 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Model's Focus Improves Performance of Deep Learning-Based Synthetic Face Detectors
Paper and Code
Mar 01, 2023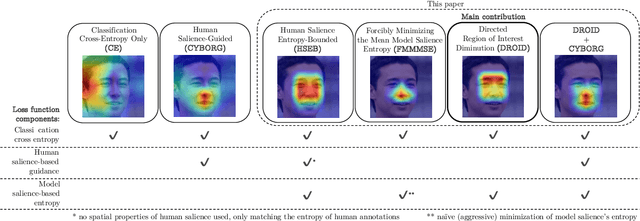
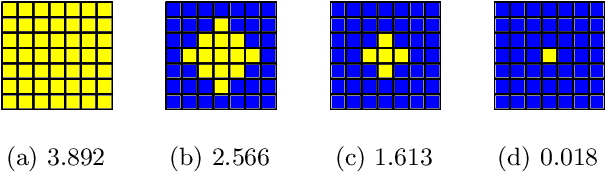
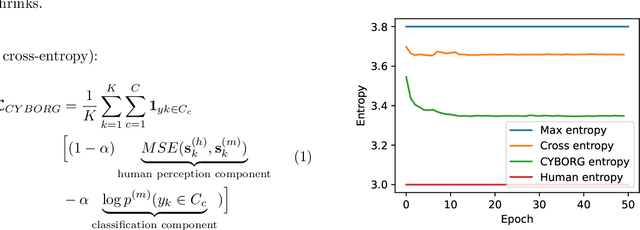

Deep learning-based models generalize better to unknown data samples after being guided "where to look" by incorporating human perception into training strategies. We made an observation that the entropy of the model's salience trained in that way is lower when compared to salience entropy computed for models training without human perceptual intelligence. Thus the question: does further increase of model's focus, by lowering the entropy of model's class activation map, help in further increasing the performance? In this paper we propose and evaluate several entropy-based new loss function components controlling the model's focus, covering the full range of the level of such control, from none to its "aggressive" minimization. We show, using a problem of synthetic face detection, that improving the model's focus, through lowering entropy, leads to models that perform better in an open-set scenario, in which the test samples are synthesized by unknown generative models. We also show that optimal performance is obtained when the model's loss function blends three aspects: regular classification, low-entropy of the model's focus, and human-guided saliency.