Competition (LivDet-Iris) -- The 2023 Edition
Oct 06, 2023



This paper describes the results of the 2023 edition of the ''LivDet'' series of iris presentation attack detection (PAD) competitions. New elements in this fifth competition include (1) GAN-generated iris images as a category of presentation attack instruments (PAI), and (2) an evaluation of human accuracy at detecting PAI as a reference benchmark. Clarkson University and the University of Notre Dame contributed image datasets for the competition, composed of samples representing seven different PAI categories, as well as baseline PAD algorithms. Fraunhofer IGD, Beijing University of Civil Engineering and Architecture, and Hochschule Darmstadt contributed results for a total of eight PAD algorithms to the competition. Accuracy results are analyzed by different PAI types, and compared to human accuracy. Overall, the Fraunhofer IGD algorithm, using an attention-based pixel-wise binary supervision network, showed the best-weighted accuracy results (average classification error rate of 37.31%), while the Beijing University of Civil Engineering and Architecture's algorithm won when equal weights for each PAI were given (average classification rate of 22.15%). These results suggest that iris PAD is still a challenging problem.
Explain To Me: Salience-Based Explainability for Synthetic Face Detection Models
Mar 27, 2023



The performance of convolutional neural networks has continued to improve over the last decade. At the same time, as model complexity grows, it becomes increasingly more difficult to explain model decisions. Such explanations may be of critical importance for reliable operation of human-machine pairing setups, or for model selection when the "best" model among many equally-accurate models must be established. Saliency maps represent one popular way of explaining model decisions by highlighting image regions models deem important when making a prediction. However, examining salience maps at scale is not practical. In this paper, we propose five novel methods of leveraging model salience to explain a model behavior at scale. These methods ask: (a) what is the average entropy for a model's salience maps, (b) how does model salience change when fed out-of-set samples, (c) how closely does model salience follow geometrical transformations, (d) what is the stability of model salience across independent training runs, and (e) how does model salience react to salience-guided image degradations. To assess the proposed measures on a concrete and topical problem, we conducted a series of experiments for the task of synthetic face detection with two types of models: those trained traditionally with cross-entropy loss, and those guided by human salience when training to increase model generalizability. These two types of models are characterized by different, interpretable properties of their salience maps, which allows for the evaluation of the correctness of the proposed measures. We offer source codes for each measure along with this paper.
Haven't I Seen You Before? Assessing Identity Leakage in Synthetic Irises
Nov 03, 2022



Generative Adversarial Networks (GANs) have proven to be a preferred method of synthesizing fake images of objects, such as faces, animals, and automobiles. It is not surprising these models can also generate ISO-compliant, yet synthetic iris images, which can be used to augment training data for iris matchers and liveness detectors. In this work, we trained one of the most recent GAN models (StyleGAN3) to generate fake iris images with two primary goals: (i) to understand the GAN's ability to produce "never-before-seen" irises, and (ii) to investigate the phenomenon of identity leakage as a function of the GAN's training time. Previous work has shown that personal biometric data can inadvertently flow from training data into synthetic samples, raising a privacy concern for subjects who accidentally appear in the training dataset. This paper presents analysis for three different iris matchers at varying points in the GAN training process to diagnose where and when authentic training samples are in jeopardy of leaking through the generative process. Our results show that while most synthetic samples do not show signs of identity leakage, a handful of generated samples match authentic (training) samples nearly perfectly, with consensus across all matchers. In order to prioritize privacy, security, and trust in the machine learning model development process, the research community must strike a delicate balance between the benefits of using synthetic data and the corresponding threats against privacy from potential identity leakage.
The Value of AI Guidance in Human Examination of Synthetically-Generated Faces
Aug 22, 2022



Face image synthesis has progressed beyond the point at which humans can effectively distinguish authentic faces from synthetically generated ones. Recently developed synthetic face image detectors boast "better-than-human" discriminative ability, especially those guided by human perceptual intelligence during the model's training process. In this paper, we investigate whether these human-guided synthetic face detectors can assist non-expert human operators in the task of synthetic image detection when compared to models trained without human-guidance. We conducted a large-scale experiment with more than 1,560 subjects classifying whether an image shows an authentic or synthetically-generated face, and annotate regions that supported their decisions. In total, 56,015 annotations across 3,780 unique face images were collected. All subjects first examined samples without any AI support, followed by samples given (a) the AI's decision ("synthetic" or "authentic"), (b) class activation maps illustrating where the model deems salient for its decision, or (c) both the AI's decision and AI's saliency map. Synthetic faces were generated with six modern Generative Adversarial Networks. Interesting observations from this experiment include: (1) models trained with human-guidance offer better support to human examination of face images when compared to models trained traditionally using cross-entropy loss, (2) binary decisions presented to humans offers better support than saliency maps, (3) understanding the AI's accuracy helps humans to increase trust in a given model and thus increase their overall accuracy. This work demonstrates that although humans supported by machines achieve better-than-random accuracy of synthetic face detection, the ways of supplying humans with AI support and of building trust are key factors determining high effectiveness of the human-AI tandem.
DeformIrisNet: An Identity-Preserving Model of Iris Texture Deformation
Jul 18, 2022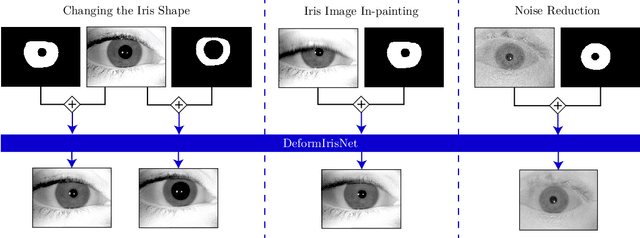
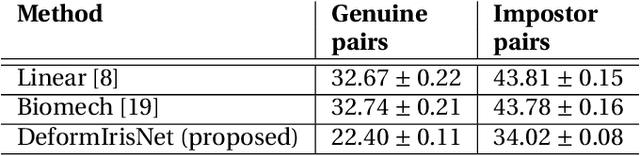
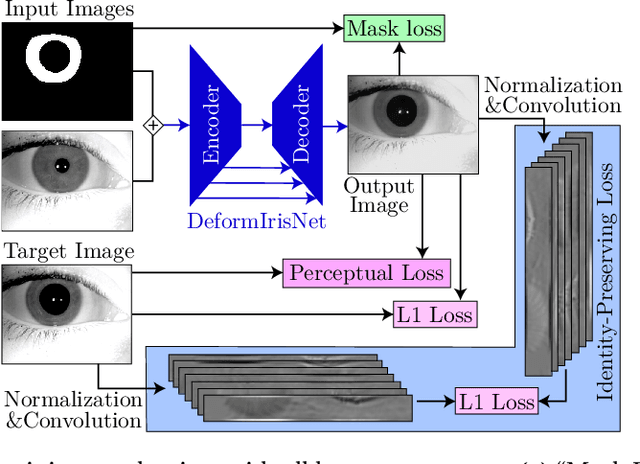
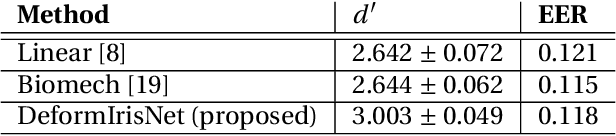
Nonlinear iris texture deformations due to pupil size variations are one of the main factors responsible for within-class variance of genuine comparison scores in iris recognition. In dominant approaches to iris recognition, the size of a ring-shaped iris region is linearly scaled to a canonical rectangle, used further in encoding and matching. However, the biological complexity of iris sphincter and dilator muscles causes the movements of iris features to be nonlinear in a function of pupil size, and not solely organized along radial paths. Alternatively to the existing theoretical models based on biomechanics of iris musculature, in this paper we propose a novel deep autoencoder-based model that can effectively learn complex movements of iris texture features directly from the data. The proposed model takes two inputs, (a) an ISO-compliant near-infrared iris image with initial pupil size, and (b) the binary mask defining the target shape of the iris. The model makes all the necessary nonlinear deformations to the iris texture to match the shape of iris in image (a) with the shape provided by the target mask (b). The identity-preservation component of the loss function helps the model in finding deformations that preserve identity and not only visual realism of generated samples. We also demonstrate two immediate applications of this model: better compensation for iris texture deformations in iris recognition algorithms, compared to linear models, and creation of generative algorithm that can aid human forensic examiners, who may need to compare iris images with large difference in pupil dilation. We offer the source codes and model weights available along with this paper.
CYBORG: Blending Human Saliency Into the Loss Improves Deep Learning
Dec 01, 2021
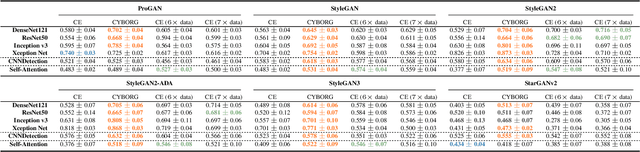


Can deep learning models achieve greater generalization if their training is guided by reference to human perceptual abilities? And how can we implement this in a practical manner? This paper proposes a first-ever training strategy to ConveY Brain Oversight to Raise Generalization (CYBORG). This new training approach incorporates human-annotated saliency maps into a CYBORG loss function that guides the model towards learning features from image regions that humans find salient when solving a given visual task. The Class Activation Mapping (CAM) mechanism is used to probe the model's current saliency in each training batch, juxtapose model saliency with human saliency, and penalize the model for large differences. Results on the task of synthetic face detection show that the CYBORG loss leads to significant improvement in performance on unseen samples consisting of face images generated from six Generative Adversarial Networks (GANs) across multiple classification network architectures. We also show that scaling to even seven times as much training data with standard loss cannot beat the accuracy of CYBORG loss. As a side effect, we observed that the addition of explicit region annotation to the task of synthetic face detection increased human classification performance. This work opens a new area of research on how to incorporate human visual saliency into loss functions. All data, code and pre-trained models used in this work are offered with this paper.
This Face Does Not Exist But It Might Be Yours! Identity Leakage in Generative Models
Dec 10, 2020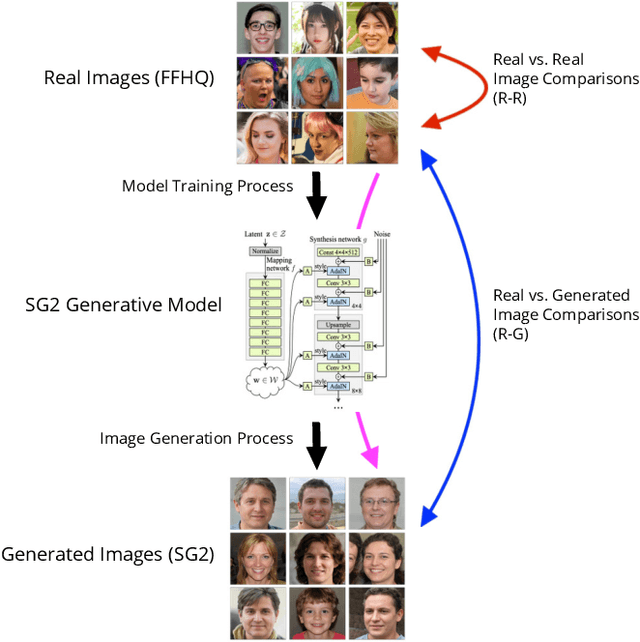


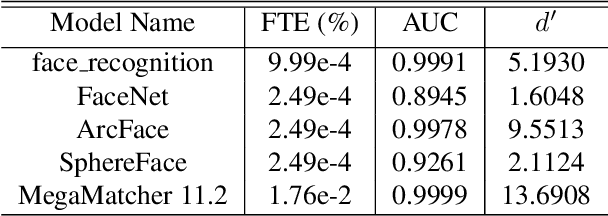
Generative adversarial networks (GANs) are able to generate high resolution photo-realistic images of objects that "do not exist." These synthetic images are rather difficult to detect as fake. However, the manner in which these generative models are trained hints at a potential for information leakage from the supplied training data, especially in the context of synthetic faces. This paper presents experiments suggesting that identity information in face images can flow from the training corpus into synthetic samples without any adversarial actions when building or using the existing model. This raises privacy-related questions, but also stimulates discussions of (a) the face manifold's characteristics in the feature space and (b) how to create generative models that do not inadvertently reveal identity information of real subjects whose images were used for training. We used five different face matchers (face_recognition, FaceNet, ArcFace, SphereFace and Neurotechnology MegaMatcher) and the StyleGAN2 synthesis model, and show that this identity leakage does exist for some, but not all methods. So, can we say that these synthetically generated faces truly do not exist? Databases of real and synthetically generated faces are made available with this paper to allow full replicability of the results discussed in this work.