 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriver Glance Classification In-the-wild: Towards Generalization Across Domains and Subjects
Dec 05, 2020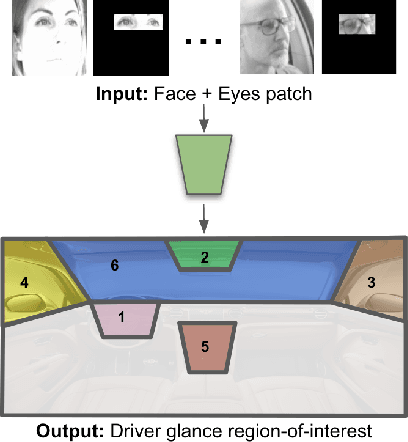
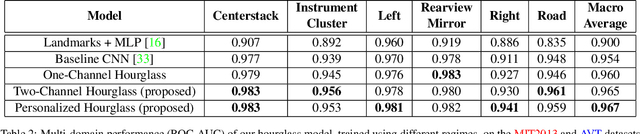


Distracted drivers are dangerous drivers. Equipping advanced driver assistance systems (ADAS) with the ability to detect driver distraction can help prevent accidents and improve driver safety. In order to detect driver distraction, an ADAS must be able to monitor their visual attention. We propose a model that takes as input a patch of the driver's face along with a crop of the eye-region and classifies their glance into 6 coarse regions-of-interest (ROIs) in the vehicle. We demonstrate that an hourglass network, trained with an additional reconstruction loss, allows the model to learn stronger contextual feature representations than a traditional encoder-only classification module. To make the system robust to subject-specific variations in appearance and behavior, we design a personalized hourglass model tuned with an auxiliary input representing the driver's baseline glance behavior. Finally, we present a weakly supervised multi-domain training regimen that enables the hourglass to jointly learn representations from different domains (varying in camera type, angle), utilizing unlabeled samples and thereby reducing annotation cost.
In-the-wild Drowsiness Detection from Facial Expressions
Oct 21, 2020
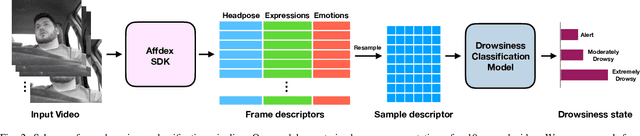
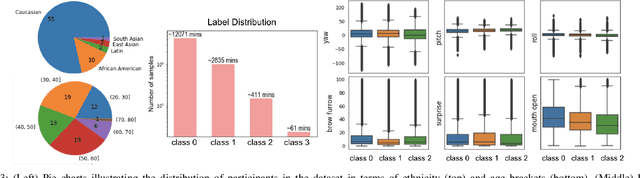
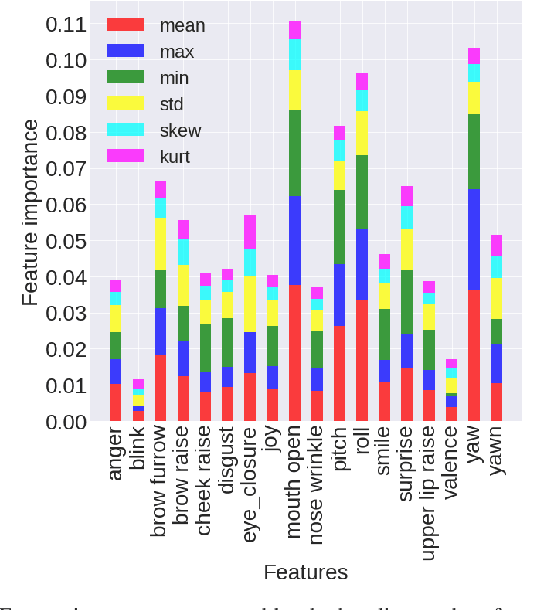
Driving in a state of drowsiness is a major cause of road accidents, resulting in tremendous damage to life and property. Developing robust, automatic, real-time systems that can infer drowsiness states of drivers has the potential of making life-saving impact. However, developing drowsiness detection systems that work well in real-world scenarios is challenging because of the difficulties associated with collecting high-volume realistic drowsy data and modeling the complex temporal dynamics of evolving drowsy states. In this paper, we propose a data collection protocol that involves outfitting vehicles of overnight shift workers with camera kits that record their faces while driving. We develop a drowsiness annotation guideline to enable humans to label the collected videos into 4 levels of drowsiness: `alert', `slightly drowsy', `moderately drowsy' and `extremely drowsy'. We experiment with different convolutional and temporal neural network architectures to predict drowsiness states from pose, expression and emotion-based representation of the input video of the driver's face. Our best performing model achieves a macro ROC-AUC of 0.78, compared to 0.72 for a baseline model.
LEGAN: Disentangled Manipulation of Directional Lighting and Facial Expressions by Leveraging Human Perceptual Judgements
Oct 04, 2020
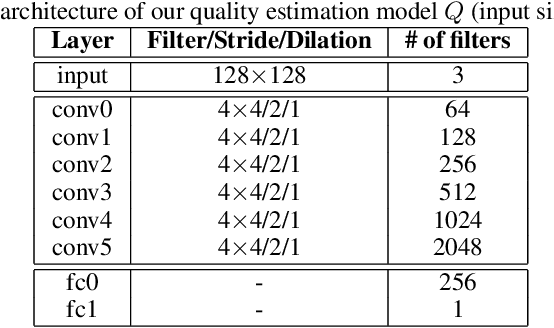

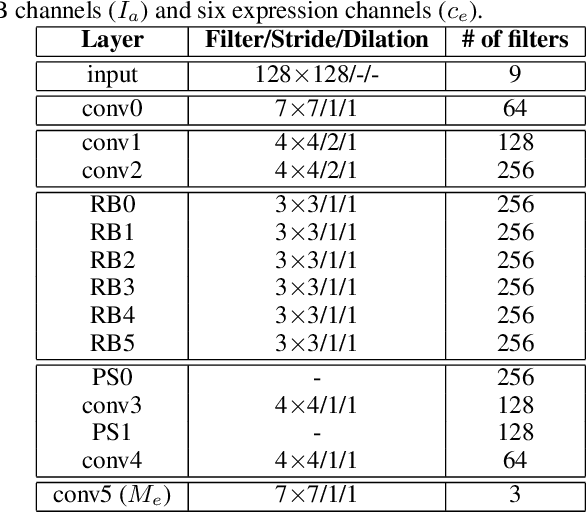
Building facial analysis systems that generalize to extreme variations in lighting and facial expressions is a challenging problem that can potentially be alleviated using natural-looking synthetic data. Towards that, we propose LEGAN, a novel synthesis framework that leverages perceptual quality judgments for jointly manipulating lighting and expressions in face images, without requiring paired training data. LEGAN disentangles the lighting and expression subspaces and performs transformations in the feature space before upscaling to the desired output image. The fidelity of the synthetic image is further refined by integrating a perceptual quality estimation model into the LEGAN framework as an auxiliary discriminator. The quality estimation model is learned from face images rendered using multiple synthesis methods and their crowd-sourced naturalness ratings using a margin-based regression loss. Using objective metrics like FID and LPIPS, LEGAN is shown to generate higher quality face images when compared with popular GAN models like pix2pix, CycleGAN and StarGAN for lighting and expression synthesis. We also conduct a perceptual study using images synthesized by LEGAN and other GAN models, trained with and without the quality based auxiliary discriminator, and show the correlation between our quality estimation and visual fidelity. Finally, we demonstrate the effectiveness of LEGAN as training data augmenter for expression recognition and face verification tasks.