 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISER: Visually-Informed System for Enhanced Robustness in Open-Set Iris Presentation Attack Detection
Mar 18, 2026Human perceptual priors have shown promise in saliency-guided deep learning training, particularly in the domain of iris presentation attack detection (PAD). Common saliency approaches include hand annotations obtained via mouse clicks and eye gaze heatmaps derived from eye tracking data. However, the most effective form of human saliency for open-set iris PAD remains underexplored. In this paper, we conduct a series of experiments comparing hand annotations, eye tracking heatmaps, segmentation masks, and DINOv2 embeddings to a state-of-the-art deep learning-based baseline on the task of open-set iris PAD. Results for open-set PAD in a leave-one-attack-type out paradigm indicate that denoised eye tracking heatmaps show the best generalization improvement over cross entropy in terms of Area Under the ROC curve (AUROC) and Attack Presentation Classification Error Rate (APCER) at Bona Fide Presentation Classification Error Rate (BPCER) of 1%. Along with this paper, we offer trained models, code, and saliency maps for reproducibility and to facilitate follow-up research efforts.
Generalist Multimodal LLMs Gain Biometric Expertise via Human Salience
Mar 17, 2026Iris presentation attack detection (PAD) is critical for secure biometric deployments, yet developing specialized models faces significant practical barriers: collecting data representing future unknown attacks is impossible, and collecting diverse-enough data, yet still limited in terms of its predictive power, is expensive. Additionally, sharing biometric data raises privacy concerns. Due to rapid emergence of new attack vectors demanding adaptable solutions, we thus investigate in this paper whether general-purpose multimodal large language models (MLLMs) can perform iris PAD when augmented with human expert knowledge, operating under strict privacy constraints that prohibit sending biometric data to public cloud MLLM services. Through analysis of vision encoder embeddings applied to our dataset, we demonstrate that pre-trained vision transformers in MLLMs inherently cluster many iris attack types despite never being explicitly trained for this task. However, where clustering shows overlap between attack classes, we find that structured prompts incorporating human salience (verbal descriptions from subjects identifying attack indicators) enable these models to resolve ambiguities. Testing on an IRB-restricted dataset of 224 iris images spanning seven attack types, using only university-approved services (Gemini 2.5 Pro) or locally-hosted models (e.g., Llama 3.2-Vision), we show that Gemini with expert-informed prompts outperforms both a specialized convolutional neural networks (CNN)-based baseline and human examiners, while the locally-deployable Llama achieves near-human performance. Our results establish that MLLMs deployable within institutional privacy constraints offer a viable path for iris PAD.
Divisive Decisions: Improving Salience-Based Training for Generalization in Binary Classification Tasks
Jul 22, 2025Existing saliency-guided training approaches improve model generalization by incorporating a loss term that compares the model's class activation map (CAM) for a sample's true-class ({\it i.e.}, correct-label class) against a human reference saliency map. However, prior work has ignored the false-class CAM(s), that is the model's saliency obtained for incorrect-label class. We hypothesize that in binary tasks the true and false CAMs should diverge on the important classification features identified by humans (and reflected in human saliency maps). We use this hypothesis to motivate three new saliency-guided training methods incorporating both true- and false-class model's CAM into the training strategy and a novel post-hoc tool for identifying important features. We evaluate all introduced methods on several diverse binary close-set and open-set classification tasks, including synthetic face detection, biometric presentation attack detection, and classification of anomalies in chest X-ray scans, and find that the proposed methods improve generalization capabilities of deep learning models over traditional (true-class CAM only) saliency-guided training approaches. We offer source codes and model weights\footnote{GitHub repository link removed to preserve anonymity} to support reproducible research.
DiffGradCAM: A Universal Class Activation Map Resistant to Adversarial Training
Jun 10, 2025Class Activation Mapping (CAM) and its gradient-based variants (e.g., GradCAM) have become standard tools for explaining Convolutional Neural Network (CNN) predictions. However, these approaches typically focus on individual logits, while for neural networks using softmax, the class membership probability estimates depend \textit{only} on the \textit{differences} between logits, not on their absolute values. This disconnect leaves standard CAMs vulnerable to adversarial manipulation, such as passive fooling, where a model is trained to produce misleading CAMs without affecting decision performance. We introduce \textbf{Salience-Hoax Activation Maps (SHAMs)}, an \emph{entropy-aware form of passive fooling} that serves as a benchmark for CAM robustness under adversarial conditions. To address the passive fooling vulnerability, we then propose \textbf{DiffGradCAM}, a novel, lightweight, and contrastive approach to class activation mapping that is both non-suceptible to passive fooling, but also matches the output of standard CAM methods such as GradCAM in the non-adversarial case. Together, SHAM and DiffGradCAM establish a new framework for probing and improving the robustness of saliency-based explanations. We validate both contributions across multi-class tasks with few and many classes.
Non-Generative Energy Based Models
Apr 03, 2023



Energy-based models (EBM) have become increasingly popular within computer vision. EBMs bring a probabilistic approach to training deep neural networks (DNN) and have been shown to enhance performance in areas such as calibration, out-of-distribution detection, and adversarial resistance. However, these advantages come at the cost of estimating input data probabilities, usually using a Langevin based method such as Stochastic Gradient Langevin Dynamics (SGLD), which bring additional computational costs, require parameterization, caching methods for efficiency, and can run into stability and scaling issues. EBMs use dynamical methods to draw samples from the probability density function (PDF) defined by the current state of the network and compare them to the training data using a maximum log likelihood approach to learn the correct PDF. We propose a non-generative training approach, Non-Generative EBM (NG-EBM), that utilizes the {\it{Approximate Mass}}, identified by Grathwohl et al., as a loss term to direct the training. We show that our NG-EBM training strategy retains many of the benefits of EBM in calibration, out-of-distribution detection, and adversarial resistance, but without the computational complexity and overhead of the traditional approaches. In particular, the NG-EBM approach improves the Expected Calibration Error by a factor of 2.5 for CIFAR10 and 7.5 times for CIFAR100, when compared to traditionally trained models.
Explain To Me: Salience-Based Explainability for Synthetic Face Detection Models
Mar 27, 2023



The performance of convolutional neural networks has continued to improve over the last decade. At the same time, as model complexity grows, it becomes increasingly more difficult to explain model decisions. Such explanations may be of critical importance for reliable operation of human-machine pairing setups, or for model selection when the "best" model among many equally-accurate models must be established. Saliency maps represent one popular way of explaining model decisions by highlighting image regions models deem important when making a prediction. However, examining salience maps at scale is not practical. In this paper, we propose five novel methods of leveraging model salience to explain a model behavior at scale. These methods ask: (a) what is the average entropy for a model's salience maps, (b) how does model salience change when fed out-of-set samples, (c) how closely does model salience follow geometrical transformations, (d) what is the stability of model salience across independent training runs, and (e) how does model salience react to salience-guided image degradations. To assess the proposed measures on a concrete and topical problem, we conducted a series of experiments for the task of synthetic face detection with two types of models: those trained traditionally with cross-entropy loss, and those guided by human salience when training to increase model generalizability. These two types of models are characterized by different, interpretable properties of their salience maps, which allows for the evaluation of the correctness of the proposed measures. We offer source codes for each measure along with this paper.
Improving Model's Focus Improves Performance of Deep Learning-Based Synthetic Face Detectors
Mar 01, 2023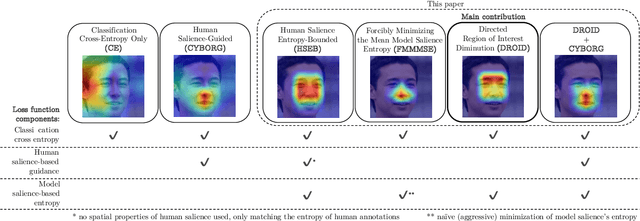
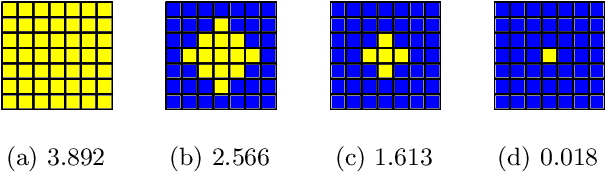
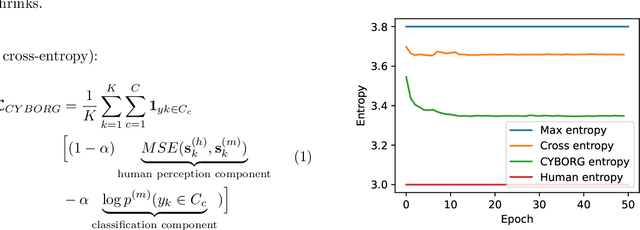

Deep learning-based models generalize better to unknown data samples after being guided "where to look" by incorporating human perception into training strategies. We made an observation that the entropy of the model's salience trained in that way is lower when compared to salience entropy computed for models training without human perceptual intelligence. Thus the question: does further increase of model's focus, by lowering the entropy of model's class activation map, help in further increasing the performance? In this paper we propose and evaluate several entropy-based new loss function components controlling the model's focus, covering the full range of the level of such control, from none to its "aggressive" minimization. We show, using a problem of synthetic face detection, that improving the model's focus, through lowering entropy, leads to models that perform better in an open-set scenario, in which the test samples are synthesized by unknown generative models. We also show that optimal performance is obtained when the model's loss function blends three aspects: regular classification, low-entropy of the model's focus, and human-guided saliency.