 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre you In or Out (of gallery)? Wisdom from the Same-Identity Crowd
Aug 08, 2025A central problem in one-to-many facial identification is that the person in the probe image may or may not have enrolled image(s) in the gallery; that is, may be In-gallery or Out-of-gallery. Past approaches to detect when a rank-one result is Out-of-gallery have mostly focused on finding a suitable threshold on the similarity score. We take a new approach, using the additional enrolled images of the identity with the rank-one result to predict if the rank-one result is In-gallery / Out-of-gallery. Given a gallery of identities and images, we generate In-gallery and Out-of-gallery training data by extracting the ranks of additional enrolled images corresponding to the rank-one identity. We then train a classifier to utilize this feature vector to predict whether a rank-one result is In-gallery or Out-of-gallery. Using two different datasets and four different matchers, we present experimental results showing that our approach is viable for mugshot quality probe images, and also, importantly, for probes degraded by blur, reduced resolution, atmospheric turbulence and sunglasses. We also analyze results across demographic groups, and show that In-gallery / Out-of-gallery classification accuracy is similar across demographics. Our approach has the potential to provide an objective estimate of whether a one-to-many facial identification is Out-of-gallery, and thereby to reduce false positive identifications, wrongful arrests, and wasted investigative time. Interestingly, comparing the results of older deep CNN-based face matchers with newer ones suggests that the effectiveness of our Out-of-gallery detection approach emerges only with matchers trained using advanced margin-based loss functions.
Peepers & Pixels: Human Recognition Accuracy on Low Resolution Faces
Mar 25, 2025

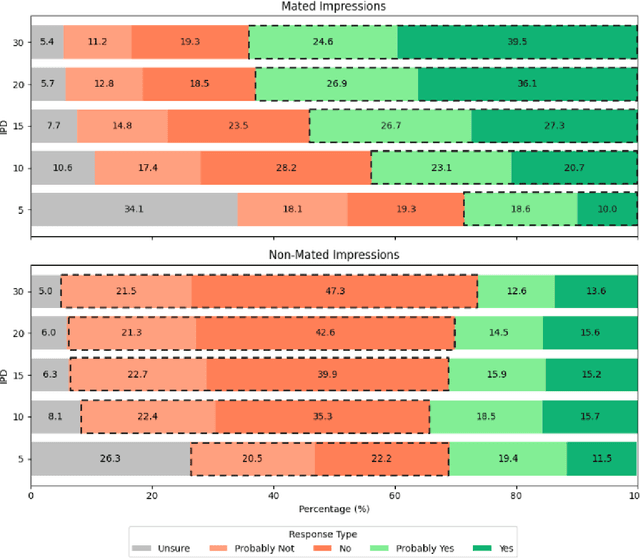
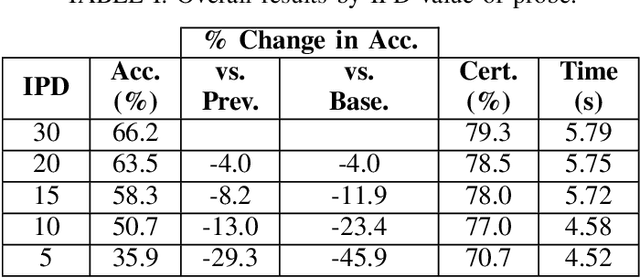
Automated one-to-many (1:N) face recognition is a powerful investigative tool commonly used by law enforcement agencies. In this context, potential matches resulting from automated 1:N recognition are reviewed by human examiners prior to possible use as investigative leads. While automated 1:N recognition can achieve near-perfect accuracy under ideal imaging conditions, operational scenarios may necessitate the use of surveillance imagery, which is often degraded in various quality dimensions. One important quality dimension is image resolution, typically quantified by the number of pixels on the face. The common metric for this is inter-pupillary distance (IPD), which measures the number of pixels between the pupils. Low IPD is known to degrade the accuracy of automated face recognition. However, the threshold IPD for reliability in human face recognition remains undefined. This study aims to explore the boundaries of human recognition accuracy by systematically testing accuracy across a range of IPD values. We find that at low IPDs (10px, 5px), human accuracy is at or below chance levels (50.7%, 35.9%), even as confidence in decision-making remains relatively high (77%, 70.7%). Our findings indicate that, for low IPD images, human recognition ability could be a limiting factor to overall system accuracy.
Lights, Camera, Matching: The Role of Image Illumination in Fair Face Recognition
Jan 15, 2025



Facial brightness is a key image quality factor impacting face recognition accuracy differentials across demographic groups. In this work, we aim to decrease the accuracy gap between the similarity score distributions for Caucasian and African American female mated image pairs, as measured by d' between distributions. To balance brightness across demographic groups, we conduct three experiments, interpreting brightness in the face skin region either as median pixel value or as the distribution of pixel values. Balancing based on median brightness alone yields up to a 46.8% decrease in d', while balancing based on brightness distribution yields up to a 57.6% decrease. In all three cases, the similarity scores of the individual distributions improve, with mean scores maximally improving 5.9% for Caucasian females and 3.7% for African American females.
Impact of Sunglasses on One-to-Many Facial Identification Accuracy
Dec 07, 2024



One-to-many facial identification is documented to achieve high accuracy in the case where both the probe and the gallery are `mugshot quality' images. However, an increasing number of documented instances of wrongful arrest following one-to-many facial identification have raised questions about its accuracy. Probe images used in one-to-many facial identification are often cropped from frames of surveillance video and deviate from `mugshot quality' in various ways. This paper systematically explores how the accuracy of one-to-many facial identification is degraded by the person in the probe image choosing to wear dark sunglasses. We show that sunglasses degrade accuracy for mugshot-quality images by an amount similar to strong blur or noticeably lower resolution. Further, we demonstrate that the combination of sunglasses with blur or lower resolution results in even more pronounced loss in accuracy. These results have important implications for developing objective criteria to qualify a probe image for the level of accuracy to be expected if it used for one-to-many identification. To ameliorate the accuracy degradation caused by dark sunglasses, we show that it is possible to recover about 38% of the lost accuracy by synthetically adding sunglasses to all the gallery images, without model re-training. We also show that increasing the representation of wearing-sunglasses images in the training set can largely reduce the error rate. The image set assembled for this research will be made available to support replication and further research into this problem.
What is a Goldilocks Face Verification Test Set?
May 24, 2024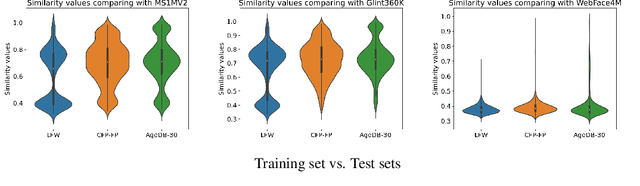
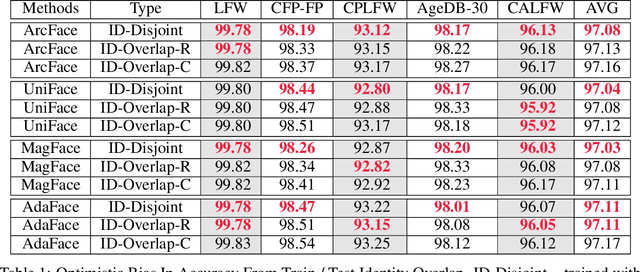


Face Recognition models are commonly trained with web-scraped datasets containing millions of images and evaluated on test sets emphasizing pose, age and mixed attributes. With train and test sets both assembled from web-scraped images, it is critical to ensure disjoint sets of identities between train and test sets. However, existing train and test sets have not considered this. Moreover, as accuracy levels become saturated, such as LFW $>99.8\%$, more challenging test sets are needed. We show that current train and test sets are generally not identity- or even image-disjoint, and that this results in an optimistic bias in the estimated accuracy. In addition, we show that identity-disjoint folds are important in the 10-fold cross-validation estimate of test accuracy. To better support continued advances in face recognition, we introduce two "Goldilocks" test sets, Hadrian and Eclipse. The former emphasizes challenging facial hairstyles and latter emphasizes challenging over- and under-exposure conditions. Images in both datasets are from a large, controlled-acquisition (not web-scraped) dataset, so they are identity- and image-disjoint with all popular training sets. Accuracy for these new test sets generally falls below that observed on LFW, CPLFW, CALFW, CFP-FP and AgeDB-30, showing that these datasets represent important dimensions for improvement of face recognition. The datasets are available at: \url{https://github.com/HaiyuWu/SOTA-Face-Recognition-Train-and-Test}
Analysis of Adversarial Image Manipulations
May 10, 2023



As virtual and physical identity grow increasingly intertwined, the importance of privacy and security in the online sphere becomes paramount. In recent years, multiple news stories have emerged of private companies scraping web content and doing research with or selling the data. Images uploaded online can be scraped without users' consent or knowledge. Users of social media platforms whose images are scraped may be at risk of being identified in other uploaded images or in real-world identification situations. This paper investigates how simple, accessible image manipulation techniques affect the accuracy of facial recognition software in identifying an individual's various face images based on one unique image.
Exploring Causes of Demographic Variations In Face Recognition Accuracy
Apr 14, 2023In recent years, media reports have called out bias and racism in face recognition technology. We review experimental results exploring several speculated causes for asymmetric cross-demographic performance. We consider accuracy differences as represented by variations in non-mated (impostor) and / or mated (genuine) distributions for 1-to-1 face matching. Possible causes explored include differences in skin tone, face size and shape, imbalance in number of identities and images in the training data, and amount of face visible in the test data ("face pixels"). We find that demographic differences in face pixel information of the test images appear to most directly impact the resultant differences in face recognition accuracy.
Consistency and Accuracy of CelebA Attribute Values
Oct 13, 2022
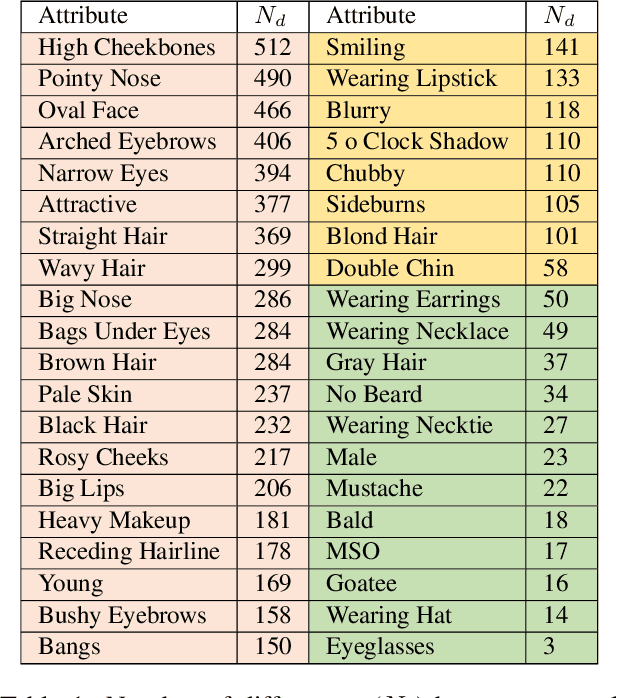

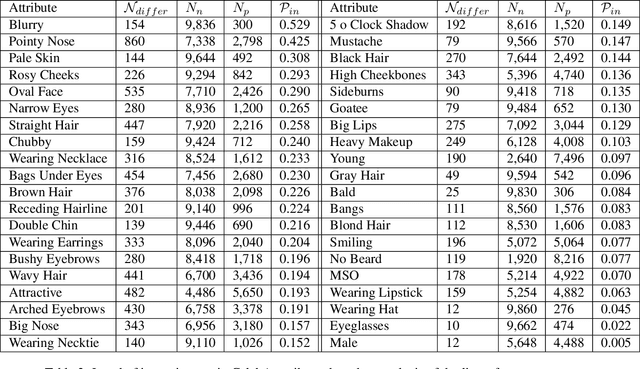
We report the first analysis of the experimental foundations of facial attribute classification. An experiment with two annotators independently assigning values shows that only 12 of 40 commonly-used attributes are assigned values with >= 95% consistency, and that three (high cheekbones, pointed nose, oval face) have random consistency (50%). These results show that the binary face attributes currently used in this research area could re-focused to be more objective. We identify 5,068 duplicate face appearances in CelebA, the most widely used dataset in this research area, and find that individual attributes have contradicting values on from 10 to 860 of 5,068 duplicates. Manual audit of a subset of CelebA estimates error rates as high as 40% for (no beard=false), even though the labeling consistency experiment indicates that no beard could be assigned with >= 95% consistency. Selecting the mouth slightly open (MSO) attribute for deeper analysis, we estimate the error rate for (MSO=true) at about 20% and for (MSO=false) at about 2%. We create a corrected version of the MSO attribute values, and compare classification models created using the original versus corrected values. The corrected values enable a model that achieves higher accuracy than has been previously reported for MSO. Also, ScoreCAM visualizations show that the model created using the corrected attribute values is in fact more focused on the mouth region of the face. These results show that the error rate in the current CelebA attribute values should be reduced in order to enable learning of better models. The corrected attribute values for CelebA's MSO and the CelebA facial hair attributes will be made available upon publication.
The Gender Gap in Face Recognition Accuracy Is a Hairy Problem
Jun 10, 2022

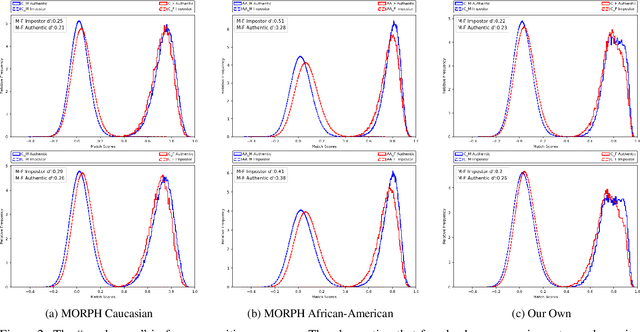
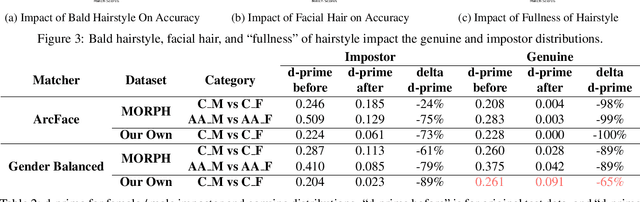
It is broadly accepted that there is a "gender gap" in face recognition accuracy, with females having higher false match and false non-match rates. However, relatively little is known about the cause(s) of this gender gap. Even the recent NIST report on demographic effects lists "analyze cause and effect" under "what we did not do". We first demonstrate that female and male hairstyles have important differences that impact face recognition accuracy. In particular, compared to females, male facial hair contributes to creating a greater average difference in appearance between different male faces. We then demonstrate that when the data used to estimate recognition accuracy is balanced across gender for how hairstyles occlude the face, the initially observed gender gap in accuracy largely disappears. We show this result for two different matchers, and analyzing images of Caucasians and of African-Americans. These results suggest that future research on demographic variation in accuracy should include a check for balanced quality of the test data as part of the problem formulation. To promote reproducible research, matchers, attribute classifiers, and datasets used in this research are/will be publicly available.
Face Recognition Accuracy Across Demographics: Shining a Light Into the Problem
Jun 04, 2022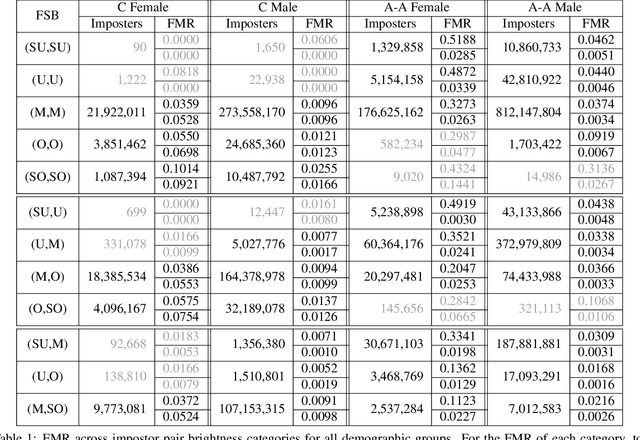

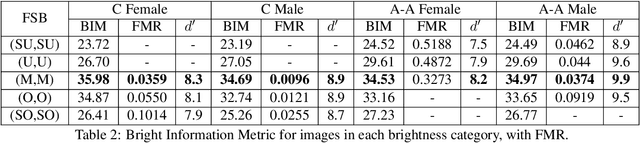
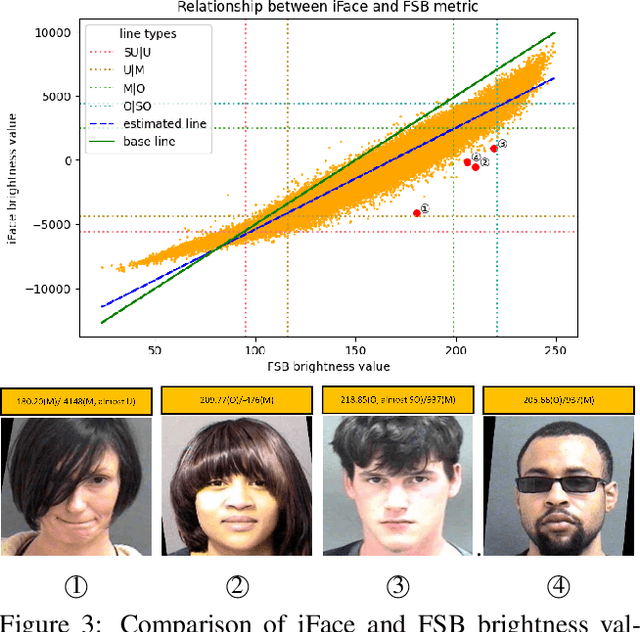
This is the first work that we are aware of to explore how the level of brightness of the skin region in a pair of face images impacts face recognition accuracy. Image pairs with both images having mean face skin brightness in an upper-middle range of brightness are found to have the highest matching accuracy across demographics and matchers. Image pairs with both images having mean face skin brightness that is too dark or too light are found to have an increased false match rate (FMR). Image pairs with strongly different face skin brightness are found to have decreased FMR and increased false non-match rate (FNMR). Using a brightness information metric that captures the variation in brightness in the face skin region, the variation in matching accuracy is shown to correlate with the level of information available in the face skin region. For operational scenarios where image acquisition is controlled, we propose acquiring images with lighting adjusted to yield face skin brightness in a narrow range.