 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEditYourself: Audio-Driven Generation and Manipulation of Talking Head Videos with Diffusion Transformers
Jan 29, 2026Current generative video models excel at producing novel content from text and image prompts, but leave a critical gap in editing existing pre-recorded videos, where minor alterations to the spoken script require preserving motion, temporal coherence, speaker identity, and accurate lip synchronization. We introduce EditYourself, a DiT-based framework for audio-driven video-to-video (V2V) editing that enables transcript-based modification of talking head videos, including the seamless addition, removal, and retiming of visually spoken content. Building on a general-purpose video diffusion model, EditYourself augments its V2V capabilities with audio conditioning and region-aware, edit-focused training extensions. This enables precise lip synchronization and temporally coherent restructuring of existing performances via spatiotemporal inpainting, including the synthesis of realistic human motion in newly added segments, while maintaining visual fidelity and identity consistency over long durations. This work represents a foundational step toward generative video models as practical tools for professional video post-production.
Analyzing the Impact of Shape & Context on the Face Recognition Performance of Deep Networks
Aug 05, 2022
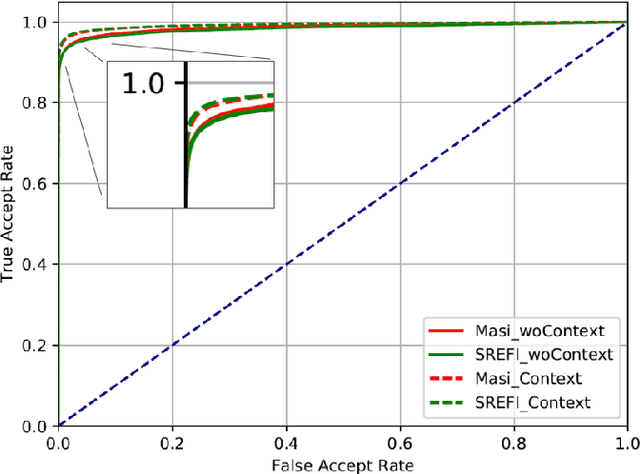
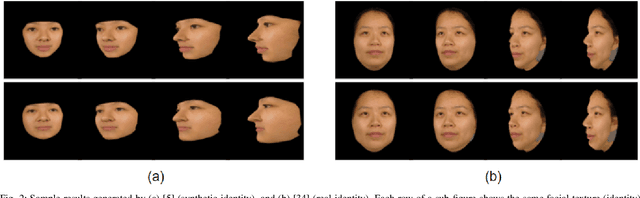
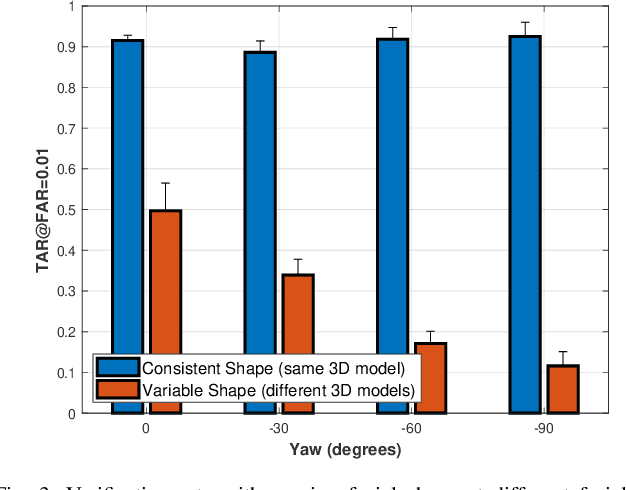
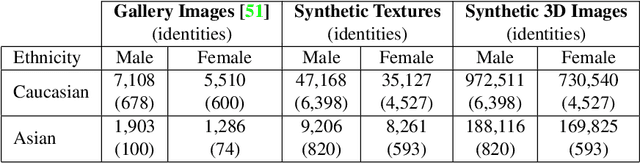
In this article, we analyze how changing the underlying 3D shape of the base identity in face images can distort their overall appearance, especially from the perspective of deep face recognition. As done in popular training data augmentation schemes, we graphically render real and synthetic face images with randomly chosen or best-fitting 3D face models to generate novel views of the base identity. We compare deep features generated from these images to assess the perturbation these renderings introduce into the original identity. We perform this analysis at various degrees of facial yaw with the base identities varying in gender and ethnicity. Additionally, we investigate if adding some form of context and background pixels in these rendered images, when used as training data, further improves the downstream performance of a face recognition model. Our experiments demonstrate the significance of facial shape in accurate face matching and underpin the importance of contextual data for network training.
Driver Glance Classification In-the-wild: Towards Generalization Across Domains and Subjects
Dec 05, 2020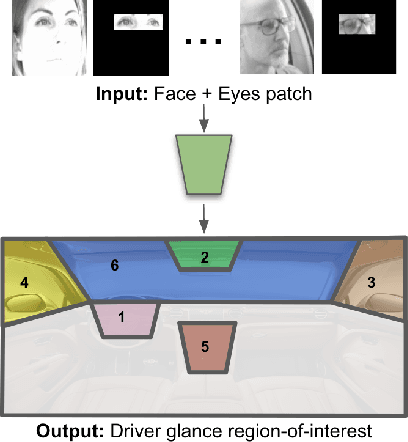
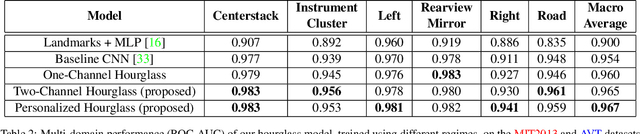


Distracted drivers are dangerous drivers. Equipping advanced driver assistance systems (ADAS) with the ability to detect driver distraction can help prevent accidents and improve driver safety. In order to detect driver distraction, an ADAS must be able to monitor their visual attention. We propose a model that takes as input a patch of the driver's face along with a crop of the eye-region and classifies their glance into 6 coarse regions-of-interest (ROIs) in the vehicle. We demonstrate that an hourglass network, trained with an additional reconstruction loss, allows the model to learn stronger contextual feature representations than a traditional encoder-only classification module. To make the system robust to subject-specific variations in appearance and behavior, we design a personalized hourglass model tuned with an auxiliary input representing the driver's baseline glance behavior. Finally, we present a weakly supervised multi-domain training regimen that enables the hourglass to jointly learn representations from different domains (varying in camera type, angle), utilizing unlabeled samples and thereby reducing annotation cost.
In-the-wild Drowsiness Detection from Facial Expressions
Oct 21, 2020
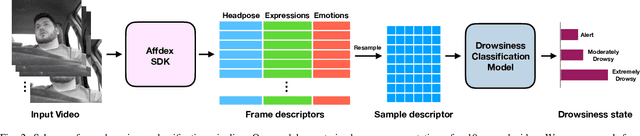
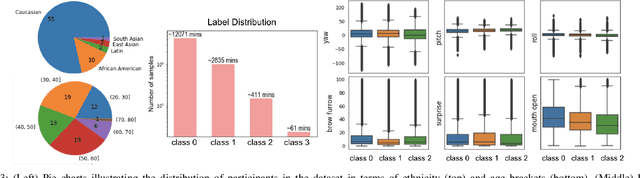
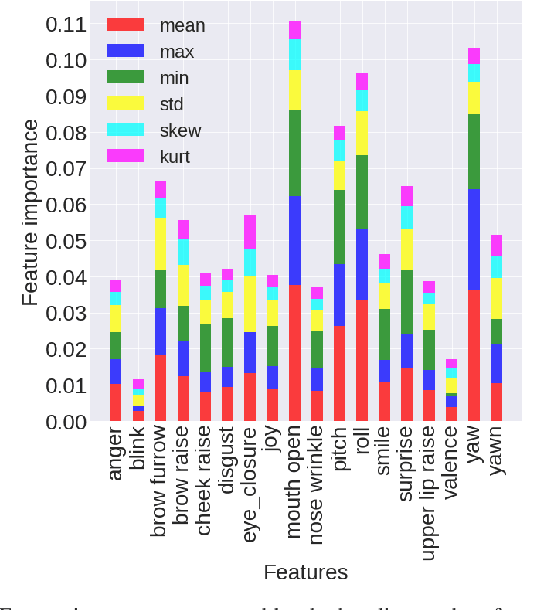
Driving in a state of drowsiness is a major cause of road accidents, resulting in tremendous damage to life and property. Developing robust, automatic, real-time systems that can infer drowsiness states of drivers has the potential of making life-saving impact. However, developing drowsiness detection systems that work well in real-world scenarios is challenging because of the difficulties associated with collecting high-volume realistic drowsy data and modeling the complex temporal dynamics of evolving drowsy states. In this paper, we propose a data collection protocol that involves outfitting vehicles of overnight shift workers with camera kits that record their faces while driving. We develop a drowsiness annotation guideline to enable humans to label the collected videos into 4 levels of drowsiness: `alert', `slightly drowsy', `moderately drowsy' and `extremely drowsy'. We experiment with different convolutional and temporal neural network architectures to predict drowsiness states from pose, expression and emotion-based representation of the input video of the driver's face. Our best performing model achieves a macro ROC-AUC of 0.78, compared to 0.72 for a baseline model.
LEGAN: Disentangled Manipulation of Directional Lighting and Facial Expressions by Leveraging Human Perceptual Judgements
Oct 04, 2020
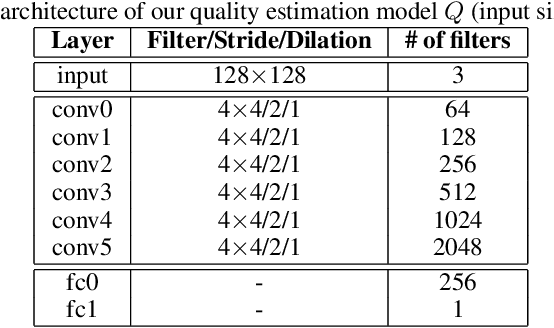

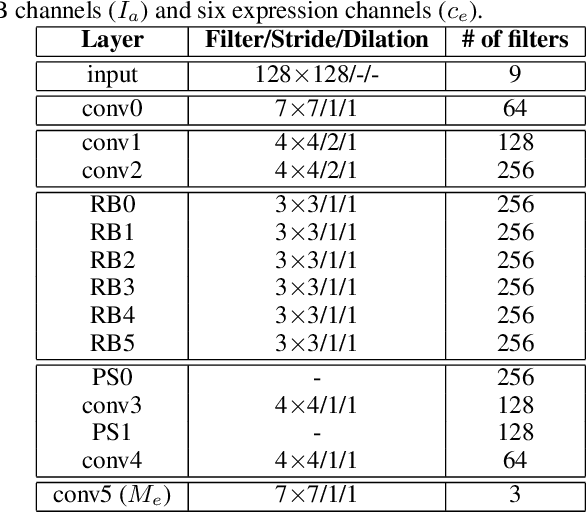
Building facial analysis systems that generalize to extreme variations in lighting and facial expressions is a challenging problem that can potentially be alleviated using natural-looking synthetic data. Towards that, we propose LEGAN, a novel synthesis framework that leverages perceptual quality judgments for jointly manipulating lighting and expressions in face images, without requiring paired training data. LEGAN disentangles the lighting and expression subspaces and performs transformations in the feature space before upscaling to the desired output image. The fidelity of the synthetic image is further refined by integrating a perceptual quality estimation model into the LEGAN framework as an auxiliary discriminator. The quality estimation model is learned from face images rendered using multiple synthesis methods and their crowd-sourced naturalness ratings using a margin-based regression loss. Using objective metrics like FID and LPIPS, LEGAN is shown to generate higher quality face images when compared with popular GAN models like pix2pix, CycleGAN and StarGAN for lighting and expression synthesis. We also conduct a perceptual study using images synthesized by LEGAN and other GAN models, trained with and without the quality based auxiliary discriminator, and show the correlation between our quality estimation and visual fidelity. Finally, we demonstrate the effectiveness of LEGAN as training data augmenter for expression recognition and face verification tasks.
On Hallucinating Context and Background Pixels from a Face Mask using Multi-scale GANs
Nov 24, 2018
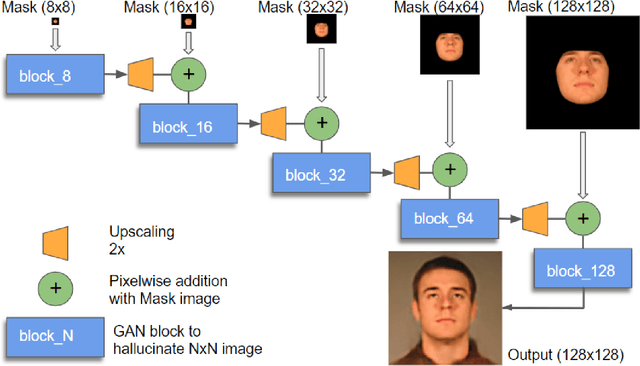

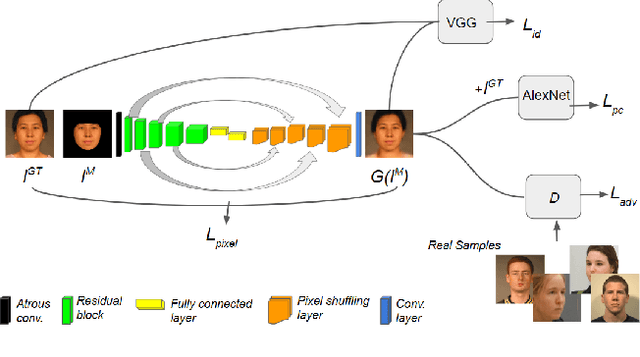
We propose a multi-scale GAN model to hallucinate realistic context (forehead, hair, neck, clothes) and background pixels automatically from a single input face mask. Instead of swapping a face on to an existing picture, our model directly generates realistic context and background pixels based on the features of the provided face mask. Unlike face inpainting algorithms, it can generate realistic hallucinations even for a large number of missing pixels. Our model is composed of a cascaded network of GAN blocks, each tasked with hallucination of missing pixels at a particular resolution while guiding the synthesis process of the next GAN block. The hallucinated full face image is made photo-realistic by using a combination of reconstruction, perceptual, adversarial and identity preserving losses at each block of the network. With a set of extensive experiments, we demonstrate the effectiveness of our model in hallucinating context and background pixels from face masks varying in facial pose, expression and lighting, collected from multiple datasets subject disjoint with our training data. We also compare our method with two popular face swapping and face completion methods in terms of visual quality and recognition performance. Additionally, we analyze our cascaded pipeline and compare it with the recently proposed progressive growing of GANs.
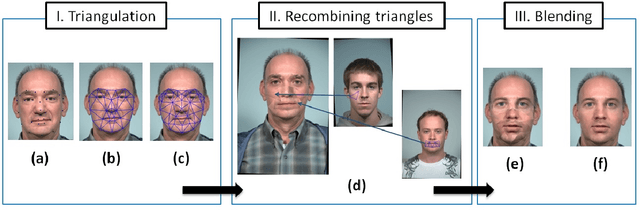
Fast Face Image Synthesis with Minimal Training
Nov 05, 2018
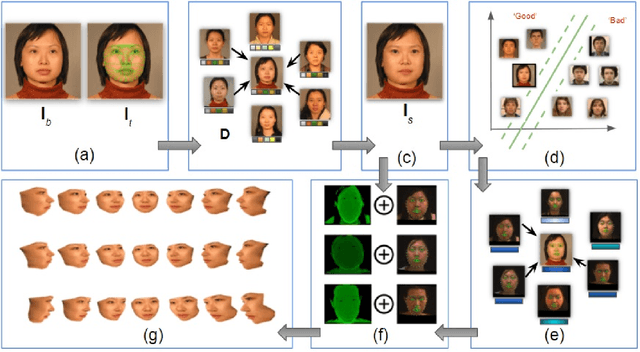
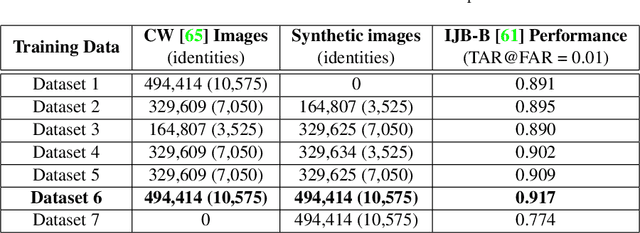
We propose an algorithm to generate realistic face im-ages of both real and synthetic identities (people who donot exist) with different facial yaw, shape and resolution.The synthesized images can be used to augment datasets totrain CNNs or as massive distractor sets for biometric ver-ification experiments without any privacy concerns. Addi-tionally, law enforcement can make use of this technique totrain forensic experts to recognize faces. Our method sam-ples face components from a pool of multiple face images ofreal identities to generate the synthetic texture. Then, a real3D head model compatible to the generated texture is usedto render it under different facial yaw transformations. Weperform multiple quantitative experiments to assess the ef-fectiveness of our synthesis procedure in CNN training andits potential use to generate distractor face images. Addi-tionally, we compare our method with popular GAN modelsin terms of visual quality and execution time.
To Frontalize or Not To Frontalize: Do We Really Need Elaborate Pre-processing To Improve Face Recognition?
Mar 27, 2018

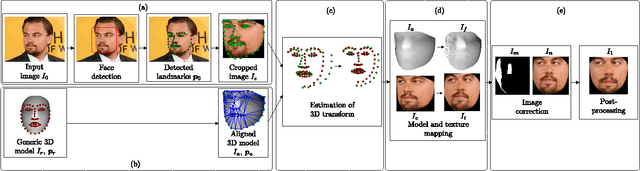
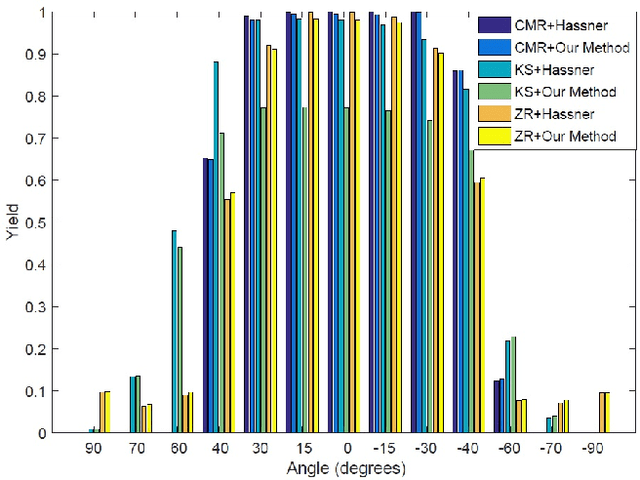
Face recognition performance has improved remarkably in the last decade. Much of this success can be attributed to the development of deep learning techniques such as convolutional neural networks (CNNs). While CNNs have pushed the state-of-the-art forward, their training process requires a large amount of clean and correctly labelled training data. If a CNN is intended to tolerate facial pose, then we face an important question: should this training data be diverse in its pose distribution, or should face images be normalized to a single pose in a pre-processing step? To address this question, we evaluate a number of popular facial landmarking and pose correction algorithms to understand their effect on facial recognition performance. Additionally, we introduce a new, automatic, single-image frontalization scheme that exceeds the performance of current algorithms. CNNs trained using sets of different pre-processing methods are used to extract features from the Point and Shoot Challenge (PaSC) and CMU Multi-PIE datasets. We assert that the subsequent verification and recognition performance serves to quantify the effectiveness of each pose correction scheme.
SREFI: Synthesis of Realistic Example Face Images
Apr 25, 2017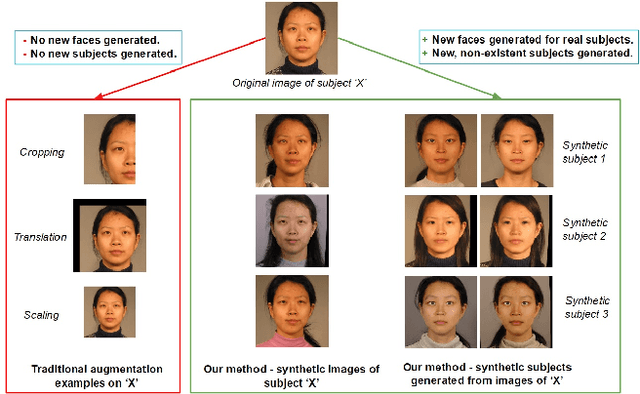


In this paper, we propose a novel face synthesis approach that can generate an arbitrarily large number of synthetic images of both real and synthetic identities. Thus a face image dataset can be expanded in terms of the number of identities represented and the number of images per identity using this approach, without the identity-labeling and privacy complications that come from downloading images from the web. To measure the visual fidelity and uniqueness of the synthetic face images and identities, we conducted face matching experiments with both human participants and a CNN pre-trained on a dataset of 2.6M real face images. To evaluate the stability of these synthetic faces, we trained a CNN model with an augmented dataset containing close to 200,000 synthetic faces. We used a snapshot of this trained CNN to recognize extremely challenging frontal (real) face images. Experiments showed training with the augmented faces boosted the face recognition performance of the CNN.
Visual Recognition of Paper Analytical Device Images for Detection of Falsified Pharmaceuticals
Apr 13, 2017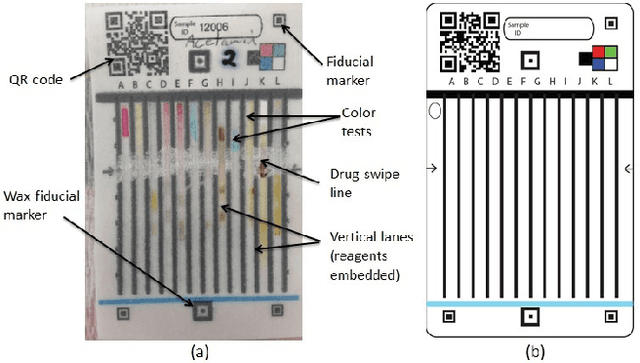
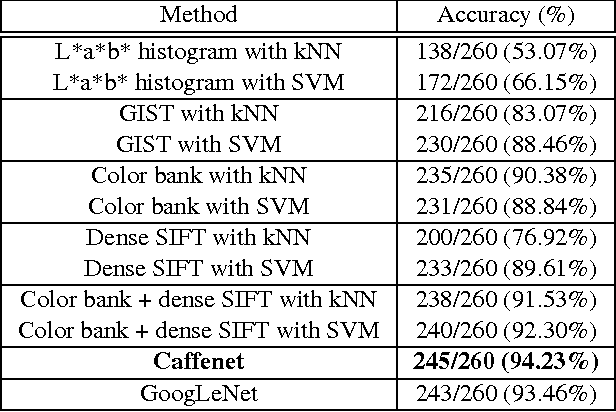


Falsification of medicines is a big problem in many developing countries, where technological infrastructure is inadequate to detect these harmful products. We have developed a set of inexpensive paper cards, called Paper Analytical Devices (PADs), which can efficiently classify drugs based on their chemical composition, as a potential solution to the problem. These cards have different reagents embedded in them which produce a set of distinctive color descriptors upon reacting with the chemical compounds that constitute pharmaceutical dosage forms. If a falsified version of the medicine lacks the active ingredient or includes substitute fillers, the difference in color is perceivable by humans. However, reading the cards with accuracy takes training and practice, which may hamper their scaling and implementation in low resource settings. To deal with this, we have developed an automatic visual recognition system to read the results from the PAD images. At first, the optimal set of reagents was found by running singular value decomposition on the intensity values of the color tones in the card images. A dataset of cards embedded with these reagents is produced to generate the most distinctive results for a set of 26 different active pharmaceutical ingredients (APIs) and excipients. Then, we train two popular convolutional neural network (CNN) models, with the card images. We also extract some "hand-crafted" features from the images and train a nearest neighbor classifier and a non-linear support vector machine with them. On testing, higher-level features performed much better in accurately classifying the PAD images, with the CNN models reaching the highest average accuracy of over 94\%.