 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralist Multimodal LLMs Gain Biometric Expertise via Human Salience
Mar 17, 2026Iris presentation attack detection (PAD) is critical for secure biometric deployments, yet developing specialized models faces significant practical barriers: collecting data representing future unknown attacks is impossible, and collecting diverse-enough data, yet still limited in terms of its predictive power, is expensive. Additionally, sharing biometric data raises privacy concerns. Due to rapid emergence of new attack vectors demanding adaptable solutions, we thus investigate in this paper whether general-purpose multimodal large language models (MLLMs) can perform iris PAD when augmented with human expert knowledge, operating under strict privacy constraints that prohibit sending biometric data to public cloud MLLM services. Through analysis of vision encoder embeddings applied to our dataset, we demonstrate that pre-trained vision transformers in MLLMs inherently cluster many iris attack types despite never being explicitly trained for this task. However, where clustering shows overlap between attack classes, we find that structured prompts incorporating human salience (verbal descriptions from subjects identifying attack indicators) enable these models to resolve ambiguities. Testing on an IRB-restricted dataset of 224 iris images spanning seven attack types, using only university-approved services (Gemini 2.5 Pro) or locally-hosted models (e.g., Llama 3.2-Vision), we show that Gemini with expert-informed prompts outperforms both a specialized convolutional neural networks (CNN)-based baseline and human examiners, while the locally-deployable Llama achieves near-human performance. Our results establish that MLLMs deployable within institutional privacy constraints offer a viable path for iris PAD.
Using Deep Operators to Create Spatio-temporal Surrogates for Dynamical Systems under Uncertainty
Jun 13, 2025Spatio-temporal data, which consists of responses or measurements gathered at different times and positions, is ubiquitous across diverse applications of civil infrastructure. While SciML methods have made significant progress in tackling the issue of response prediction for individual time histories, creating a full spatial-temporal surrogate remains a challenge. This study proposes a novel variant of deep operator networks (DeepONets), namely the full-field Extended DeepONet (FExD), to serve as a spatial-temporal surrogate that provides multi-output response predictions for dynamical systems. The proposed FExD surrogate model effectively learns the full solution operator across multiple degrees of freedom by enhancing the expressiveness of the branch network and expanding the predictive capabilities of the trunk network. The proposed FExD surrogate is deployed to simultaneously capture the dynamics at several sensing locations along a testbed model of a cable-stayed bridge subjected to stochastic ground motions. The ensuing response predictions from the FExD are comprehensively compared against both a vanilla DeepONet and a modified spatio-temporal Extended DeepONet. The results demonstrate the proposed FExD can achieve both superior accuracy and computational efficiency, representing a significant advancement in operator learning for structural dynamics applications.
Non-Generative Energy Based Models
Apr 03, 2023



Energy-based models (EBM) have become increasingly popular within computer vision. EBMs bring a probabilistic approach to training deep neural networks (DNN) and have been shown to enhance performance in areas such as calibration, out-of-distribution detection, and adversarial resistance. However, these advantages come at the cost of estimating input data probabilities, usually using a Langevin based method such as Stochastic Gradient Langevin Dynamics (SGLD), which bring additional computational costs, require parameterization, caching methods for efficiency, and can run into stability and scaling issues. EBMs use dynamical methods to draw samples from the probability density function (PDF) defined by the current state of the network and compare them to the training data using a maximum log likelihood approach to learn the correct PDF. We propose a non-generative training approach, Non-Generative EBM (NG-EBM), that utilizes the {\it{Approximate Mass}}, identified by Grathwohl et al., as a loss term to direct the training. We show that our NG-EBM training strategy retains many of the benefits of EBM in calibration, out-of-distribution detection, and adversarial resistance, but without the computational complexity and overhead of the traditional approaches. In particular, the NG-EBM approach improves the Expected Calibration Error by a factor of 2.5 for CIFAR10 and 7.5 times for CIFAR100, when compared to traditionally trained models.
Explain To Me: Salience-Based Explainability for Synthetic Face Detection Models
Mar 27, 2023



The performance of convolutional neural networks has continued to improve over the last decade. At the same time, as model complexity grows, it becomes increasingly more difficult to explain model decisions. Such explanations may be of critical importance for reliable operation of human-machine pairing setups, or for model selection when the "best" model among many equally-accurate models must be established. Saliency maps represent one popular way of explaining model decisions by highlighting image regions models deem important when making a prediction. However, examining salience maps at scale is not practical. In this paper, we propose five novel methods of leveraging model salience to explain a model behavior at scale. These methods ask: (a) what is the average entropy for a model's salience maps, (b) how does model salience change when fed out-of-set samples, (c) how closely does model salience follow geometrical transformations, (d) what is the stability of model salience across independent training runs, and (e) how does model salience react to salience-guided image degradations. To assess the proposed measures on a concrete and topical problem, we conducted a series of experiments for the task of synthetic face detection with two types of models: those trained traditionally with cross-entropy loss, and those guided by human salience when training to increase model generalizability. These two types of models are characterized by different, interpretable properties of their salience maps, which allows for the evaluation of the correctness of the proposed measures. We offer source codes for each measure along with this paper.
Improving Model's Focus Improves Performance of Deep Learning-Based Synthetic Face Detectors
Mar 01, 2023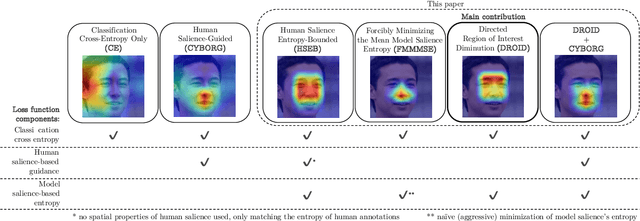
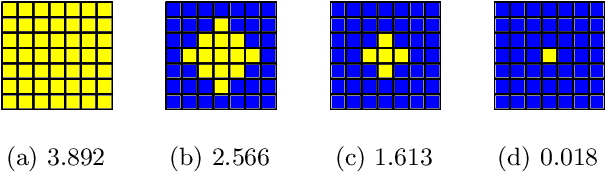
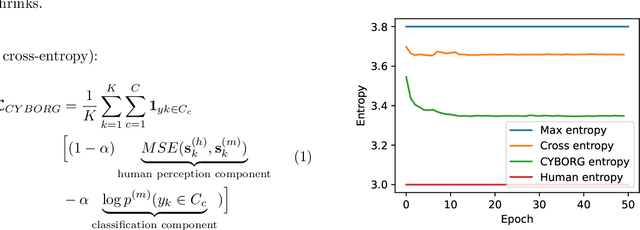

Deep learning-based models generalize better to unknown data samples after being guided "where to look" by incorporating human perception into training strategies. We made an observation that the entropy of the model's salience trained in that way is lower when compared to salience entropy computed for models training without human perceptual intelligence. Thus the question: does further increase of model's focus, by lowering the entropy of model's class activation map, help in further increasing the performance? In this paper we propose and evaluate several entropy-based new loss function components controlling the model's focus, covering the full range of the level of such control, from none to its "aggressive" minimization. We show, using a problem of synthetic face detection, that improving the model's focus, through lowering entropy, leads to models that perform better in an open-set scenario, in which the test samples are synthesized by unknown generative models. We also show that optimal performance is obtained when the model's loss function blends three aspects: regular classification, low-entropy of the model's focus, and human-guided saliency.
On the Veracity of Cyber Intrusion Alerts Synthesized by Generative Adversarial Networks
Aug 03, 2019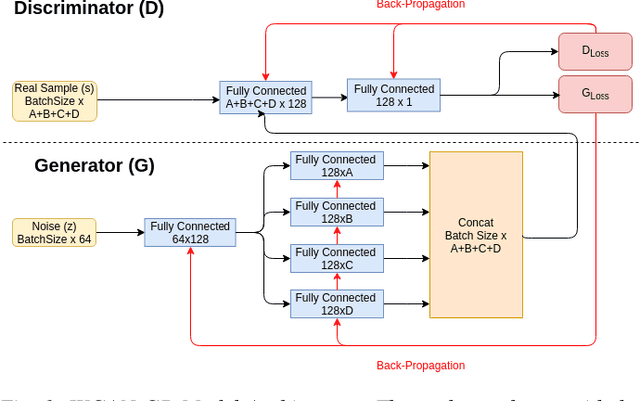
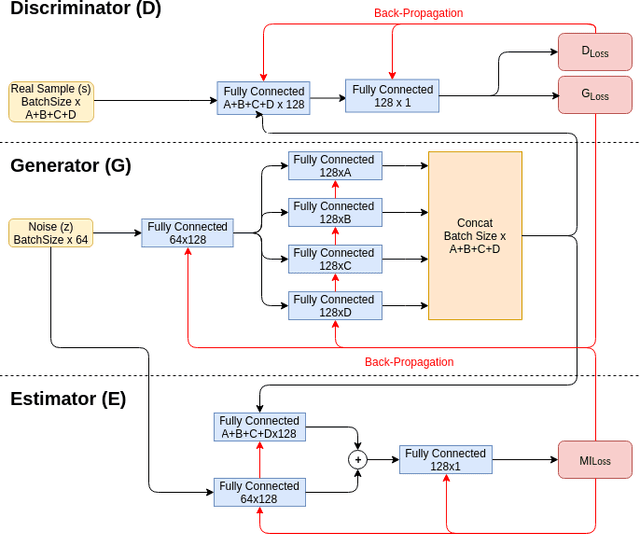
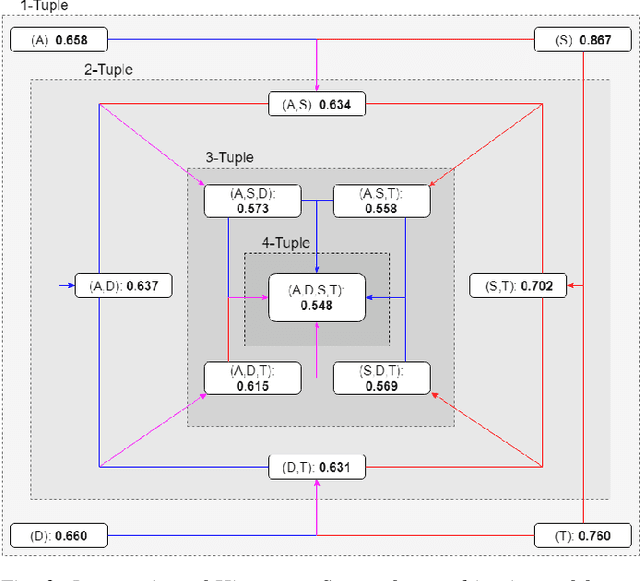
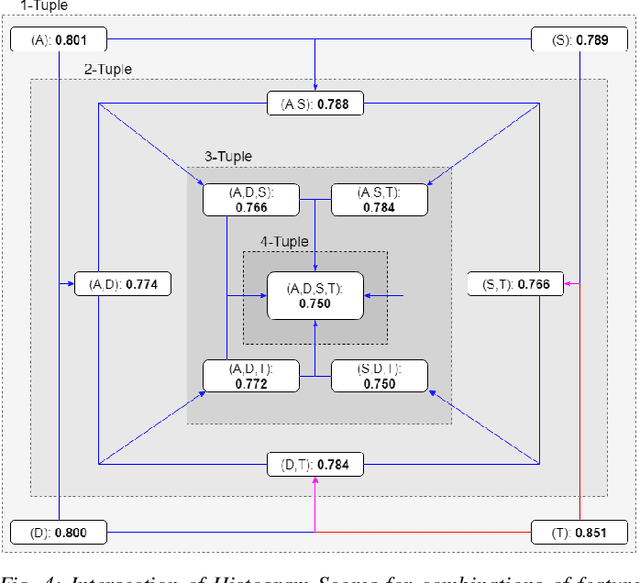
Recreating cyber-attack alert data with a high level of fidelity is challenging due to the intricate interaction between features, non-homogeneity of alerts, and potential for rare yet critical samples. Generative Adversarial Networks (GANs) have been shown to effectively learn complex data distributions with the intent of creating increasingly realistic data. This paper presents the application of GANs to cyber-attack alert data and shows that GANs not only successfully learn to generate realistic alerts, but also reveal feature dependencies within alerts. This is accomplished by reviewing the intersection of histograms for varying alert-feature combinations between the ground truth and generated datsets. Traditional statistical metrics, such as conditional and joint entropy, are also employed to verify the accuracy of these dependencies. Finally, it is shown that a Mutual Information constraint on the network can be used to increase the generation of low probability, critical, alert values. By mapping alerts to a set of attack stages it is shown that the output of these low probability alerts has a direct contextual meaning for Cyber Security analysts. Overall, this work provides the basis for generating new cyber intrusion alerts and provides evidence that synthesized alerts emulate critical dependencies from the source dataset.
Visual Recognition of Paper Analytical Device Images for Detection of Falsified Pharmaceuticals
Apr 13, 2017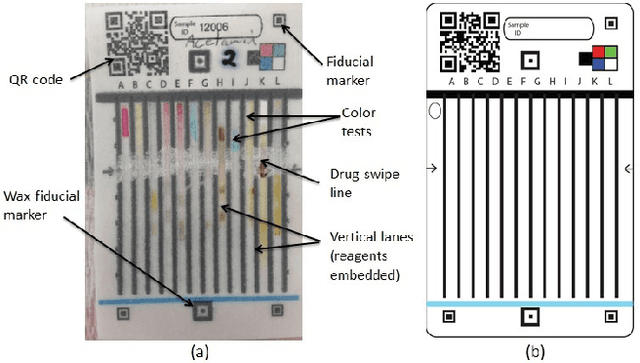
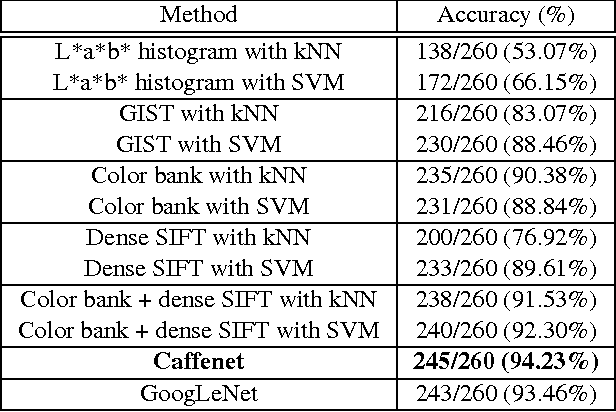


Falsification of medicines is a big problem in many developing countries, where technological infrastructure is inadequate to detect these harmful products. We have developed a set of inexpensive paper cards, called Paper Analytical Devices (PADs), which can efficiently classify drugs based on their chemical composition, as a potential solution to the problem. These cards have different reagents embedded in them which produce a set of distinctive color descriptors upon reacting with the chemical compounds that constitute pharmaceutical dosage forms. If a falsified version of the medicine lacks the active ingredient or includes substitute fillers, the difference in color is perceivable by humans. However, reading the cards with accuracy takes training and practice, which may hamper their scaling and implementation in low resource settings. To deal with this, we have developed an automatic visual recognition system to read the results from the PAD images. At first, the optimal set of reagents was found by running singular value decomposition on the intensity values of the color tones in the card images. A dataset of cards embedded with these reagents is produced to generate the most distinctive results for a set of 26 different active pharmaceutical ingredients (APIs) and excipients. Then, we train two popular convolutional neural network (CNN) models, with the card images. We also extract some "hand-crafted" features from the images and train a nearest neighbor classifier and a non-linear support vector machine with them. On testing, higher-level features performed much better in accurately classifying the PAD images, with the CNN models reaching the highest average accuracy of over 94\%.