 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistency and Accuracy of CelebA Attribute Values
Paper and Code

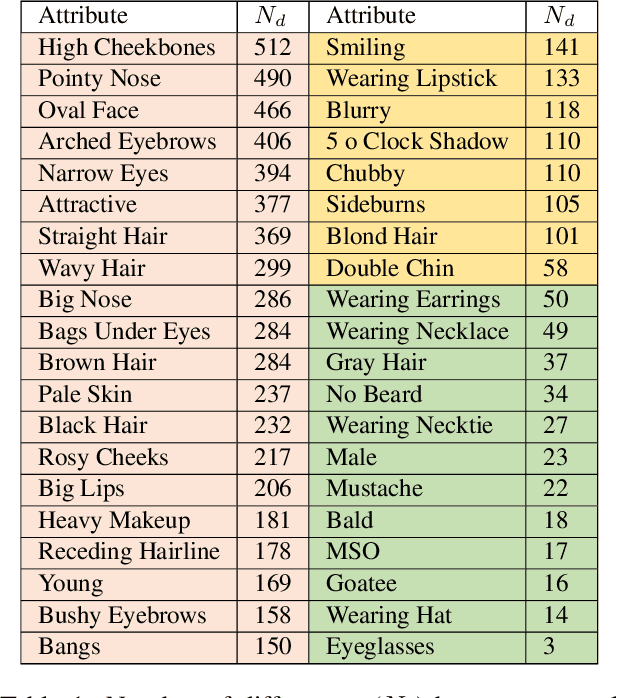

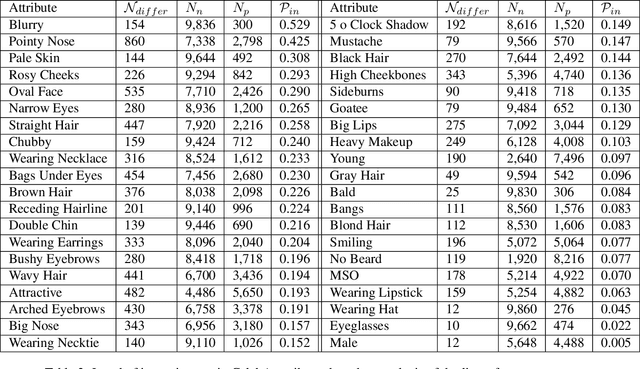
We report the first analysis of the experimental foundations of facial attribute classification. An experiment with two annotators independently assigning values shows that only 12 of 40 commonly-used attributes are assigned values with >= 95% consistency, and that three (high cheekbones, pointed nose, oval face) have random consistency (50%). These results show that the binary face attributes currently used in this research area could re-focused to be more objective. We identify 5,068 duplicate face appearances in CelebA, the most widely used dataset in this research area, and find that individual attributes have contradicting values on from 10 to 860 of 5,068 duplicates. Manual audit of a subset of CelebA estimates error rates as high as 40% for (no beard=false), even though the labeling consistency experiment indicates that no beard could be assigned with >= 95% consistency. Selecting the mouth slightly open (MSO) attribute for deeper analysis, we estimate the error rate for (MSO=true) at about 20% and for (MSO=false) at about 2%. We create a corrected version of the MSO attribute values, and compare classification models created using the original versus corrected values. The corrected values enable a model that achieves higher accuracy than has been previously reported for MSO. Also, ScoreCAM visualizations show that the model created using the corrected attribute values is in fact more focused on the mouth region of the face. These results show that the error rate in the current CelebA attribute values should be reduced in order to enable learning of better models. The corrected attribute values for CelebA's MSO and the CelebA facial hair attributes will be made available upon publication.