 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLowering the Barrier to IREX Participation: Open-Source Algorithms, Toolkit, and Benchmarking for Iris Recognition
May 20, 2026This paper proposes two new open-source iris recognition algorithms, providing both Python and IREX-compliant C++ implementations to be submitted to the official IREX X program. This work has two primary goals: (a) to conduct the first-ever assessment of open-source iris recognition solutions according to IREX testing protocols, and (b) to offer a model C++ submission that significantly facilitates the entry of other teams' open-source methods into the IREX evaluation. The new methods consist of two Neural Networks trained with: (i) Triplet loss with Batch-Hard Triplet mining (TripletIris), and (ii) ArcFace loss (ArcIris). The paper also provides open-source IREX-compliant C++ implementations of two existing methods: (a) an iris image filtering-based algorithm utilizing human saliency-driven kernels (HDBIF), and (b) a human-interpretable algorithm for detecting and comparing Fuchs' crypts (CRYPTS). Except for CRYPTS, which faced timing constraints during 1:N search, these methods have undergone the official IREX X evaluation and have also been assessed using several popular academic benchmarks: Quality-Face/Iris Research Ensemble, Warsaw-Biobase Post-Mortem Iris, CASIA-Iris-Thousand-V4, CASIA-Iris-Lamp-V4, IIT Delhi Iris Database, IIITD Contact Lens Iris Database, NDIris3D, and Notre Dame Variable Iris Image Quality Release 2. Finally, this paper also provides open-source models for iris segmentation and circle estimation that can be incorporated into any new iris recognition method.
Gradient-Guided Exploration of Generative Model's Latent Space for Controlled Iris Image Augmentations
Nov 12, 2025Developing reliable iris recognition and presentation attack detection methods requires diverse datasets that capture realistic variations in iris features and a wide spectrum of anomalies. Because of the rich texture of iris images, which spans a wide range of spatial frequencies, synthesizing same-identity iris images while controlling specific attributes remains challenging. In this work, we introduce a new iris image augmentation strategy by traversing a generative model's latent space toward latent codes that represent same-identity samples but with some desired iris image properties manipulated. The latent space traversal is guided by a gradient of specific geometrical, textural, or quality-related iris image features (e.g., sharpness, pupil size, iris size, or pupil-to-iris ratio) and preserves the identity represented by the image being manipulated. The proposed approach can be easily extended to manipulate any attribute for which a differentiable loss term can be formulated. Additionally, our approach can use either randomly generated images using either a pre-train GAN model or real-world iris images. We can utilize GAN inversion to project any given iris image into the latent space and obtain its corresponding latent code.
EyePreserve: Identity-Preserving Iris Synthesis
Dec 30, 2023



Synthesis of same-identity biometric iris images, both for existing and non-existing identities while preserving the identity across a wide range of pupil sizes, is complex due to intricate iris muscle constriction mechanism, requiring a precise model of iris non-linear texture deformations to be embedded into the synthesis pipeline. This paper presents the first method of fully data-driven, identity-preserving, pupil size-varying s ynthesis of iris images. This approach is capable of synthesizing images of irises with different pupil sizes representing non-existing identities as well as non-linearly deforming the texture of iris images of existing subjects given the segmentation mask of the target iris image. Iris recognition experiments suggest that the proposed deformation model not only preserves the identity when changing the pupil size but offers better similarity between same-identity iris samples with significant differences in pupil size, compared to state-of-the-art linear and non-linear (bio-mechanical-based) iris deformation models. Two immediate applications of the proposed approach are: (a) synthesis of, or enhancement of the existing biometric datasets for iris recognition, mimicking those acquired with iris sensors, and (b) helping forensic human experts in examining iris image pairs with significant differences in pupil dilation. Source codes and weights of the models are made available with the paper.
DeformIrisNet: An Identity-Preserving Model of Iris Texture Deformation
Jul 18, 2022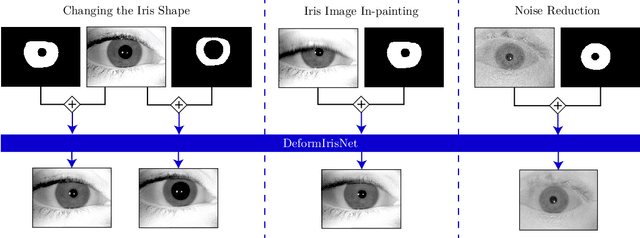
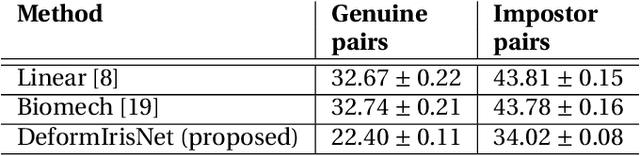
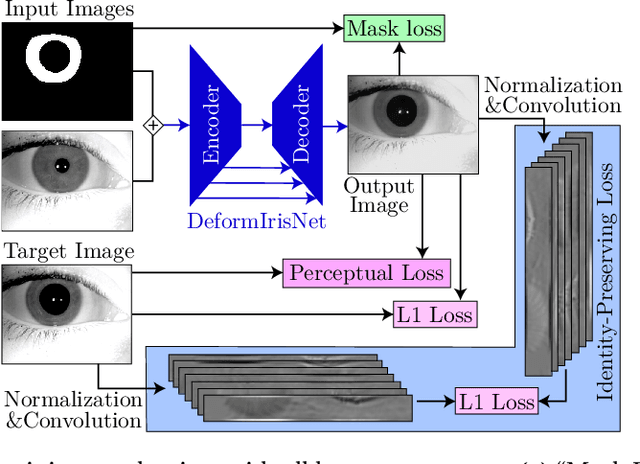
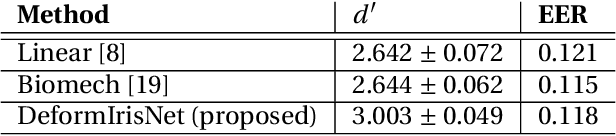
Nonlinear iris texture deformations due to pupil size variations are one of the main factors responsible for within-class variance of genuine comparison scores in iris recognition. In dominant approaches to iris recognition, the size of a ring-shaped iris region is linearly scaled to a canonical rectangle, used further in encoding and matching. However, the biological complexity of iris sphincter and dilator muscles causes the movements of iris features to be nonlinear in a function of pupil size, and not solely organized along radial paths. Alternatively to the existing theoretical models based on biomechanics of iris musculature, in this paper we propose a novel deep autoencoder-based model that can effectively learn complex movements of iris texture features directly from the data. The proposed model takes two inputs, (a) an ISO-compliant near-infrared iris image with initial pupil size, and (b) the binary mask defining the target shape of the iris. The model makes all the necessary nonlinear deformations to the iris texture to match the shape of iris in image (a) with the shape provided by the target mask (b). The identity-preservation component of the loss function helps the model in finding deformations that preserve identity and not only visual realism of generated samples. We also demonstrate two immediate applications of this model: better compensation for iris texture deformations in iris recognition algorithms, compared to linear models, and creation of generative algorithm that can aid human forensic examiners, who may need to compare iris images with large difference in pupil dilation. We offer the source codes and model weights available along with this paper.
A CNN-based approach to classify cricket bowlers based on their bowling actions
Sep 03, 2019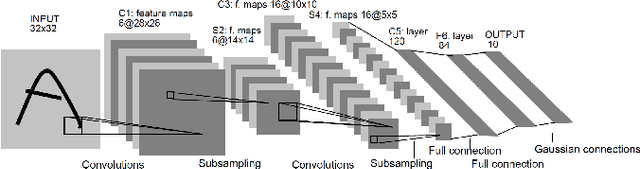
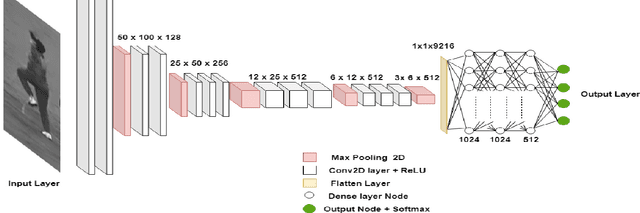


With the advances in hardware technologies and deep learning techniques, it has become feasible to apply these techniques in diverse fields. Convolutional Neural Network (CNN), an architecture from the field of deep learning, has revolutionized Computer Vision. Sports is one of the avenues in which the use of computer vision is thriving. Cricket is a complex game consisting of different types of shots, bowling actions and many other activities. Every bowler, in a game of cricket, bowls with a different bowling action. We leverage this point to identify different bowlers. In this paper, we have proposed a CNN model to identify eighteen different cricket bowlers based on their bowling actions using transfer learning. Additionally, we have created a completely new dataset containing 8100 images of these eighteen bowlers to train the proposed framework and evaluate its performance. We have used the VGG16 model pre-trained with the ImageNet dataset and added a few layers on top of it to build our model. After trying out different strategies, we found that freezing the weights for the first 14 layers of the network and training the rest of the layers works best. Our approach achieves an overall average accuracy of 93.3% on the test set and converges to a very low cross-entropy loss.
HishabNet: Detection, Localization and Calculation of Handwritten Bengali Mathematical Expressions
Sep 02, 2019
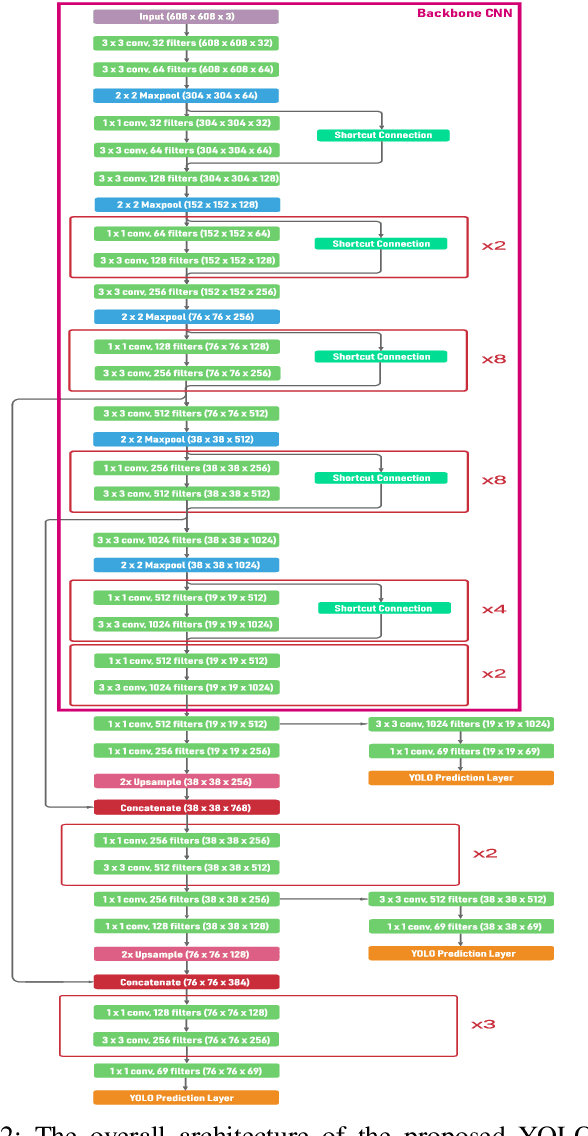

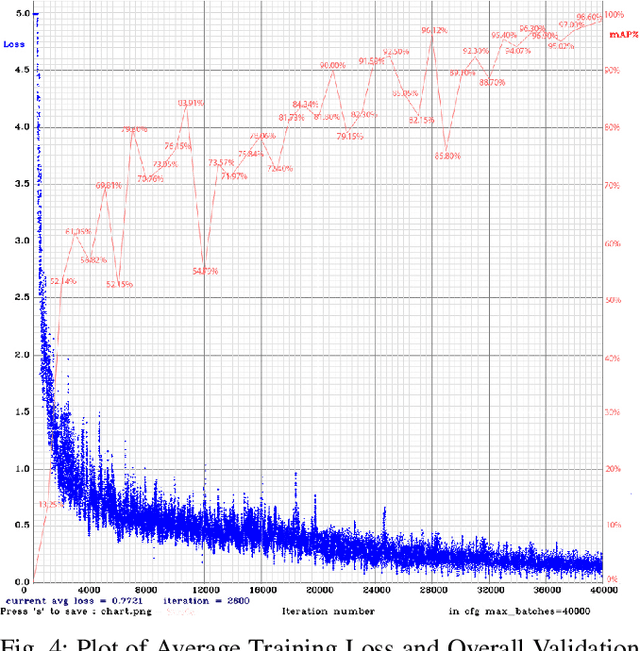
Recently, recognition of handwritten Bengali letters and digits have captured a lot of attention among the researchers of the AI community. In this work, we propose a Convolutional Neural Network (CNN) based object detection model which can recognize and evaluate handwritten Bengali mathematical expressions. This method is able to detect multiple Bengali digits and operators and locate their positions in the image. With that information, it is able to construct numbers from series of digits and perform mathematical operations on them. For the object detection task, the state-of-the-art YOLOv3 algorithm was utilized. For training and evaluating the model, we have engineered a new dataset 'Hishab' which is the first Bengali handwritten digits dataset intended for object detection. The model achieved an overall validation mean average precision (mAP) of 98.6%. Also, the classification accuracy of the feature extractor backbone CNN used in our model was tested on two publicly available Bengali handwritten digits datasets: NumtaDB and CMATERdb. The backbone CNN achieved a test set accuracy of 99.6252% on NumtaDB and 99.0833% on CMATERdb.