 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Hallucinating Context and Background Pixels from a Face Mask using Multi-scale GANs
Nov 24, 2018
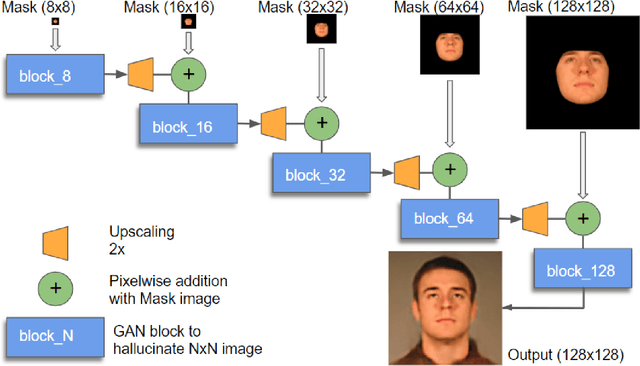

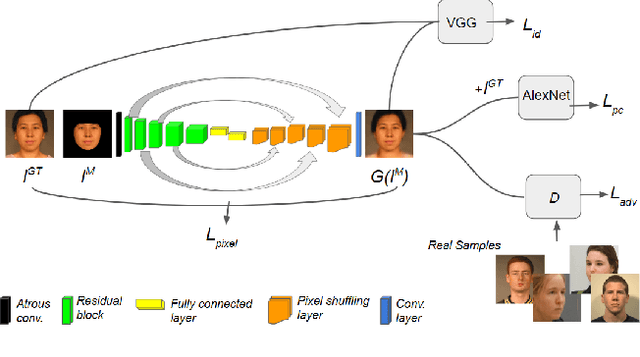
We propose a multi-scale GAN model to hallucinate realistic context (forehead, hair, neck, clothes) and background pixels automatically from a single input face mask. Instead of swapping a face on to an existing picture, our model directly generates realistic context and background pixels based on the features of the provided face mask. Unlike face inpainting algorithms, it can generate realistic hallucinations even for a large number of missing pixels. Our model is composed of a cascaded network of GAN blocks, each tasked with hallucination of missing pixels at a particular resolution while guiding the synthesis process of the next GAN block. The hallucinated full face image is made photo-realistic by using a combination of reconstruction, perceptual, adversarial and identity preserving losses at each block of the network. With a set of extensive experiments, we demonstrate the effectiveness of our model in hallucinating context and background pixels from face masks varying in facial pose, expression and lighting, collected from multiple datasets subject disjoint with our training data. We also compare our method with two popular face swapping and face completion methods in terms of visual quality and recognition performance. Additionally, we analyze our cascaded pipeline and compare it with the recently proposed progressive growing of GANs.
Fast Face Image Synthesis with Minimal Training
Nov 05, 2018
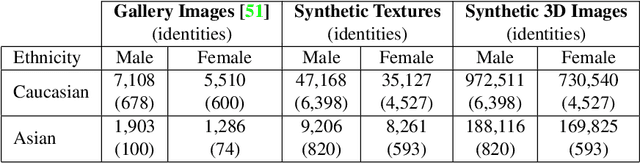
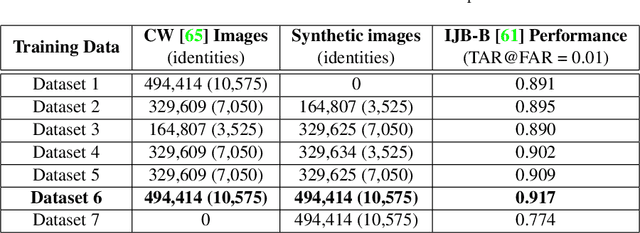
We propose an algorithm to generate realistic face im-ages of both real and synthetic identities (people who donot exist) with different facial yaw, shape and resolution.The synthesized images can be used to augment datasets totrain CNNs or as massive distractor sets for biometric ver-ification experiments without any privacy concerns. Addi-tionally, law enforcement can make use of this technique totrain forensic experts to recognize faces. Our method sam-ples face components from a pool of multiple face images ofreal identities to generate the synthetic texture. Then, a real3D head model compatible to the generated texture is usedto render it under different facial yaw transformations. Weperform multiple quantitative experiments to assess the ef-fectiveness of our synthesis procedure in CNN training andits potential use to generate distractor face images. Addi-tionally, we compare our method with popular GAN modelsin terms of visual quality and execution time.
Beyond Pixels: Image Provenance Analysis Leveraging Metadata
Jul 15, 2018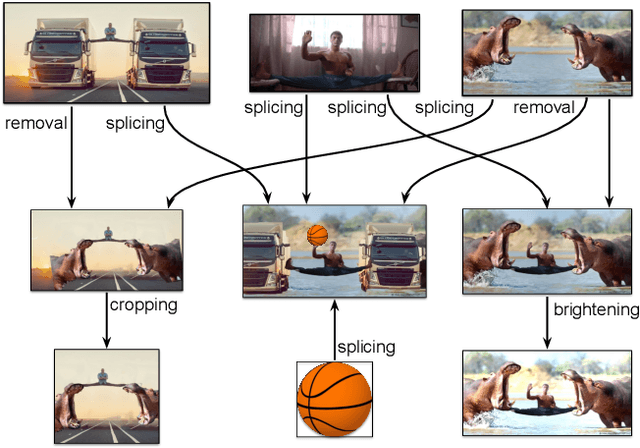
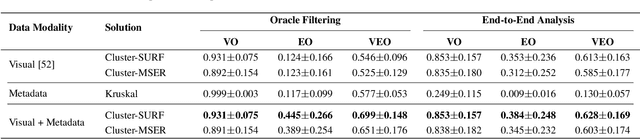
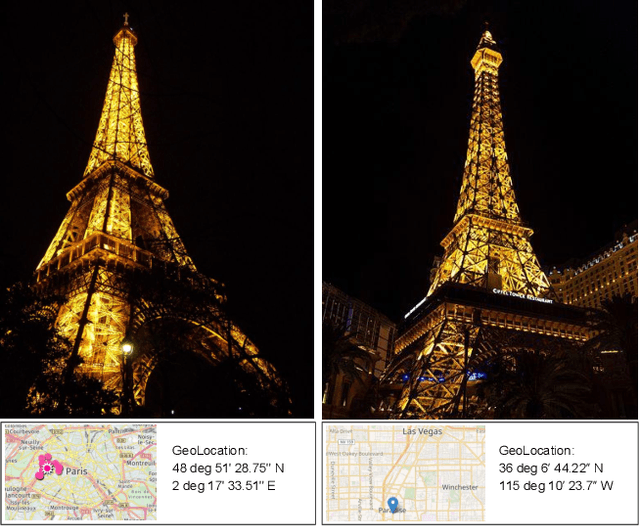
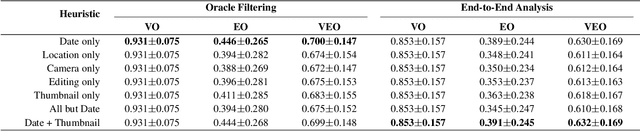
Creative works, whether paintings or memes, follow unique journeys that result in their final form. Understanding these journeys, a process known as "provenance analysis", provides rich insights into the use, motivation, and authenticity underlying any given work. The application of this type of study to the expanse of unregulated content on the Internet is what we consider in this paper. Provenance analysis provides a snapshot of the chronology and validity of content as it is uploaded, re-uploaded, and modified over time. Although still in its infancy, automated provenance analysis for online multimedia is already being applied to different types of content. Most current works seek to build provenance graphs based on the shared content between images or videos. This can be a computationally expensive task, especially when considering the vast influx of content that the Internet sees every day. Utilizing non-content-based information, such as timestamps, geotags, and camera IDs can help provide important insights into the path a particular image or video has traveled during its time on the Internet without large computational overhead. This paper tests the scope and applicability of metadata-based inferences for provenance graph construction in two different scenarios: digital image forensics and cultural analytics.
Domain-Specific Human-Inspired Binarized Statistical Image Features for Iris Recognition
Jul 13, 2018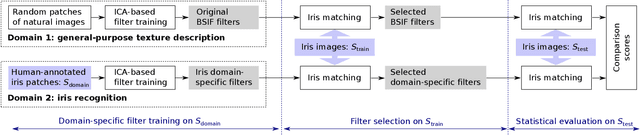



Binarized statistical image features (BSIF) have been successfully used for texture analysis in many computer vision tasks, including iris recognition and biometric presentation attack detection. One important point is that all applications of BSIF in iris recognition have used the original BSIF filters, which were trained on image patches extracted from natural images. This paper tests the question of whether domain-specific BSIF can give better performance than the default BSIF. The second important point is in the selection of image patches to use in training for BSIF. Can image patches derived from eye-tracking experiments, in which humans perform an iris recognition task, give better performance than random patches? Our results say that (1) domain-specific BSIF features can out-perform the default BSIF features, and (2) selecting image patches in a task-specific manner guided by human performance can out-perform selecting random patches. These results are important because BSIF is often regarded as a generic texture tool that does not need any domain adaptation, and human-task-guided selection of patches for training has never (to our knowledge) been done. This paper follows the reproducible research requirements, and the new iris-domain-specific BSIF filters, the patches used in filter training, the database used in testing and the source codes of the designed iris recognition method are made available along with this paper to facilitate applications of this concept.
Performance of Humans in Iris Recognition: The Impact of Iris Condition and Annotation-driven Verification
Jul 13, 2018



This paper advances the state of the art in human examination of iris images by (1) assessing the impact of different iris conditions in identity verification, and (2) introducing an annotation step that improves the accuracy of people's decisions. In a first experimental session, 114 subjects were asked to decide if pairs of iris images depict the same eye (genuine pairs) or two distinct eyes (impostor pairs). The image pairs sampled six conditions: (1) easy for algorithms to classify, (2) difficult for algorithms to classify, (3) large difference in pupil dilation, (4) disease-affected eyes, (5) identical twins, and (6) post-mortem samples. In a second session, 85 of the 114 subjects were asked to annotate matching and non-matching regions that supported their decisions. Subjects were allowed to change their initial classification as a result of the annotation process. Results suggest that: (a) people improve their identity verification accuracy when asked to annotate matching and non-matching regions between the pair of images, (b) images depicting the same eye with large difference in pupil dilation were the most challenging to subjects, but benefited well from the annotation-driven classification, (c) humans performed better than iris recognition algorithms when verifying genuine pairs of post-mortem and disease-affected eyes (i.e., samples showing deformations that go beyond the distortions of a healthy iris due to pupil dilation), and (d) annotation does not improve accuracy of analyzing images from identical twins, which remain confusing for people.
Image Provenance Analysis at Scale
Jan 23, 2018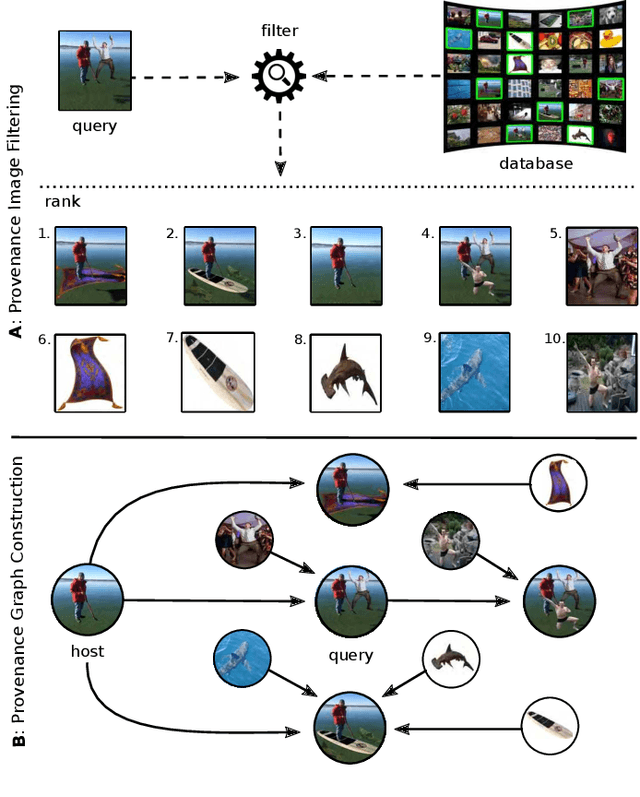
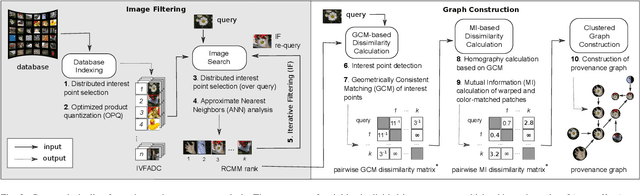
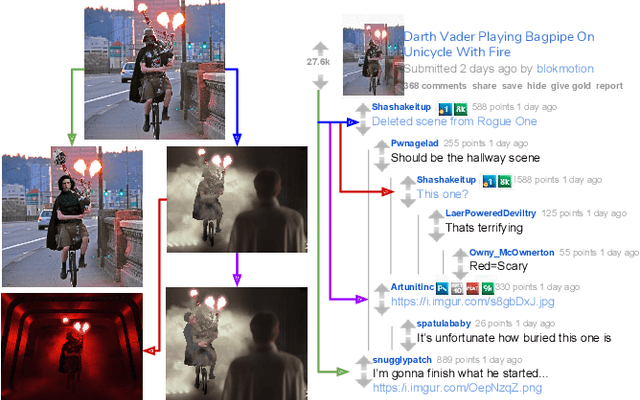
Prior art has shown it is possible to estimate, through image processing and computer vision techniques, the types and parameters of transformations that have been applied to the content of individual images to obtain new images. Given a large corpus of images and a query image, an interesting further step is to retrieve the set of original images whose content is present in the query image, as well as the detailed sequences of transformations that yield the query image given the original images. This is a problem that recently has received the name of image provenance analysis. In these times of public media manipulation ( e.g., fake news and meme sharing), obtaining the history of image transformations is relevant for fact checking and authorship verification, among many other applications. This article presents an end-to-end processing pipeline for image provenance analysis, which works at real-world scale. It employs a cutting-edge image filtering solution that is custom-tailored for the problem at hand, as well as novel techniques for obtaining the provenance graph that expresses how the images, as nodes, are ancestrally connected. A comprehensive set of experiments for each stage of the pipeline is provided, comparing the proposed solution with state-of-the-art results, employing previously published datasets. In addition, this work introduces a new dataset of real-world provenance cases from the social media site Reddit, along with baseline results.
SREFI: Synthesis of Realistic Example Face Images
Apr 25, 2017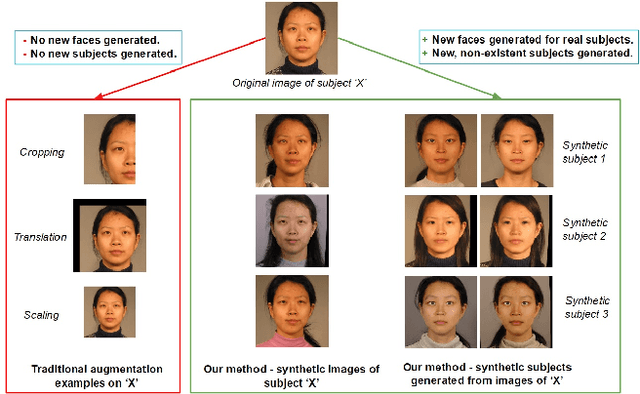


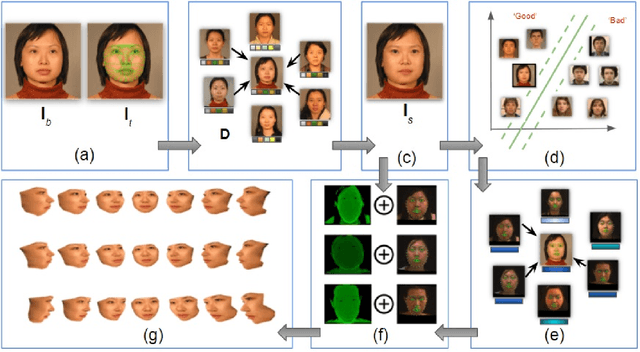
In this paper, we propose a novel face synthesis approach that can generate an arbitrarily large number of synthetic images of both real and synthetic identities. Thus a face image dataset can be expanded in terms of the number of identities represented and the number of images per identity using this approach, without the identity-labeling and privacy complications that come from downloading images from the web. To measure the visual fidelity and uniqueness of the synthetic face images and identities, we conducted face matching experiments with both human participants and a CNN pre-trained on a dataset of 2.6M real face images. To evaluate the stability of these synthetic faces, we trained a CNN model with an augmented dataset containing close to 200,000 synthetic faces. We used a snapshot of this trained CNN to recognize extremely challenging frontal (real) face images. Experiments showed training with the augmented faces boosted the face recognition performance of the CNN.
The ND-IRIS-0405 Iris Image Dataset
Jun 15, 2016



The Computer Vision Research Lab at the University of Notre Dame began collecting iris images in the spring semester of 2004. The initial data collections used an LG 2200 iris imaging system for image acquisition. Image datasets acquired in 2004-2005 at Notre Dame with this LG 2200 have been used in the ICE 2005 and ICE 2006 iris biometric evaluations. The ICE 2005 iris image dataset has been distributed to over 100 research groups around the world. The purpose of this document is to describe the content of the ND-IRIS-0405 iris image dataset. This dataset is a superset of the iris image datasets used in ICE 2005 and ICE 2006. The ND 2004-2005 iris image dataset contains 64,980 images corresponding to 356 unique subjects, and 712 unique irises. The age range of the subjects is 18 to 75 years old. 158 of the subjects are female, and 198 are male. 250 of the subjects are Caucasian, 82 are Asian, and 24 are other ethnicities.