 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Recognition of Paper Analytical Device Images for Detection of Falsified Pharmaceuticals
Apr 13, 2017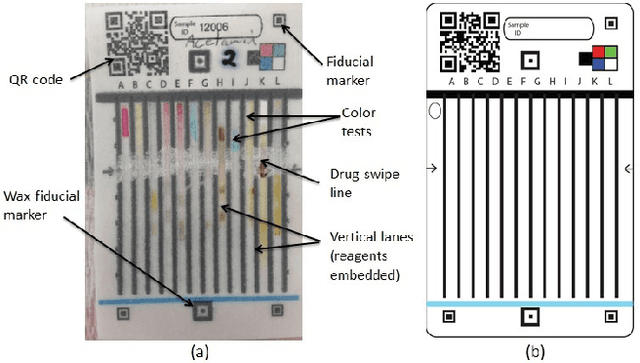
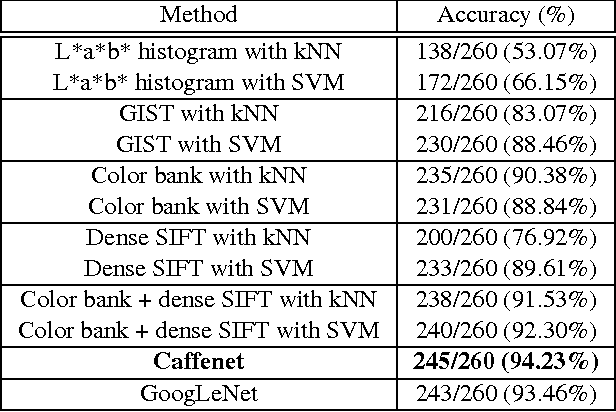


Falsification of medicines is a big problem in many developing countries, where technological infrastructure is inadequate to detect these harmful products. We have developed a set of inexpensive paper cards, called Paper Analytical Devices (PADs), which can efficiently classify drugs based on their chemical composition, as a potential solution to the problem. These cards have different reagents embedded in them which produce a set of distinctive color descriptors upon reacting with the chemical compounds that constitute pharmaceutical dosage forms. If a falsified version of the medicine lacks the active ingredient or includes substitute fillers, the difference in color is perceivable by humans. However, reading the cards with accuracy takes training and practice, which may hamper their scaling and implementation in low resource settings. To deal with this, we have developed an automatic visual recognition system to read the results from the PAD images. At first, the optimal set of reagents was found by running singular value decomposition on the intensity values of the color tones in the card images. A dataset of cards embedded with these reagents is produced to generate the most distinctive results for a set of 26 different active pharmaceutical ingredients (APIs) and excipients. Then, we train two popular convolutional neural network (CNN) models, with the card images. We also extract some "hand-crafted" features from the images and train a nearest neighbor classifier and a non-linear support vector machine with them. On testing, higher-level features performed much better in accurately classifying the PAD images, with the CNN models reaching the highest average accuracy of over 94\%.